Feedback
Last date modified: 2026-Apr-30
Processing sets
A processing set is an object to which you attach a processing profile and at least one data source and then use as the basis for a processing job. When you run a processing job, the processing engine refers to the settings specified on the data sources attached to the processing set when bringing data into Relativity.
Consider the following about processing sets:
- A single processing set can contain multiple data sources.
- Only one processing profile can be added to a processing set.
- You can't delete a workspace in which there is an in-progress inventory, discovery, or publish job in the Processing Queue.
- Don't add documents to a workspace and link those documents to an in-progress processing set. Doing this distorts the processing set's report data.
- When processing data, Relativity works within the bounds of the operating system and the programs installed on it. Therefore, it can’t tell the difference between a file that's missing because it was quarantined by anti-virus protection and a file that was deleted after the user initiated discovery.
- Never stop Relativity services through Windows Services or use the IIS to stop a processing job.
- Processing jobs are not paused during scheduled maintenance periods. However, if Relativity encounters an issue during this time, it will automatically retry the job. If the job fails, you can manually retry the errors through the Files or Job Exceptions tabs.
Processing sets default view
Use the Processing Sets sub-tab to see a list of all the processing sets in your environment.
You can manually search for any processing set in the workspace by entering its name in the text box at the top of the list and clicking Enter. Relativity treats the search terms you enter here as a literal contains search, meaning that it takes exactly what you enter and looks for any processing set that contains those terms.
This view provides the following information:
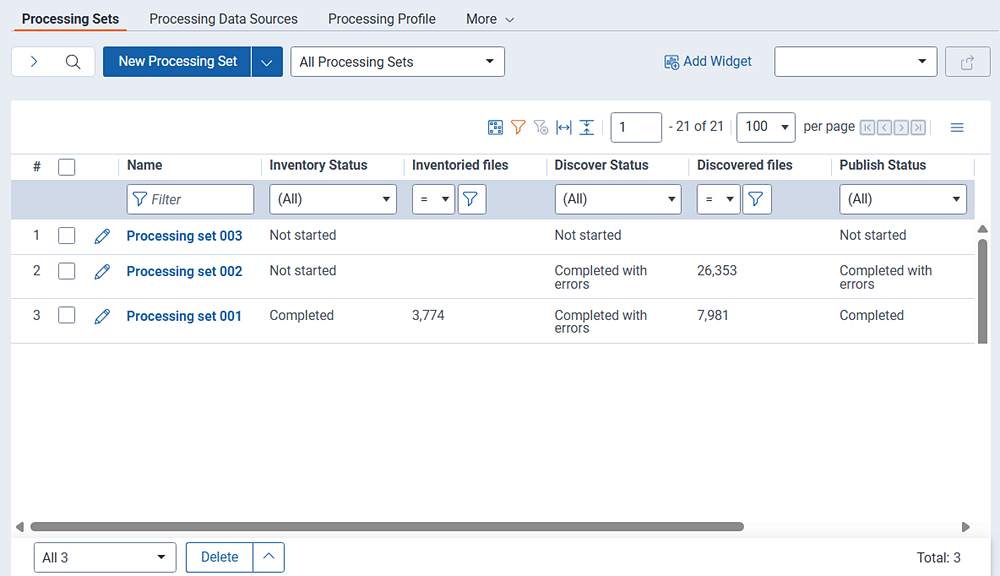
- Name—the name of the processing set.
- Inventory Status—the current status of the inventory phase of the set. This field could display any of the following status values:
- Not started
- In progress
- Completed
- Completed with errors
- Re-inventory required—Data sources modified
- Canceled
- Finalized failed
- Inventoried files—the number of files across all data sources on the set that have been inventoried.
Inventory populates only job level errors.
- Discover Status—the current status of the discovery phase of the set. This field could display any of the following status values:
- Not started
- In progress
- Completed
- Completed with errors
- Canceled
- Discovered files—the number of files across all data sources on the set that have been discovered.
Discovery populates job and document level errors.
- Publish Status—the current status of the publish phase of the set. This field could display any of the following status values:
- Not started
- In progress
- Completed
- Completed with errors
- Canceled
- Published documents—the number of files across all data sources on the set that have been published to the workspace.
By adding the Originating Processing Set document field to any view, you can indicate which processing set a document came from.
From the Processing Sets sub-tab you can:
- Open and edit an existing processing set.
- Perform the following mass operations on selected processing sets:
- Delete
- Export to File
- Tally/Sum/Average
The Copy, Edit, and Replace mass operations are not available for use with processing sets.
Creating a processing set
When you create a processing set, you are specifying the settings that the processing engine uses to process data.
To create a processing set:
- Navigate to the Processing tab and then click the Processing Sets sub-tab.
- Click the New Processing Set button to display the Processing Set layout.
- Complete the fields on the Processing Set layout.
- Click Save.
- Add as many Processing Data Sources to the set as you need.
