






Feedback
Monitoring an Active Learning project
Note: The Active Learning application is now read-only. Create new projects in Review Center.
If you have Active Learning and Review Center installed in your workspace, you can view data for previous projects on the Active Learning History tab. Please note that uninstalling Active Learning removes the project data.
For more information, see:
The actual Active Learning process takes place using a combination of time and detection of new coding decisions. The Active Learning model starts its first build after at least five documents have been coded with the positive choice and five have been coded with the negative choice. After that build finishes, a project being actively coded in the queue will rebuild the model every 20 minutes after the previous build. This rebuild incorporates all coding decisions made after the last build began, and it includes any coding decisions made outside of the queue.
There are a number of ways to monitor the progress of an Active Learning project using tools on the Project Home and Review Statistics tabs.
Note: Each time an admin accesses the Project Home page - via a page refresh or from a different page - the latest data will reflect in the Project Home display.
See these related pages:
Project Home dashboard
The Project Home dashboard gives a high-level overview of the documents in your Active Learning project. After you first create the project, the dashboard displays the Project Size and coding statistics based on the pre-coded documents in your data source, if they exist.
Use the Project Home dashboard to understand the following:
- How many documents have been coded in your project.
- How many documents have been coded outside the queue (manually-selected documents).
- How many documents have been coded neutral or skipped.
The project home dashboard contains the following statistics:
- Project Size - the number of documents in the project. This count reflects the documents successfully indexed. Documents that were removed during the index build are excluded from this count.
- Coded [Positive Choice] - the number of documents coded with the positive designation on the review field. This count includes documents coded in the review queue and manually-selected documents. These documents are used to teach the model.
- Positive Choice manually-selected - the number of documents that were coded on the positive choice designation field outside of the review queue.
- Coded [Negative Choice] - the number of documents coded with the negative designation in the review field. This count includes documents coded in the review queue and manually-selected documents. These documents are used to teach the model.
- Negative Choice manually-selected - the number of documents that were coded on the negative choice designation field outside of the review queue.
- Coded Neutral - the number of documents that were coded with one of the neutral choices on the review field. This count includes documents coded in the review queue and manually-selected documents. These documents are not used to teach the model.
- Skipped - the number of documents served to a reviewer that weren't coded by an end reviewer.
Note: If a coding decision is updated on a document reviewed in the queue, it will not change to a manually selected document.
Update ranks
In the top-right corner of the Project Home, you'll see several icons. The first icon is the Update Ranks icon . You can use Update Ranks to manually update the document ranks and ensure the rank categorization field is up to date. Click edit to update the <Positive Choice> cutoff value. Note that updating ranks doesn't change the coding decision on the document.
. You can use Update Ranks to manually update the document ranks and ensure the rank categorization field is up to date. Click edit to update the <Positive Choice> cutoff value. Note that updating ranks doesn't change the coding decision on the document.
Note: When you update the <Positive Choice> Cutoff value, the value is updated in all three places where it’s used in the application: Project Validation, Update Ranks, and Project Settings.
Active Learning ranks all documents from 100 (most likely to be in the positive category) to 0 (most likely to be in the negative category). These document ranks drive the Prioritized Review and Coverage Review queue logic, but they can also be imported into the Document object for other workflows. For instance, you could batch out to reviewers all documents above a certain rank. Because it is a SQL-intensive operation, ranks are only stored on the document object on demand. Since ranks change, at least slightly, with each model build, a project administrator can choose to update these ranks on demand.
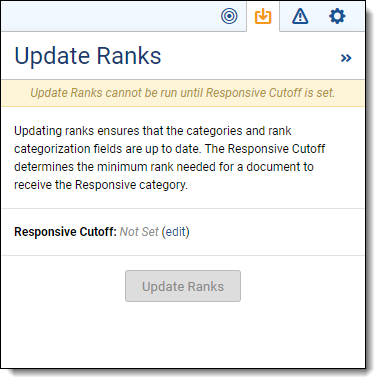
In order to update ranks, you must specify the <Positive Choice> Cutoff. This value determines the minimum rank needed for a document to be predicted as responsive. You can look at the Document Rank Distribution chart to visualize how this will categorize your documents. Every document on or above the rank cutoff (to the right when looking at the Document Rank Distribution chart) receives the positive prediction, such as "responsive," while everything below the rank cutoff (to the left) receives the negative or "non-responsive" prediction. Note that this predictive categorization is not the same as the coding decision on the document.
