






Feedback
Note: The Active Learning application is now read-only. Create new projects in Review Center.
If you have Active Learning and Review Center installed in your workspace, you can view data for previous projects on the Active Learning History tab. Please note that uninstalling Active Learning removes the project data.
For more information, see:
Active Learning is a technology assisted review tool that helps you quickly organize your data and predict which documents are most likely to be relevant to reviewers. With very little training needed to see documents of interest, Active Learning can be used for cases of all sizes, even those as small as 1,000 documents. By using Active Learning, you can reduce the total time to review.
Active Learning works by using a technology called Support Vector Machine learning to continuously learn from your reviewers' coding decisions. Reviewers code documents using a binary classification system. For example, Relevant and Not Relevant. These coding decisions are ingested by the Active Learning model where machine learning takes place. As reviewers code, the model gets better at discerning what makes a document Relevant or Not Relevant and serves the best documents to reviewers. Active Learning provides two methods of review, making it flexible to your case needs:
- Prioritized Review—finds the documents most likely to be relevant to reviewers.
- Coverage Review—quickly separates your document into your two categories.
There are a number of tools available to help you monitor the progress of your review and eventually validate the success of Active Learning. For details on estimating recall in an Active Learning project, see Project Validation and Elusion Testing.
See these related pages:
- Creating an Active Learning project
- Choosing an Active Learning review queue
- Reviewer access
- Monitoring an Active Learning project
- Project Validation and Elusion Testing
- Security permissions
- Active Learning performance baselines
- Scaling Active Learning
Terminology in Active Learning
Different jurisdictions use different terminology to refer to documents that meet the criteria to be considered a positive selection during review. "Relevant" and "responsive" are both commonly used terms for these documents. Depending on how your project is set up, you may see either of these terms or another term in the Active Learning interface. For example, the <Positive Choice> Cutoff field may appear as the Relevant Cutoff, Responsive Cutoff, or something else.
Basic Active Learning workflow
The following graphic and corresponding steps depict a typical Active Learning workflow that integrates with other Analytics features. Note that each user's workflow may vary. You may not be required to follow all of these steps for every Active Learning project you run.
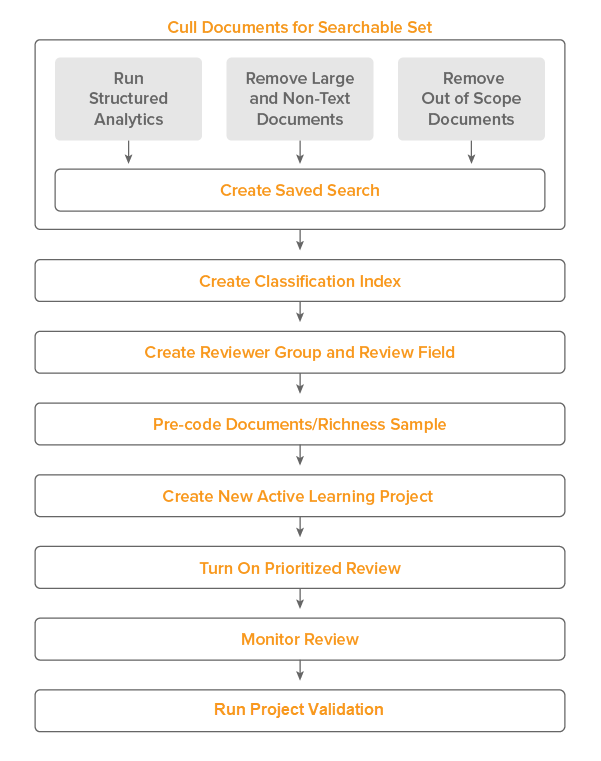
- Cull the documents you plan on using in the data source for your Active Learning project. This may include:
- Running the following
- Email Threading
- Textual Near Duplicate Identification
- (Optional) Language Identification
- Removing large and non-text documents.
- Removing documents that are out-of-scope for your case.
- Running the following
- Create a saved search using the documents you identified.Note: Return only extracted text in the search.
- Create an Analytics classification index using this saved search as the data source.
- Create a review field with at least two choices available on the coding layout to be used by the reviewer group accessing the Active Learning project.
- Pre-code documents in the data source on the review field by taking a richness sample. Aim for a balance of documents coded on the positive designation and the negative designation. Pre-coding documents by estimating richness helps speed up the Active Learning process and gives you a starting metric to gauge the progress of your Active Learning project later.
- Create a new Active Learning project.
- Turn on the Prioritized Review queue or Coverage Review queue, depending on your workflow. Have reviewers begin coding documents in the review queue.
- Monitor the review queue.
- Run Project Validation to validate the results of your project.
Note: For information on creating dashboards to help monitor your queue, see Quality checks and checking for conflicts.