Processing set fields
To create a processing set, complete the following fields:
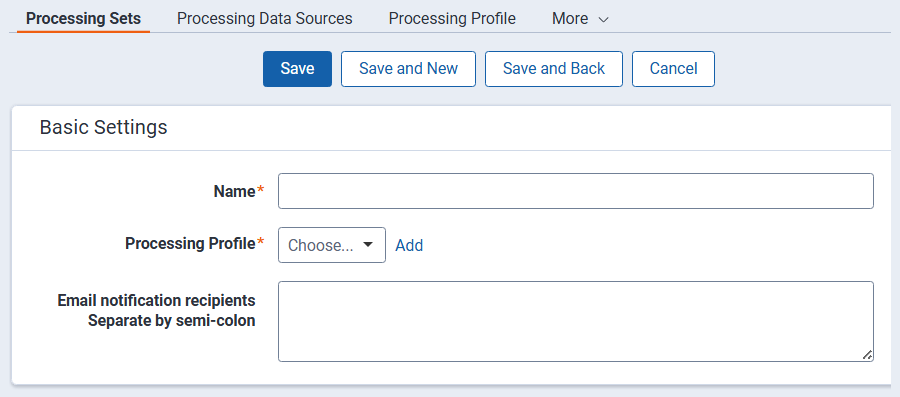
- Name—the name of the set.
- Processing profile—select any of the profiles you created in the Processing Profiles tab. If you haven't created a profile, you can select the Default profile or click Add to create a new one. If there is only one profile in the workspace, that profile is automatically populated here.
- Email notification recipients—the email addresses of those whom you want to receive notifications while the processing set is in progress. Relativity sends an email to notify the recipient of the following:
- Inventory
- Successful inventory completed
- Inventory completed with errors
- First discovery job-level error
- Inventory error during job submission
- Discovery
- Successful discovery completed
- Discovery completed with errors
- First discovery job-level error
- File discovery error during job submission
- Retry—discovery
- First discovery retry job-level error
- Discovery retry error during job submission
- Publish
- Successful publish completed
- Publish complete with errors
- First publish job-level error
- Publish error during job submission
- Retry—publish
- First publish retry job-level error
- Publish retry error during job submission
- Inventory
Email notifications are sent per the completion of processing sets, not data sources. This ensures that a recipient doesn't receive excessive emails. The exception to this is job-level errors. If all data sources encounter a job-level error, then Relativity sends an email per data source.
After you save the processing set, the layout is updated to include the process set status display. The display remains blank until you start either inventory or file discovery from the console. The console remains disabled until you add at least one data source to the set.
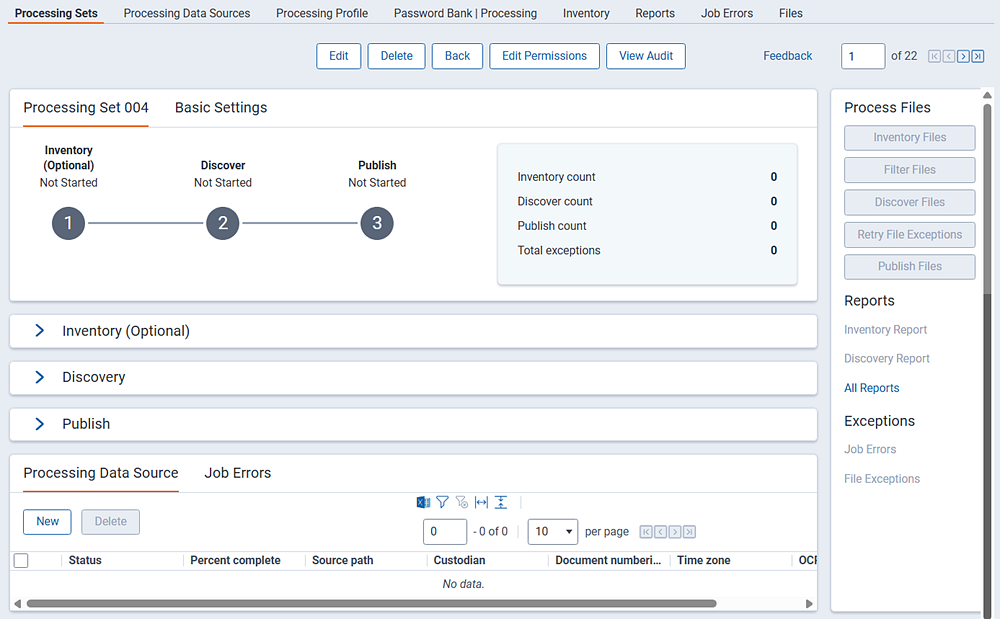
The Processing Set Status section of the set layout provides data and visual cues that you can use to measure progress throughout the life of the processing set. This display and the information in the status section refresh automatically every five seconds to reflect changes in the job.
To create a Quick-create set, see Quick-create set(s) for more information.
Adding a data source
A Processing Data Source is an object you associate with a processing set in order to specify the source path of the files you intend to inventory, discover, and publish, as well as the custodian who facilitates that data and other settings.