Note: When you update the <Positive Choice> Cutoff value, the value is updated in all three places where it’s used in the application: Project Validation, Update Ranks, and Project Settings.
Clicking Update Ranks for the first time creates the following fields:
- Categories - <Project Name> Cat. Set - the positive or negative choice based on the <Positive Choice> Cutoff value. Documents below the cutoff are automatically given the negative choice category.
- CSR - <Project Name> Cat. Set::Category Rank - the rank score, on a scale from 0 to 100, from the last time update ranks was run.
- CSR - <Project Name> Cat. Set::Category Name - the positive or negative choice based on the <Positive Choice> Cutoff value. Documents below the cutoff are automatically given the negative choice category. Note: The values in the rank categorization fields are distinct from the coding decision on the document. For example, a document may be coded not responsive, but if the rank is at or above the <Positive Choice> Cutoff value, it is categorized as responsive.
The next time you update ranks, these fields are populated with the most up-to-date rank and category information. For more information on how to use these fields, see Quality checks and checking for conflicts.
While updating ranks, the Update Ranks icon displays a small clock icon in the corner. If you click the icon to open the fly-out modal, you can view the update progress. You can update ranks again only after the current update is complete.
Running a search on a classification index
If you don't want to run Update Ranks, you can instead run a search against a classification index to quickly return documents of a certain rank or within a range of ranks.
Notes:
- If you try running a search for the first time while the classification index is populating and building, the search will try to complete for five minutes. If the index hasn't finished building within this time, the search will fail. However, you can re-run the search after the index finishes.
- If you've previously run the search, these results are cached. If you try re-running the search while the classification index is building, you'll see these old, cached results. Once the index build completes, the results are refreshed with the latest index build results.
- Navigate to the Documents tab.
- From the search bar, select the classification index associated with your Active Learning project.Note: The index you select must be associated with an Active Learning project that has been built (at least five documents coded with the positive designation and five coded with the negative designation).
- Using the next drop-down, select whether to search for Greater than or equal to, Less than or equal to, Between, or Is the rank value you enter.
- Click Search.
The Rank column displays rank results relevant to your search for the most recent index build. This differs from the CSR- <Project Name> Cat. Set::Category Rank field generated by Update Ranks, which stores old results until you manually re-run.
The rank scores are rounded to two decimal places. Note that these results are temporary, and you can't run the mass operations Sum, Tally, and Average on them.
Document rank distribution
The Document Rank Distribution chart shows the number of documents at each rank, from 0 to 100, grouped by the reviewers' coding decisions on those documents. A relevance rank near zero indicates the model believes the document is more likely coded on the negative review field choice. On the other hand, a rank closer to 100 means the model believes a document is more likely to be coded on the positive review field choice.
Note: If you see a disproportionately high number of documents ranked at 50, this may indicate that you have a high number of empty documents in your project. For more information, see Troubleshooting a large group of documents ranked at 50.
Use the rank distribution chart to understand the following:
- The number of predicted relevant documents that remain for review
- The agreement between reviewers and the Active Learning model
- The number of documents the model does not understand well
The charts reports documents reviewed from the Prioritized Review or Coverage Review queue, as well as documents coded outside of the queue. In the early stages of an Active Learning project, most documents will have a relevance rank score between 40 and 60 until the model begins training. As the model learns throughout the project life cycle, the Rank Distribution chart is expected to gravitate toward 0 or 100 depending on how documents are coded on the positive choice or negative choice. Typically, a well trained model will have a large pile of documents centered around 70 or 75, and another larger pile centered around 20 or 25. Documents with scores in the 70s are very likely relevant, and documents in the 20s are very likely not relevant.
The review state of the documents are also overlaid on this distribution. Note that it is possible for a document coded on the positive choice to have a lower relevance ranking; this is because the rank is simply the model's prediction.

You can view the following colors on the chart:
- Blue (Positive Choice) - documents coded on the positive choice review field.
