






Feedback
Last date modified: 2026-Jun-01
aiR for Data Breach Response
aiR for Data Breach Response is generally available as of 02/26/2026. To view legacy mode, see Data Breach Response (Legacy).
aiR for Data Breach Response is a Relativity product purpose-built to support and help streamline the process of identifying, extracting, and linking Personal Information (PI) and Personal Health Information (PHI) to the relevant individual or organization, and generating a consolidated list of potentially impacted individuals using generative artificial intelligence (AI).
aiR for Data Breach Response is available as a Relativity application (RAP). You can install the application into a RelativityOne Review workspace that runs within a RelativityOne production environment. (The data used for analysis never leaves the RelativityOne security boundary, which aligns with security and compliance requirements defined in RelativityOne contracts.)
- Input—Documents identified by a Saved Search to be analyzed by aiR for Data Breach Response
- Output—A notification report containing impacted individuals and their associated PI or PHI
See these related resources for more information:
- A Focus on Security and Privacy in Relativity’s Approach to Generative AI
- Six characteristics of Generative AI and their impact on aiR products
- Relativity aiR Ask the Expert: Generative AI Fundamentals in Relativity
Conceptual workflow
The steps below illustrate high level workflow steps for the aiR for Data Breach Response product
- Upload and process documents in your RelativityOne environment.
- Configure the aiR for Data Breach Response application into your environment and review workspace.
- Start a new Data Breach ingestion job and select the saved search of documents for review.
- Go to Settings and select PI and PHI detectors you want to use. Add any custom detectors.
- Navigate to the Data Analysis tab and run Data Analysis. As PI detection completes, you can view insights on identified, extracted, and linked PI and begin reviewing documents. Access documents on the project dashboard as they become available during processing. If you run the normalizer step, the application automatically generates the entity report.
- Access the Project Dashboard to view PI and PHI identification, extraction, linking, and any document errors across the document set.
- Review the Entity Analysis tab to resolve conflicts and review and finalize your desired output.
Document requirements
Following are document requirements for aiR for Data Breach Response:
- aiR for Data Breach Response can support up to 300M PI annotations and 150M entities, represented across 1 TB of native data in an aiR for Data Breach Response workspace.A document quota applies to each aiR for Data Breach Response workspace to help ensure optimal analysis performance. This is tracked in the Ingestion tab. You can process a larger volume of documents by running them in increments, scaling up until you reach the full quota available.
- aiR for Data Breach Response analyzes only extracted text. The application does not consider information contained in metadata, images, or other non-text elements.You can OCR in RelativityOne. See OCR for instructions.
- The following document types are not supported:
- Documents that open with an error or warning
- Excel files older than Excel 95 (v 7.0)
- Native spreadsheets greater than 40MB native size
- Native non-spreadsheets greater than 75MB native or 10MB extracted text size
Unstructured and Structured documents
aiR for Data Breach Response categorizes documents as either Unstructured or Structured. aiR for Data Breach Response leverages different AI-based methods to deliver the most efficient process for each type of document.
- Unstructured documents—contain unlabeled or otherwise unorganized data. The content on the files are usually composed of natural language. Examples of unstructured documents include text-based documents such as emails, word processing documents, and forms with additional unstructured data sources such as photos, and audio files. aiR for Data Breach Response uses document context to help differentiate between types of PI. aiR can automatically identify and link potential PI across unstructured documents, which may help accelerate review and quality control processes. aiR for Data Breach Response also normalizes entities across documents and generates a consolidated notification list for review, supporting efforts to meet mandated response timelines.
To review Unstructured documents, see Unstructured document review. - Structured documents—contain data that is organized in a specific and predefined way, typically in a table with columns and rows where each data point has a specific data type. Examples of structured documents include spreadsheets and CSV files. aiR for Data Breach Response identifies table boundaries and analyzes header and column content to help predict potential PI. For structured documents, the workflow relies on table detection and analysis of column headers and values to support more consistent extraction.
To review Structured documents, see Structured document review.
Supported file types
The following types of structured and unstructured documents are supported:
| Document type | Supported extensions | Limitations and notes |
|---|---|---|
| Unstructured documents |
.ppt, .pptx, .pptm, .doc, .docx , .txt , .eml, .msg, .mht, .svg, .pdf, .fdf, .xfdf, .pub, .dwg, .dxf, .dgn, .rvt, .dwf, .odt, .odp, .rtf, .wpf, .bmp, .jpg, .jpeg, .png, .wmf, .emf, .gif, .hdp, .jp2, .jpc, .tif, .tiff, .xps, .oxps, .xml, .xod, .xaml, .vcf |
Embedded documents are not supported. Extracted text is leveraged for emails, so formatting may be lost.
|
| Structured documents |
.csv, .tsv, .xls, .xlsx, .xlsm, .xlt, .xltm, .xltx, .xlsb |
CSVs must be delimited by comma. No other delimiter is supported. TSVs must be delimited by tab. No other delimiter is supported. |
Considerations
aiR for Data Breach Response harnesses the power of large language models (LLM) to review documents. While these technologies are powerful, they also come with limitations. It’s important that you understand these limitations and use the product with appropriate care.