- Be sure your data sources have unique names. If you have data sources with duplicate names, you may see processing errors.
- Example of duplicate data source names:
- \\[file.share]\Processing Source[SOURCE.NAME]
- \\[file.share]\Processing Source[Source.Name]
- Example of unique data source names:
- \\[file.share]\Processing Source[SOURCE.NAME1]
- \\[file.share]\Processing Source[Source.Name2]
- Example of duplicate data source names:
- You have the option of using Integration Points to import a list of custodians from Active Directory into the Data Sources object. Doing this would give you an evergreen catalog of custodians to pick from when preparing to run a processing job.
- You can add multiple data sources to a single processing set, which means that you can process data for multiple custodians through a single set. There is no limit to the number of data sources you can add to a set; however, most sets contain ten or fewer.
- During publish, if you have multiple data sources attached to a single processing set, Relativity starts the second source as soon as the first source reaches the DeDuplication and Document ID generation stage. Previously, Relativity waited until the entire source was published before starting the next one.
To add a data source:
- Create and save a new processing set, or navigate into an existing set.
- In the Processing Data Source section, click New.
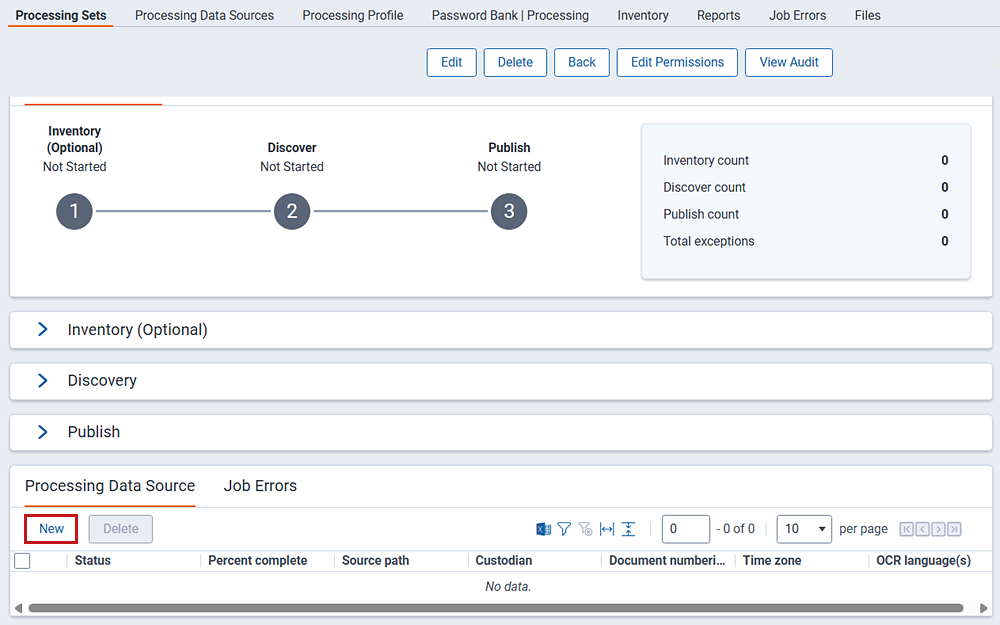
- Complete the fields on the Add Processing Data Source layout.
- Click Save. When you save the data source, it becomes associated with the processing set and the console on the right side is enabled for inventory and file discovery.
For details on what information is displayed in the data source view while the processing set is running, see Processing Data Source.
If you add, edit, or delete a data source associated with a processing set that has already been inventoried but not yet discovered, you must run inventory again on that processing set. You can't add or delete a data source to or from a processing set that has already been discovered or if there's already a job in the processing queue for the processing set.
