






Feedback
Scaling Active Learning
Running Active Learning across tens of millions of documents
Relativity's Active Learning testing reveals that rebuild times get impractically slow in the 9 to 10 million document range. Here, we describe a workflow to apply a model training to larger data sets. If you have questions about this approach or would like to discuss the conditions of your own workflow, please submit a ticket to Customer Support.
Basic assumptions
- Even if you are comfortable with the time to rebuild the model at 10 million documents, there is bound to be a threshold where the rebuild becomes too long. Often, that threshold is below the case sizes for some Relativity users.
- When dealing with 10+ million documents, randomly sampled sub-slices containing millions of documents each yield highly representative data sets. Separating a document set into multiple slices gives largely consistent term coverage, document types, and other characteristic factors. Each slice's conceptual indexes and Active Learning histograms will be quite similar.
- Taking several thousand training documents and adding them to a slice of several million uncoded documents will yield a model slightly different than adding those training documents to a different slice of several million uncoded documents. However, since randomly-selected slices are mostly consistent, the models will not be substantially different. (As an aside, this effect could be measured by tracking the ranks of a small random sample of uncoded documents submitted to each slice.)
Caveats
- Active Learning models rebuild on a timer prompted 20 minutes after the last model build completed. There is also an idle timer that triggers a rebuild sooner than 20 minutes if reviewer activity has been idle for five minutes and there are coding decisions not included in the most recent build. There is no direct way to request a model build other than to wait for this timer. Because of these timers (and rebuilds taking several hours with larger data sets) we recommend actively managing how the different slices are built and coded. More detail is in the sections below.
- There is one way to disable the rebuild timers, which is by starting and accepting Project Validation. We recommend employing Project Validation with just one document in it if you want to freeze a model without engaging in a full Project Validation process.
- Model rebuilds are queued and single-threaded. If four models are requesting a rebuild, the builds occur one at a time.
- Updating ranks is also serial (and resource-intensive).
Scenario
Suppose you have a set S of documents which is too large to be handled in a single active learning project. Culling the set is not feasible, so you need to pursue a multi-project approach.
Proposal
Begin by splitting S into smaller sets. Then, take one subset and build an Active Learning project, following a standard process to find an effective training set. Finally, apply these training documents to the remaining subsets to classify the full document set S without any single Active Learning project exceeding Relativity’s size limits.
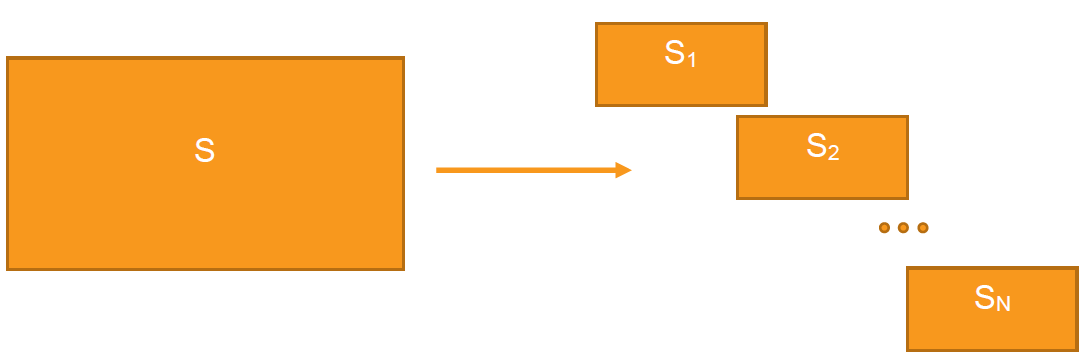
For instance, suppose S contains 30 million documents. We propose that you create subsamples S1, S2, S3, S4, each with size 7.5 million, using random sampling. One subsample (S1) is subjected to normal model training processes, including Coverage Review, building a conceptual index, clustering/stratified sampling, searching for key docs, etc.