All aiR for Data Breach Response outputs should be reviewed by a human. There are known risks that the AI may:
- Omit critical information, such as Personal Information (PI) or Personal Health Information (PHI)
- Incorrectly identify non-personal data as PI
- Flag documents as containing PI when they do not—or fail to flag documents that do
- Mislabel or miscategorize data
- Fabricate PI that does not actually exist in the source document
Shared LLM resources
LLM services are integrated across various Relativity products within the operational geography/ RelOne instance. For optimal results, it is highly recommended to utilize a single AI-based tool at any given time.
Security and privacy
Azure OpenAI does not retain any data from the documents being analyzed. Data you submit for processing by Azure OpenAI is not retained beyond your organization’s instance, nor is it used to train any other generative AI models from Relativity, Microsoft, or any other third party. For more information, see the white paper A Focus on Security and Privacy in Relativity’s Approach to Generative AI.
Deployment and processing geographies
When using Relativity's AI technology, customer data may be processed outside of your designated geographic region. For more information, see Deployment and processing geographies.
Language support in aiR for Data Breach Response
aiR for Data Breach Response has been primarily tested on English-language documents. Accuracy is not guaranteed to be equivalent for other languages. However, the LLM is language agnostic and therefore supports global languages.
For the study used to evaluate Azure OpenAI's LLM across languages, see MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks on the arXiv website.
Running aiR for Data Breach Response
To run aiR for Data Breach Response:
- Before running the first ingestion job, navigate to Settings and make sure GenAI Mode is toggled on in your workspace.You can enable GenAI Mode only for workspaces that have never run aiR for Data Breach Response. You cannot convert existing workspaces that have already started running jobs with aiR for Data Breach Response.
- Select other settings as usual and Save.
- Proceed to Data Analysis as usual and start running the processes. Generative AI will run as part of the Unstructured Detection pipeline step.
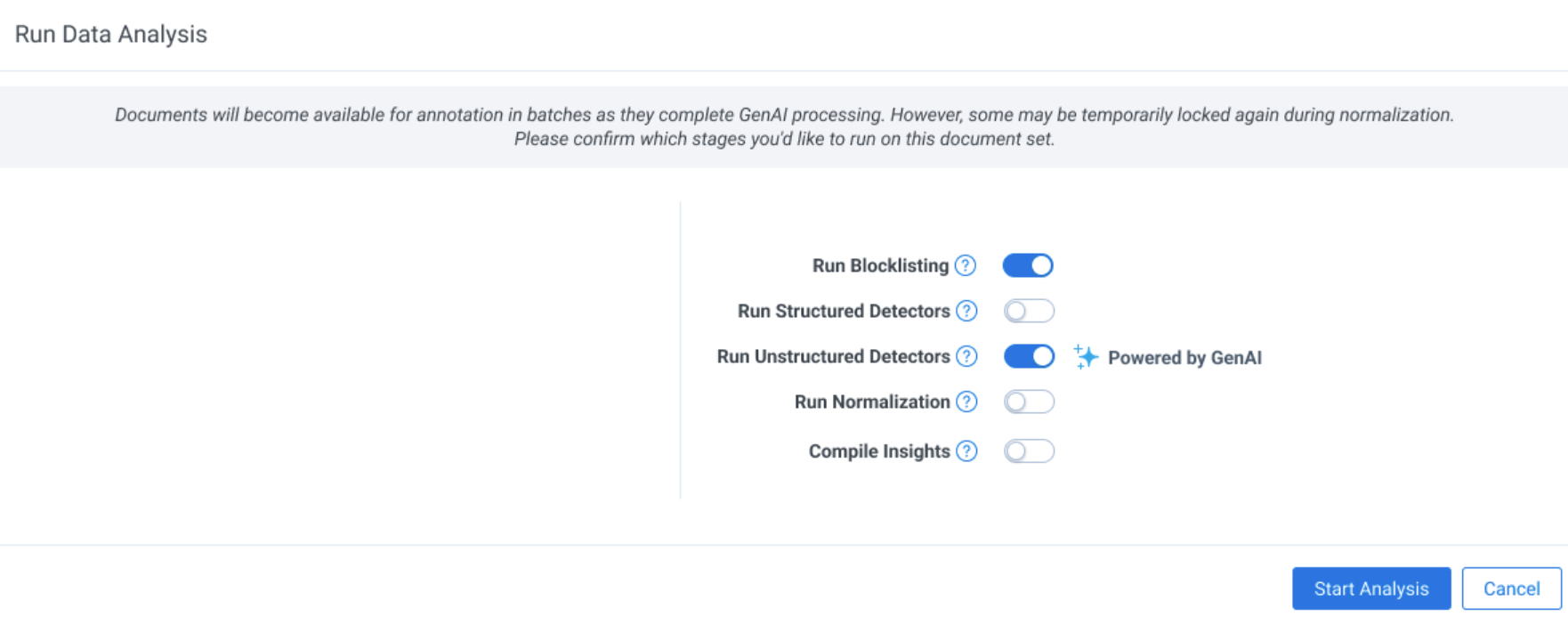
- There is a quota for how many unstructured docs can be run through aiR. This quota is listed and tracked in the Ingestion tab. See Unstructured document review for more details. Existing document size and scale limitations for structured documents apply.
- You can continue to run custom detectors as usual. Customer detectors are not currently run through aiR and therefore will not be autolinked to names as the aiR detectors are.
- In the viewer you will notice a sparkle icon for all aiR generated entities on the Linked Entities panel.
You can directly edit linked entities and PI types.
Personal Information detectors
To view a list of out of the box Personal Information detectors supported by aiR for Data Breach Response, see Supported Personal Information detectors.