- Yellow (Negative Choice) - documents coded on the negative choice review field.
- Purple (Not Reviewed) - documents within the project's scope, but not yet coded. Their rank is based on the Active Learning model's predictions.
- Green (Skipped/Neutral) - documents that were skipped or coded neutral.
- Red (Suppressed Duplicates) - documents that are suppressed by the suppress duplicates setting after a textually similar document has been coded.Note: When a full population is performed, all previously identified suppressed documents are marked as "Not Reviewed" in the Document Rank Distribution chart.
You can interact with the Document Rank Distribution Chart to hide the different categories of documents to more easily view the particular categories of documents that remain in the chart. For example, to hide the Not Reviewed documents, click the Not Reviewed label on the legend. Upon clicking, the bar chart will rescale for the remaining documents.
Active Learning: Large group of documents ranked at 50
If you see a disproportionately high number of documents ranked at 50, this may indicate that you have a high number of empty documents in your project. This could be because you indexed the wrong field, or your project includes a lot of images or media files, which don't contain words. Documents without any words can't be ranked by the model, so it ranks them all at 50.
Note: Documents that consist only of words that are not present in coded documents will also not be rankable by the model.
Use the following methods to try to identify documents without text:
- Ensure the saved search you used to create the classification index returns only the extracted text field. If it doesn't, update the index and click Run, then Full to replace the previous results. Once the index is rebuilt, the model rebuilds and all documents are reclassified.
- Search for documents with zero-length text by using a field like Extracted text size. Remove these documents from your saved search by including a condition:
- Field: Extracted text size
- Operator: is greater than
- Text box: 0
- Click Run, then Full to replace the previous results.
If neither of these methods work, run Update ranks if you haven't done so recently. Then, search through the documents with rank score of 50 for other patterns. If you find legitimate reasons why documents would be empty (ex. image files whose extracted text field contains only a URL), then systematically exclude them from the saved search and incrementally populate your index.
Prioritized review progress
The Prioritized Review Progress chart tracks the model's ability to find relevant documents over time. It does this by monitoring reviewers' coding decisions on the high-ranking documents chosen by the queue. Because the Prioritized Review queue focuses on high-ranking, uncoded documents, over time it will have to serve up lower and lower ranks, which corresponds to less relevant documents.
As a general trend, you should expect to see the relevance rate decline over the course of the review. However, you may see a spike in the relevance rate if a large amount of new documents are added to the project, or if the definition of relevance changes during the course of the review.
Notes:
- This chart only updates when documents are coded within the Prioritized Review queue. If only manually-selected documents are coded, the chart won't display relevance rate data.
- The relevance rate calculation does not include family documents or documents included in the queue for index health.
- This measurement is not cumulative with regard to the entire document set.

The x-axis charts documents in groups of 200 which have been reviewed in the Prioritized Review queue. Data won't appear on the chart until at least 200 documents are coded. Once 200 documents are coded in Prioritized Review, relevance rate data appears on the chart. A new data point appears every time another 200 documents are coded.
The y-axis charts the relevance rate. This is the percentage of the highly ranked documents which are confirmed by the reviewer to be relevant.
Inactive Queue Retraining
When a project is being actively coded in the queue, the Active Learning model will check for coding activity and rebuild every 20 minutes after the previous build. When the project does not have a queue enabled, it defaults to a dormant state in which the model does not rebuild. However, this can be changed through the Inactive Queue Retraining setting.
If the Inactive Queue Retraining setting is turned on and it finds coding activity either inside or outside the queue, the inactive queue will rebuild at a chosen interval. This defaults to 2 hours when turned on, and it can be changed to any number of hours between 1 and 24. Only whole numbers are accepted. Whether the Inactive Queue Retraining setting is on or off, as well as the interval length, can be set independently for each Active Learning project.
If the system checks for coding activity and does not find any either inside or outside the queue, it will not rebuild. The model does not have any new material to learn from unless there is coding activity.
The Inactive Queue Retraining setting is located under Project Settings. For instructions on how to change it, see Viewing project settings and errors.