Data source fields
To add a data source, complete the following fields:
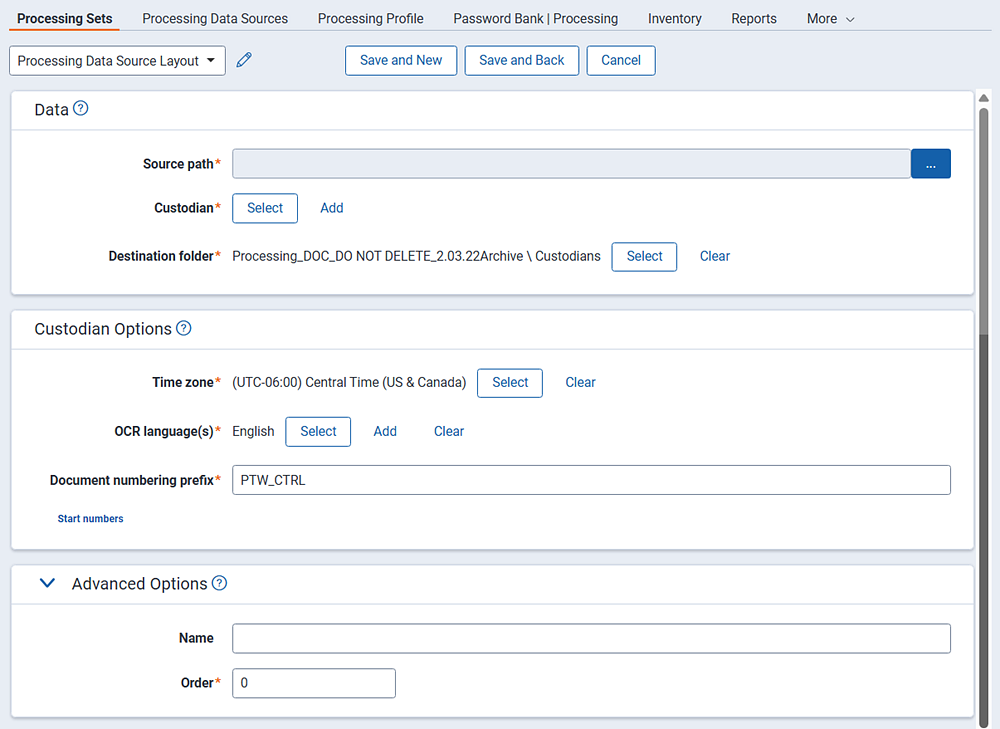
Data
- Source path—the location of the data you want to process. Click Browse to select the path. The source path you select controls the folder tree below. The folder tree displays an icon for each file or folder within the source path. You can specify source paths in the resource pool under the Processing Source Location object. Click Save after you select a folder or file in this field.
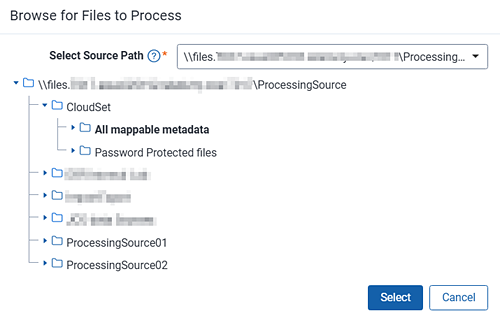
- The processing engine processes all the files located in the folder you select as your source as one job. This includes, for example, a case in which you place five different .PSTs from one custodian in a single folder.
- You can specify source paths in the resource pool under the Processing Source Location object. The Relativity Service Account must have read access to the processing source locations on the resource pool.
- Depending on the case sensitivity of your network file system, the source location that you add through the resource pool may be case sensitive and might have to match the actual source path exactly. For example, if the name of the file share folder is \\files\SampleShare\Sample, you must enter this exactly and not as “\\files\SampleShare\sample” or “\\files\sampleshare\Sample”, or any other variation of the actual name. Doing so will result in a document-level processing error stating, “The system cannot find the file specified.”
- If you process files from source locations contained in a drive that you have attached to your computer, you can detach those original source locations without issue after the processing set finishes. This is because Relativity copies the files from the source locations to the Relativity file repository. For a graphical representation of how this works, see Copying natives during processing.
Processing supports long file paths, but in the case of other Windows parsing issues outside of long path issues, Relativity won't be able to read that path. It is recommended that you pull documents out of subfolders that are nested in deep layers so that they are not hidden. - Custodian—the owner of the processed data. When you select a custodian with a specified prefix, the default document numbering prefix field changes to reflect the custodian's prefix. Thus, the prefix from the custodian takes precedence over the prefix on the profile.
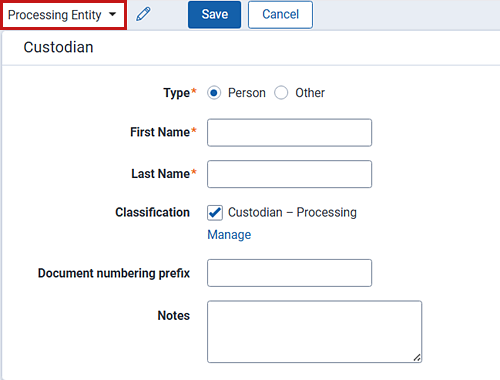
- Type
- Person—the individual acting as entity of the data you wish to process.
- Other—the entity of the data you wish to process that isn't an individual but is, for example, just a company name. You can also select this if you wish to enter an individual's full name without having that name include a comma once you export the data associated with it. Selecting this changes the Entity layout to remove the required First Name and Last Name fields and instead presents a required Full Name field.
- First Name—the first name of the entity. This field is only available if you've set the Type above to Person.
- Last Name—the last name of the entity. This field is only available if you've set the Type above to Person.
- Full Name—the full name of the entity of the data you wish to process. This field is only available if you've set the Type above to Other. When you enter the full name of an entity, that name doesn't contain a comma when you export the data associated with it.
- Classification—differentiates among entity records created for Processing or Name Normalization.
- Custodian – Processing—the indicator that this custodian was created for Processing.
