






Feedback
Last date modified: 2026-Jul-14
aiR Assist
aiR Assist is a conversational search tool integrated within RelativityOne, designed to empower legal teams to interact with their data using natural language. By leveraging advanced AI, aiR Assist helps to surface potential insights, reveal possible connections, and uncover themes more efficiently. This can enhance the process they use to analyze and interpret legal data more effectively, potentially leading to quicker understanding, better decisions, and defensible workflows when validated by users.
It works by searching the extracted text of indexed documents. Users can create up to five indexes per workspace, each supporting up to 300,000 documents. When a query is submitted, aiR Assist identifies the documents deemed most relevant and employs a large language model (LLM) to generate answers with citations.
ARM is not supported for aiR Assist. aiR Assist permissions, indexes, conversations, and metadata mapping cannot be archived, restored, or moved using ARM.
aiR Assist availability
aiR Assist is available to organizations with an aiR for Case Strategy contract or aiR Integrated contract. It does not require installation in RelativityOne.
| Contract type | Availability |
|---|---|
| aiR for Case Strategy contract | aiR Assist is available in review workspaces where aiR for Case Strategy is installed and at least one Fact Extraction or Transcript Summary job has completed. Customers can also create a Case Home index. For more information about completing these jobs, refer to aiR for Case Strategy documentation. If an aiR for Case Strategy workspace does not meet the required conditions (aiR for Case Strategy is installed and a Fact Extraction or Transcript Summary job has completed), users can open aiR Assist, but they cannot use it until one of those jobs runs. |
|
|
aiR Assist is available in both repository and review workspaces. The aiR for Case Strategy installation and job-completion requirements do not apply. Customers can also build a Case Home index based on aiR for Case Strategy documents. For more information about completing these jobs, refer to aiR for Case Strategy documentation. |
To use aiR Assist, the appropriate permissions must be configured for each group in each workspace, regardless of contract type. See Permissions for more information. The aiR Assist icon appears at the top of the sidebar.
If you have an integrated pricing contract, you can access aiR for Case Strategy and aiR Assist in both standard and repository workspaces. For aiR for Case Strategy, the integrated pricing contract provides an allotment of up to 50,000 documents to use in repository workspaces for each period, generally annually, of the SaaS subscription term. For aiR Assist, there are no additional considerations for repository workspace use on integrated pricing contracts. To learn more, contact your Account Executive.
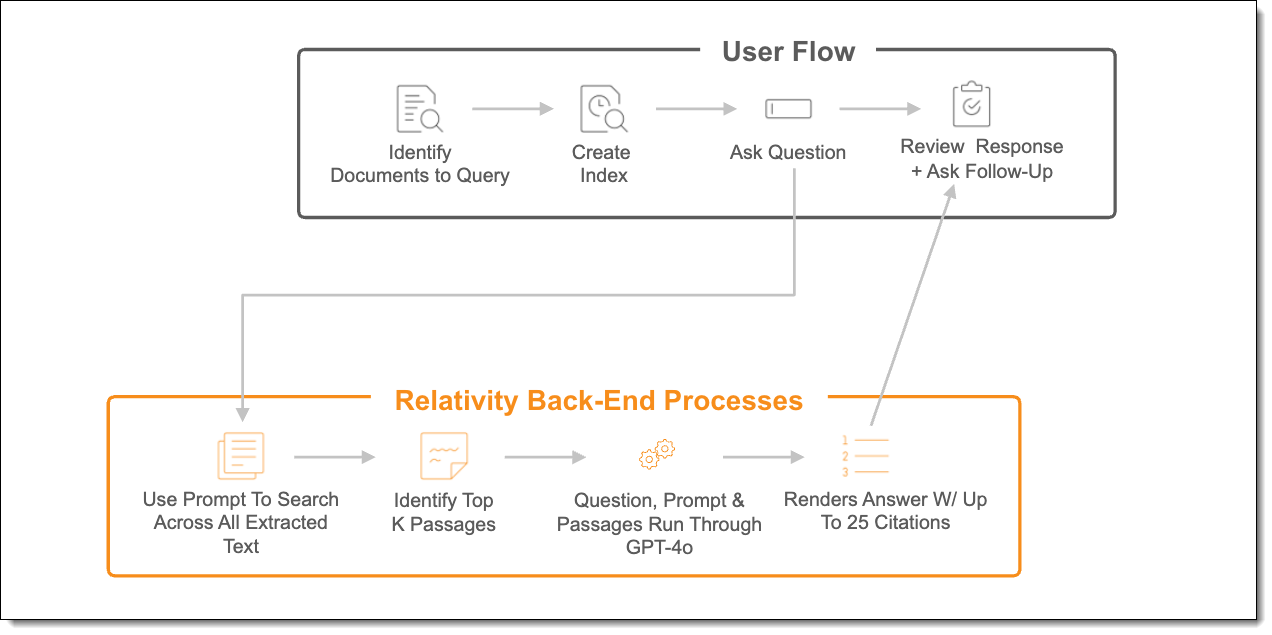
How aiR Assist works
aiR Assist operates using a Retrieval-Augmented Generation (RAG) process to deliver grounded, evidence-based responses. This approach combines document retrieval with large language model generation to help support accuracy, transparency, and contextual relevance.