How Inactive Queue Retraining affects projects with inactive queues
If the Inactive Queue Retraining setting is turned on, only Active Learning projects with inactive queues will be affected. These can be categorized into three groups:
- Projects with routine coding outside the queues—these projects benefit the most from having the timer active. We recommend turning Inactive Queue Retraining on and using an interval lower than 24 hours.
- Projects with occasional coding outside the queues—these projects can benefit from occasional rebuilds, and we generally recommend a 24-hour interval. However, if the model is already stable and predicting well, you may also choose to leave the setting off.
- Projects with no other coding activity—the timer triggers a check for new coding activity, but it does not rebuild because the model does not have any new material to learn from. If a project has no coding activity at all, we recommend leaving Inactive Queue Retraining off.
If all queues in a project are inactive and Inactive Queue Retraining is turned off, a gray banner will display at the top of Project Home warning you that the model is dormant.
Reactivating the queue and mixed coding
If you have Inactive Queue Retraining turned on and reactivate the queue for that project, the timer will turn off and remain off until turned back on again. Stopping the queue does not automatically turn Inactive Queue Retraining back on.
If your reviewers are coding documents both in the queue and outside the queue, only coding in the queue will trigger the model to rebuild itself. However, all newly coded documents will be used in that rebuild, regardless of where they were coded. This includes new changes to previously coded documents.
Events that trigger a model rebuild
The Active Learning project's model starts its first build after at least five documents have been coded with the positive choice and five have been coded with the negative choice. After that build finishes, several events trigger it to rebuild and refine its predictions.
These events are:
- Coding in an active queue (rebuild occurs every 20 minutes after the previous build)
- Building the classification index connected to the Active Learning project
- Starting project validation
- Rejecting the results of project validation
- Restoring a project using the Archive, Restore, Move tool (ARM)
- Coding either inside or outside a queue when Inactive Queue Retraining is turned on for that queue
Turning on Inactive Queue Retraining triggers a check for coding activity either inside or outside the queue. If that activity exists, it rebuilds the model. This check happens again at all specified intervals until Inactive Queue Retraining is turned off.
Note: Rebuilding the model is different from updating ranks. Rebuilding the model occurs on the back end, and it recalculates the relevance scores that control which documents are served up in the queue. Updating ranks makes those scores visible to the user. It's done primarily for reporting purposes, and it does not change the scores or affect the queue.
Quality checks and checking for conflicts
We recommend running ongoing quality checks over the course of the project. The Active Learning process is fairly tolerant of some inaccurate or inconsistent coding, but it's good practice to monitor your queue for conflicts between reviewers and the Active Learning model.
Useful dashboards
You can make custom widgets and dashboards with various active learning fields. Some of the fields are created when you create your Active Learning project, while others are created the first time you update ranks. A few fields in particular may be of use to you:
- CSR - <Project Name> Cat. Set::Category Rank - the rank score, on a scale from 0 to 100, from the last time update ranks was run.
- Categories - <Project Name> Cat. Set - the positive or negative choice based on the <Positive Choice> Cutoff value from the last time update ranks was run. Documents below the cutoff are automatically given the negative choice category.
- <Project Name> Reviewers::User - the name of the reviewer who coded the document in the queue.
- <Project Name>:: Prioritized Review - the 200-document interval in which the document was reviewed in the Prioritized Review.
- <Project Name>:: Coverage Review - the 200-document interval in which the document was reviewed in the Coverage Review.
- <Project Name>:: Project Validation - the Project Validation in which the document was reviewed.
Review field coding
This widget tracks documents manually coded by reviewers.
Note: For this example we have created a field named AL Designation. In your workspace this might be named Responsive, Relevance, or something else.

To create this widget, complete the following:
- From the Documents tab, click Add Widget.
- Select Pivot.
- Complete the following fields:
- Group By (X): AL Designation
- Group By Results Returned: All
- Pivot On (Y): <Grand Total>
- Sort On: <Grand Total> (Descending)
- Select Pie Chart as the default display type.
- Click Add Pivot.
As an optional step, you can also set the widget to show documents that have not yet been coded:
- After adding the pivot, click the
 icon at the top right of the Pivot widget to display the Pivot options pane.
icon at the top right of the Pivot widget to display the Pivot options pane. - Check the box next to Show (blank).
Active Learning Results Summary
This widget will help you understand the system identified responsiveness.