When new custodians are created using the Quick-Create Set(s) layout, the classification is set to Custodian – Processing.- Communicator—the indicator that the record was created by Name Normalization.
- Document numbering prefix—the prefix used to identify each file of a processing set once the set is published. The prefix entered on the entity appears as the default value for the required Document numbering prefix field on the processing data source that uses that entity. The identifier of the published file reads: <Prefix> # # # # # # # # # #.
- Notes—any additional descriptors of the entity.
- If you add processing to an environment that already has custodian information in its database, Relativity doesn't sync the imported custodian data with the existing custodian data. Instead, it creates separate custodian entries.
- If a single custodian has two identical copies of a document in different folders, only the primary document makes it into Relativity. Relativity stores a complete record internally of the duplicate, and, if mapped, the duplicate paths, all paths, duplicate custodian, all custodian fields in the primary record are published. Additionally, there may be other mapped fields available that can describe additional fields of the duplicates.
One of the options you have for bringing custodians into Relativity is Integration Points (RIP). You can use RIP to import any number of custodians into your environment from Active Directory and then associate those custodians with the data sources that you add to your processing set.
- Destination folder—the folder in Relativity where the processed data is published. This default value of this field is pulled from the processing profile. If you edit this field to a different destination folder location, the processing engine reads this value and not the folder specified on the profile. You can select an existing folder or create a new one by right-clicking the base folder and selecting Create.
- If the source path you selected is an individual file or a container, such as a zip, then the folder tree does not include the folder name that contains the individual file or container.
- If the source path you selected is a folder, then the folder tree includes the name of the folder you selected.
- After you create a destination folder and it is published, you cannot delete it.
Custodian Options
- Time Zone—determines what time zone is used to display date and time on a processed document. The default value is the time zone entered on the profile associated with this set. The default value for all new profiles is Coordinated Universal Time (UTC). If you wish to change this, click Select to choose from a picker list of available time zone values.
- OCR language(s)—determines what language is used to OCR files where text extraction isn't possible, such as for image files containing text.
- Selecting multiple languages will increase the amount of time required to complete the OCR process, as the engine will need to go through each language selected.
- The default value is the language entered on the profile associated with this set.
- Document numbering prefix—the prefix applied to the files once they are published. On published files, this appears as <Prefix>xxxxxxxxxx—the prefix followed by the number of digits specified. The numbering prefix from the custodian takes precedence over the prefix on the processing profile. This means that if you select a custodian with a different document numbering prefix than that found on the profile referenced by the processing set, this field changes to reflect the prefix of the custodian.
- Start Number—the starting number for the documents published from this data source.
- This field is only visible if your processing set is using a profile with a Numbering Type field value of Define Start Number.
- If the value you enter here differs from the value you entered for the Default Start Number field on the profile, then this value takes precedence over the value on the profile.
- The maximum value you can enter here is 2,147,483,647. If you enter a higher value, you'll receive an Invalid Integer warning next to field value and you won't be able to save the profile.
- If you leave this field blank or if there are conflicts, then Relativity will auto-number the documents in this data source. This means it will use the next available control number for the document numbering prefix entered. For example, if you've already published 100 documents to the workspace and you mistakenly enter 0000000099 as a start number, Relativity will automatically adjust this value to be 0000000101, as the value you entered was already included sequentially in the previously published documents.
- You can use the Check for Conflicts option next to this field. When you click this, you'll be notified that the start number you entered is acceptable or that it's already taken and that the documents in that data source will be auto-numbered with the next available control number. Note that this conflict check could take a long time to complete, depending on the number of documents already published to the workspace.
When Level Numbering is selected, you can define the start number for each Processing Data Source. - Start Numbers—allows you to define the first number to use on each level for this specific data source.
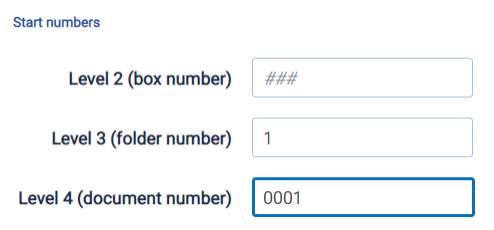
When you create a new profile or when there are no values on a field, the system will use # to indicate how many digits were configured for that level in the Processing Profile used on the Processing Set.
If a level was configured to take up to 3 digits, enter a start number with no padding, (e.g., 1) or with padding, (e.g., 0001).
Advanced Options
- Name—the name you want the data source to appear under when you include this field on a view or associate this data source with another object or if this data source encounters an error. Leaving this blank means that the data source is listed by custodian name and artifact ID. Populating this field is useful in helping you identify errors later in your processing workflow.
The processing data source is saved with <Custodian Last Name>, <Custodian First Name> - < Artifact ID> populated for the Name field, if you leave this field blank when creating the data source. Previously, this field only displayed the artifact ID if it was left blank. This is useful when you need to identify errors per data source on an error dashboard, as those data sources otherwise wouldn't display a custodian name.