- Indexing the documents (indexing step)
The user identifies documents to query and creates an index. - Asking a question (question step)
The user asks a question. - Finding relevant documents (retrieval step)
Each question is matched against the text indexed from the identified documents. aiR Assist performs a similarity search to identify the most relevant content. The documents are divided into smaller passages, and the system selects results that are estimated to correspond most closely to the question. - Generating the answer (generation step)
The selected passages, along with the original question and system prompt, are passed to the LLM. The model uses this retrieved context to generate a response intended to be coherent, concise, and supported by retrieved content, citations, and references to the original sources.
Index and document limits
Below are the index and document limits.
| Type | Limit |
|---|---|
|
Index |
|
| Document |
|
Understanding aiR Assist responses
aiR Assist helps identify and summarize potentially relevant information across large document sets using natural language interaction. Built on a Retrieval-Augmented Generation (RAG) architecture, it retrieves and analyzes the documents most likely to be relevant, then generates a citation-supported response based on that content.
It returns contextually relevant and evidence-based information rather than performing exhaustive or “find everything” searches. Because it does not review each document individually, some keyword or topic matches may not be included in the response.
The RAG process works best when key evidence is found in a few focused documents. Results are less accurate if answers depend on scattered or unclear information.
Language support
The LLM used by aiR Assist has been evaluated for 83 languages. Although aiR Assist has primarily been tested on English-language documents, it is designed to support non-English datasets.
Unlike other aiR products, aiR Assist system consists of two components:
- Retrieval—the LLM generates search queries to find relevant documents in the index.
- Generation—the LLM summarizes the retrieved documents, picks relevant ones, and synthesizes them into an answer.
Because of this two-step design, there are special considerations when working with non-English datasets. If you use aiR Assist with non-English datasets, we recommend the following:
- When possible, write your question in the same language as the documents being queried—ideally your own native language. If that isn't possible, write your question in English.
- By default, aiR Assist searches for documents in English. If your documents are in another language and you are writing your question in English, tell it which language to search in by adding a sentence such as: "Search in <Language>." This helps the retrieval step generate queries in the specified language. While effective in most cases, the LLM may not always apply the requested language consistently.
- Extracted text and citations remain in the language of the source document — you do not need to translate them yourself before reviewing.
- By default, answers are generated in English. To request an answer in another language, add a sentence to your question, such as "Write answer in <Language>." This approach is effective in most cases, but the LLM may not always generate answer consistently in the requested language.
You can inspect which searches were attempted using the Search Completed summary in the response panel (see Navigating the responses). Use this to iterate on your question and adjust language coverage as needed.
Common use cases
Here are some example questions targeting a few common use cases for aiR Assist:
| Use case | Common category | Example question |
|---|---|---|
| Early Case Insight | Finding potentially important documents | Can you find me documents that discuss potential gifts or incentives? |
| Finding documents by theme | Are there any documents mentioning fraudulent behavior of John Doe? | |
| Understanding actors and roles | Who was involved in discussions about offering gifts? | |
| Case Strategy Development | Identifying a series of events | Create a high-level timeline for events that took place before the start of Project Artemis. |
| Understanding communications and relationships between actors | Who communicated with whom about the contract terms? | |
| Deposition/Trial Preparation | Suggesting exhibits based on key criteria | List documents to use as exhibits based on [key document criteria]. |
| Confirming conversations or actions took place | Did John Maxwell send an email about the compliance policy? |
Auditing user activity
You can monitor aiR Assist user activity in the Audit application in your Relativity instance. The Audit table records the events listed below. Because aiR Assist audit events are not RDO objects, they use an Audit Object UUID in the Audit table instead of an Object Artifact ID. For more information on using the Audit application,
This is a temporary solution, therefore, we do not recommend building any integrations based on these audit record types. The data is planned to be moved to Custom Reports by the end of 2026.
The following are aiR Assist object types and corresponding actions that will appear in the Audit table:
When you filter on the Object Type column, RDO objects are listed first. Since aiR Assist is not an RDO object, its object types appear at the end of the list. To locate them faster, enter aiR Assist in the filter search box.
| Object Type | Action |
|---|---|
| aiR Assist Question |
|
| aiR Assist Answer |
|
| aiR Assist Conversation |
|
| aiR Assist Index |
|
| aiR Assist Indexing Error List |
|
| aiR Assist Metadata Mapping |
|
So, for example, if you opened a conversation, submitted a new question, and received an answer, the records would be as follows:
- aiR Assist Conversation = View
- aiR Assist Question = Create
- aiR Assist Answer = Create