To create this widget, complete the following:
- From the Documents tab, click Add Widget.
- Select Pivot.
- Complete the following fields:
- Group By (X): Categories - Active Learning Project Cat. Set
- Group By Results Returned: All
- Pivot On (Y): <Grand Total>
- Sort On: <Grand Total> (Descending)
- Select Pie Chart as the default display type.
- Click Add Pivot.
Machine Classification against Coding Values
This widget compares the human coding values against Active Learning classification.

To create this widget, complete the following:
- From the Documents tab, click Add Widget.
- Select Pivot.
- Complete the following fields:
- Group By (X): CSR - Active Learning Project Cat. Set::Category Rank
- Group By Results Returned: All
- Pivot On (Y): AL Designation
- Pivot On Results Returned: All
- Sort On: CSR - Active Learning Project Cat. Set::Category Rank (Ascending)
- Select Stacked Bar Chart as the default display type.
- Click Add Pivot.
- After adding the pivot, click the icon at the top right of the Pivot widget to display the Pivot options pane.
- Enable the following options:
- Show (blank)
- Vertical Orientation
Notes:
This chart looks similar to the document rank distribution chart on the Active Learning project homepage, with the following differences:
- The colors for responsives and non-responsives may be different from the document rank distribution chart.
- Any suppressed duplicates appear together with the rest of the uncoded documents.
- The ranks do not update automatically. They will only refresh when you run Update Ranks from the project homepage.
User Coding Tracker
This widget will show the number of documents coded per reviewer. This is handy to understand who is coding what and track progress.
![]()
To create this widget, complete the following:
- From the Documents tab, click Add Widget.
- Select Pivot.
- Complete the following fields:
- Group By (X): Active Learning Project Reviewers::User
- Group By Results Returned: All
- Pivot On (Y): <Grand Total>
- Sort On: <Grand Total> (Descending)
- Default Display Type: Bar Chart
- Select Bar Chart as the default display type.
- Click Add Pivot.
- After adding the pivot, click the icon at the top right of the Pivot widget to display the Pivot options pane.
- Select Horizontal Orientation.
Using these widgets
After creating these widgets, use the following workflows:
- Check for conflicts by doing the following:
- Select the Responsive items coded by reviewers. Select the Non Responsive classified items. Consult the Reviewers::User widget to see who coded these documents if they were coded in a queue. Note: These are documents that Active Learning is predicting as non-responsive, but the reviewer has coded as responsive. While such conflicts usually cannot be eliminated entirely, too many of them could be a sign of reviewer inconsistency, not coding on the "four corners" of the document, or a saved search for the index which returns something other than the extracted text field.
- Select the Non-Responsive items coded by reviewers. Select the Responsive classified items. Consult the Reviewers::User widget to see who coded these documents if they were coded in a queue.Note: These are documents that Active Learning is predicting as responsive, but the reviewer has coded as non-responsive. While such conflicts usually cannot be eliminated entirely, too many of them could be a sign of reviewer inconsistency, not coding on the "four corners" of the document, or a saved search for the index which returns something other than the extracted text field.
- Run a search for documents Greater than or equal to your rank cutoff. Then, filter on the Designation field to return documents within this rank that were coded on the negative designation.
- Select the Responsive items coded by reviewers. Select the Non Responsive classified items. Consult the Reviewers::User widget to see who coded these documents if they were coded in a queue.
- Select a reviewer. See how the coding values change to understand how the coding breakdown occurs per person. See if someone is coding a much higher or lower percentage compared to other users.
Determining when a project is done
When the project is nearing completion, it can become more difficult to find additional relevant documents. As you monitor your project, here are some tips for determining when a project is done:
- Document rank distribution - look for few or no purple bars (Not Reviewed) over the 50 mark for relevance.
- Prioritized review progress - you should see a decline in the prioritized review progress line chart indicating that very few responsive documents are being found.
- Richness - if you estimated richness at the start of your project, you have a rough estimate of how many relevant documents are in your project. The number of documents coded relevant should be close to the richness estimate when the project is done.
Once you believe you are near the end of your project, you can run Project Validation to confirm the state of the project. For more information, see Project Validation and Elusion Testing.