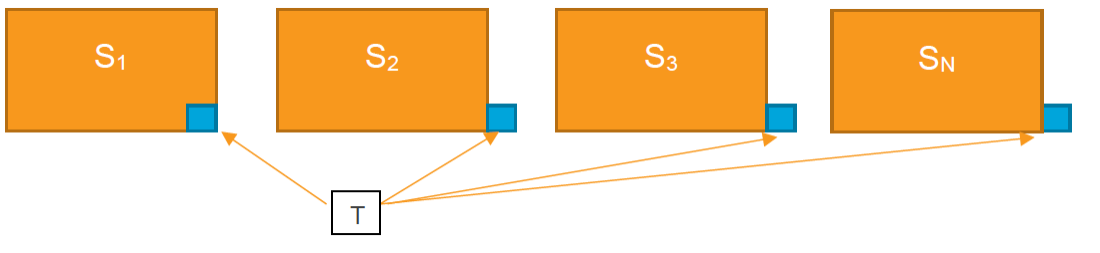
After the training of S1 is complete, the training documents (on the order of 5,000 to 10,000 documents, let's call them T) are added to the subsequent projects. First add the training documents to the set S2 and build a second classification index and a second Active Learning project. Then, update ranks and validate using a random sample across S2. Once you are satisfied with S2, move on to S3, then S4 repeating the same process. It's important to proceed one set at a time to reduce the chance of overloading the Analytics Server with work that is not immediately pertinent to the process.
Process details
Here are the steps for the setup and execution of this process:
- Create a field and choices - create a document field to correspond to the split subsets. For this example, assume the field is called AL Slice with the choices S1, S2, etc.
- Split the document set into subsets - draw a simple random sample of a fixed size (i.e. the size of each subset) from all documents. Mass-tag the set with the S1 choice. Clear the sample and run a search with conditions added for "AL Slice" is not "S1". Repeat, mass-tagging S2, S3, etc.
- Build the Active Learning project using S1 - build the first project, called AL Project 1 for this example, from S1. The saved search should have the condition, "AL Slice" is "S1". In addition, you may choose to build a conceptual index from S1 to aid with the review.
- Train AL Project 1 - Use Coverage Review (or other proprietary techniques) to find training documents in AL Project 1. Cease training when AL project 1 is deemed to have stabilized.
- Create a saved search for Si - create a saved search to be used for the classification indexes for the other slices with the following conditions. The first condition corresponds to the current Si slice, while the second and third bring in the training set T:
- "AL Slice" is "Si" (for i=2, 3, …)
OR - ("AL Slice" is "S1"
AND - "AL Designation" is set)
- "AL Slice" is "Si" (for i=2, 3, …)
- Build the classification index and Active Learning project for S2 (AL Project 2).
- Update ranks on AL Project 2.
- Validate AL Project 2 using Elusion with Recall - see Project Validation and Elusion Testing for more information.
- Freeze the model - accept the Project Validation results so the model will be frozen and will not rebuild. If you have conducted validation using other means, conduct a one-document dummy Project Validation, and then accept it to freeze the model.
- If validation is successful, repeat steps 6 through 9 on S3, S4, etc.
To generate a validation across all models, you can use statistical principles to combine the separate validations. If the size of the samples and Si are all the same size, it’s trivial; however, even if they are not, you can use stratified sampling to generate proportional samples and combine them. - Review predicted responsive documents - batch predicted responsive documents by finding uncoded documents whose rank is above the cutoff for their Si slice, assuming you have updated ranks on each slice’s Active Learning project.
Incremental loads
For incremental loads of data, you have a few options:
- For relatively small incremental loads (less than 1 million documents), add the new documents to the last slice (SN), and update ranks to score the new documents. Draw a proportional sample across the new documents to update Project Validation.
- If significant numbers of new documents are brought in, you can choose to spread them randomly across the Si sets. Take each Si individually, validating and locking the model before proceeding to the next Si.
- A third option is to create a new slice/Active Learning project (SN+1) with the new documents and the training from earlier documents. This new slice will be less homogenous.
Other considerations: data reduction
Whenever high volume is going to be a factor, the following steps can help reduce the amount of volume present in the Active Learning projects:
- Exclude textually "empty" documents - these could be empty documents or documents with poor text, like number-only documents.
- Simple deduplication - reduce hash duplicates to just one copy to include in the projects. Once the model ranks a document, you can set the hash duplicates' fields using the Propagate Coding Post-Import script.
- Textual “exact” duplicates - another way to create relational groups of identical items is to use textual near duplicate identification with a minimum similarity of 100% to identify documents with 100% the same words and word order (the algorithm does not consider punctuation, whitespace, or capitalization). Examples of documents with different MD5 hashes but the same extracted text abound. Running this algorithm can serve to significantly reduce an otherwise de-duplicated population.
- Non-inclusive and duplicate spare emails - if you are producing only inclusive emails, running email threading before Active Learning can aid data reduction. Note, that email threading also has its own data set size limitations, so this can be tricky to implement across all documents.
- More aggressive data reduction - you could of course remove near duplicates from the set for the purposes of model training, but this would start to present issues with the statistical purity of your random samples.