- Order—the priority of the data source when you load the processing set in the Inventory tab and submit the processing set to the queue. This also determines the order in which files in those sources are de-duplicated. This field is automatically populated. For more information, see Order considerations.
When you delete a document that has been published into Review, Processing will re-calculate deduplication to identify and publish the duplicate if there is one, and will not include the deleted document in subsequent deduplication logic.
Order considerations
- Processing jobs are carried out based on the availability of worker resources. The order number does not influence the allocation of worker resources or performance for Inventory or Discover jobs.
- Relativity does not recommend adding more than 100 data sources to a Processing Set. Doing so could cause performance issues during the submission of the set. If more than 100 data sources are required, it is recommended that you break up the job into multiple Processing Sets.
- The order number does play a part in data source priority for deduplication and assignment of control numbers. Again, the lower the order number, the higher the priority in which data sources are deduped and control numbers assigned.
- You can change the priority of data sources in the Processing and Imaging Queue. If you change the priority of a publish or republish job, you also update the priorities of all other jobs associated with the same data source.
Edit considerations for data sources
Note the following guidelines for modifying data sources:
- You can't add or delete a data source to or from a processing set if there's already a job in the queue for that set or if discovery of that set has already completed.
- If you add a data source to a processing set that has already been inventoried but not yet discovered, you must run inventory again on that processing set.
- If you edit a data source that is associated with a processing set that has already been inventoried but not yet discovered, you must run inventory again on that processing set.
- If you delete a data source from a processing set that has already been inventoried but not yet discovered, you must run inventory again on that processing set.
- If the processing set to which you've added a data source has already been inventoried, with or without errors, but not yet discovered, you're able to edit all fields on that data source; however, you must run inventory again on that processing set after you edit the source.
- If the processing set to which you've added a data source has already been discovered, with or without errors, you can only edit the Name and Document numbering prefix fields on that data source.
- If the processing set to which you've added a data source has already been published, with or without errors, you can only edit the Name field on that data source.
When you make a change that merits a re-inventory job, Relativity applies a "Force reinventory" flag to the processing set's table in the workspace database.
Processing data source view
At the bottom of the processing set layout is the Processing Data Source view, which will display information related to the data sources you add.
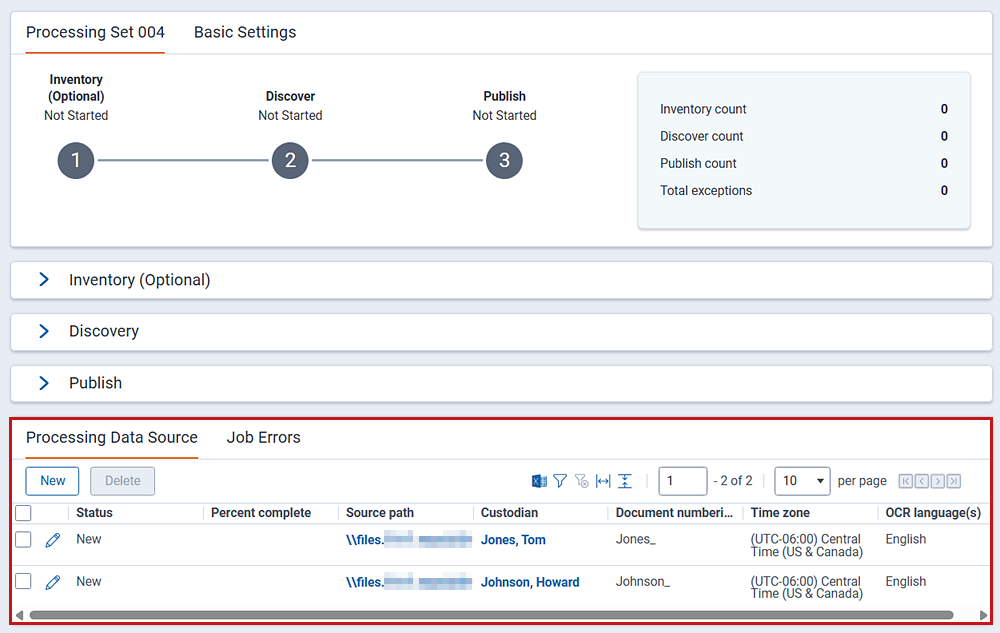
This view provides the following fields:
- Status—the current state of the data source as inventory, discovery, publish, or republish runs on the processing set. This and the Percent Complete value refresh automatically every five seconds. The status values are:
- New—the data source is new and no action has been taken on the processing console.
- Waiting—you've clicked Inventory, Discover, or Publish Files on the console and an agent is waiting to pick up the job.
- Initializing—an agent has picked up the job and is preparing to work on it.
- Document ID Generation—document ID numbers are being generated for every document. You'll see this status if the profile attached to the set has a deduplication method of None.
- DeDuplication and Document ID Generation—the primary and duplicate documents are being identified, and the document ID number is being generated for every document. You'll see this status if the profile attached to the set has deduplication set to Global or Custodial. If you have multiple data sources attached to a single processing set, the second source is started as soon as the first set reaches the DeDuplication and Document ID generation stage. Previously, Relativity waited until the entire source was published before starting the next one.
- Deduped Metadata Overlay—deduped metadata is being overlaid onto the primary documents in Relativity. This status was added in July 2017 as part of the distributed publish enhancement.
- Inventorying/Discovering/Publishing—an agent is working on the job. Refer to the Percent Complete value to see how close the job is to being done.
- Inventory/Discovery/Publish files complete—the job is complete, and the Percent Complete value is at 100%.
- Unavailable—the data source is not accessible and no action can be taken on the processing console.
- Percent Complete—the percentage of documents in the data source that have been inventoried, discovered, or published. This and the Status value refresh automatically every five seconds.
- Source path—the path you selected for the source path field on the data source layout.
- Custodian—the custodian you selected for the data source.
- Document numbering prefix—the value you entered to correspond with the custodian on the data source layout. If you didn't specify a prefix for the data source, then this is the default prefix that appears on the processing profile.
- Time zone—the time zone you selected for the data source.
- OCR language(s)—the OCR language(s) you selected on the data source.
Job Errors view
At the bottom of the processing set layout is the Job Errors view, which displays information related to all job-level errors that occurred on all data sources associated with the set.
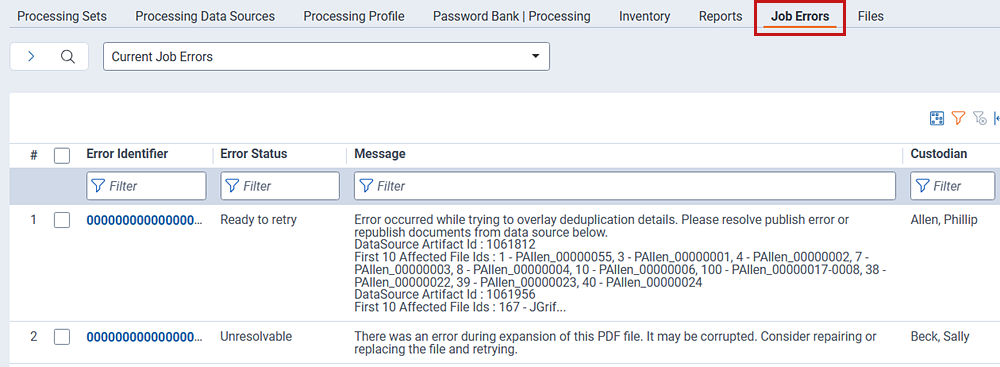
- Error Identifier—the unique identifier of the error as it occurs in the database. When you click this message, you are taken to the error details layout, where you can view the stack trace and other information. Note that for Unresolvable errors, the console is disabled because you cannot take any actions on that error from inside Relativity. For more information, see Processing error resolution.
- Error Status—the status of the error. This is most likely Unresolvable.
- Message—the cause and nature of the error. For example, "Error occurred while trying to overlay de-duplication details. Please resolve publish error or republish documents from data source below. DataSource Artifact Id: 1695700".
- Custodian—the custodian associated with the data source containing the file on which the error occurred.
- Processing Set—the name of the processing set in which the error occurred.
- Data Source—the data source containing the file on which the error occurred.
- Error Created On—the date and time at which the error occurred during the processing job.
- Republish Required—the error must be retried in order to be successfully published.
- Notes—any manually added notes associated with the error.
For more information on handling document errors, see Processing error resolution.
Processing Data Sources tab
To see all data sources associated with all processing sets in the workspace, navigate to the Processing Data Sources sub-tab.
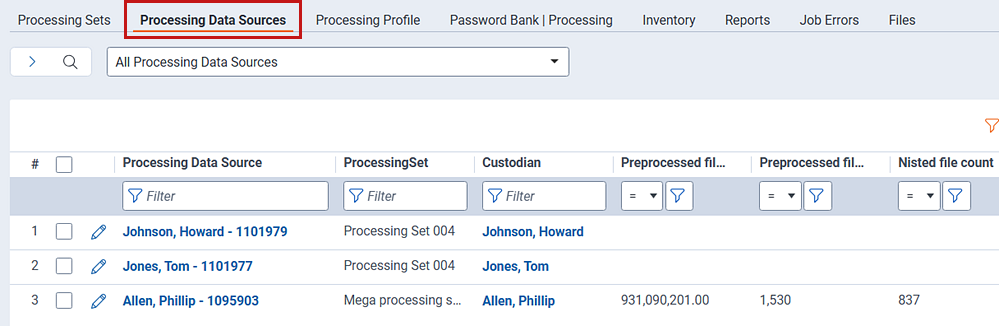
The default view on the Processing Data Sources tab includes the following fields:
- Processing Data Source—the name of the data source. If you originally left this blank, then this value will consist of the name of the custodian and artifact ID.
- ProcessingSet—the name of the processing set the data source is attached to.
- Custodian—the custodian attached to the data source.
- Preprocessed file size—the total size, in bytes, of all the files in the data source before you started the processing set.
- Preprocessed file count—the number of files in the data source before you started the processing set.
- Nisted file count—the number of files from the data source that were then removed, per the de-NIST setting.
- Excluded file size—the number of files from the data source that were excluded from discovery.
- Excluded file count—the total size, in bytes, of all the documents from the data source that were excluded from discovery.
- Filtered file count—the number of files from the data source that were filtered out before discovery.
- Discover time submitted—the date and time at which the files in the data source were last submitted for discovery.
- Discovered document size—the total size, in bytes, of all the documents from the data source that were successfully discovered.
- Discovered document count—the number of files from the data source that were successfully discovered.
- Last publish time submitted—the date and time at which the files in the data source were last submitted for publish.
- Deduplication method—the deduplication method set on the processing profile associated with the processing set.
- Duplicate file count—the number of files that were deduplicated based on the method set on the processing profile.
- Published documents—the number of documents from the data source that were successfully published.
- Published document size—the total size, in bytes, of all the documents from the data source that were successfully published.
- Status—the current status of the data source.
- Artifact ID—the artifact ID of the workspace.
- Auto-publish set—arranges for the processing engine to automatically kick off publish after the completion of discovery, with or without errors. By default, this is set to No.
- Container count—the count of all native files classified as containers before extraction/decompression, as they exist in storage. This also includes nested containers that haven’t been extracted yet.
- Container size—the sum of all native file sizes, in bytes, classified as containers before extraction/decompression, as they exist in storage. this value may be larger than the preprocessed file size because it also includes nested containers.
- Custodian::Department—the department of a Custodian-type entity
- Custodian::Email—the email address of a Custodian-type entity
- Delimiter—the delimiter you want to appear between the different fragments of the control number of your published child documents.
- DeNIST Mode -determines which files to include in the DeNISTing process. Options include:
- DeNIST all files—parent/child groups are broken and any file on the NIST list is removed.
- Do not break parent/child groups—parent/child groups are left in tact, regardless if the files are on the NIST list. Loose NIST files are removed.
- Destination folder—the folder in Relativity into which documents are placed once they're published to the workspace.
- Discover time complete -the date and time at which the files in the data source were discovered.
- Discovered files—the count of all the native files discovered that aren’t classified as containers as they exist in storage.
- Discovery group ID—the unique identifier of the discovery group.
- Document numbering prefix—the prefix applied to each file in a processing set once it is published to a workspace. The default value for this field is REL.
- Duplicate file size—the sum of duplicate native file sizes, in bytes, associated to the user, processing set and workspace.
- Excel Header/Footer Extraction—header and footer information extracted from Excel files when you publish them.
- Excel Text Extraction Method—determines whether the processing engine uses Excel or dtSearch to extract text from Excel files during publish.
- Extract children—arranges for the removal of child items during discovery, including attachments, embedded objects and images and other non-parent files.
- Filtered file size—the total size, in bytes, of the files from the data source that were filtered out before discovery.
- Inventoried files—the number of files from the data source that were inventoried.
- Is Start Number Visible—true/false value for the starting number field toggle.
- Last activity—the date and time at which a job last communicated to the worker.
- Last document error ID—the unique identifier of an error attached to a document.
- Last inventory group ID—the unique identifier of a group of inventoried files.
- Last inventory time submitted—the date and time at which the files in the data source were last submitted for inventory.
- Last run error—the last job error that occurred in the running of the OCR set.
- Nisted file size -the total size, in bytes, of the files from the data sources that were then removed, per the de-NIST setting.
- Number of Digits—determines how many digits the document's control number contains. The range of available values is 1 and 10. By default, this field is set to 10 characters.
- OCR—enabled or disabled to run OCR during processing.
- OCR Accuracy—the desired accuracy of your OCR results and the speed with which you want the job completed.
- OCR language(s)—the language used to OCR files where text extraction isn't possible, such as for image files containing text.
- OCR Text Separator—a separator between extracted text at the top of a page and text derived from OCR at the bottom of the page in the Extracted Text view.
- Order—the priority of the data source when you load the processing set in the Inventory tab and submit the processing set to the queue. This also determines the order in which files in those sources are de-duplicated.
- Parent/Child Numbering—determines how parent and child documents are numbered relative to each other when published to the workspace.
- Percent Complete—the percentage of documents from the data source that have been discovered or published.
- PowerPoint Text Extraction Method—determines whether the processing engine uses PowerPoint or dtSearch to extract text from PowerPoint files during publish.
- Preexpansion file count—the number of files in the data source for all Level 1 non-container files at the first level after initial expansion.
- Preexpansion file size—the total size, in bytes, of all the files in the data source for all Level 1 non-container files at the first level after initial expansion.
- ProcessingSet::Republish required—errors attached to a processing set that need republishing.
- Propagate deduplication data—applies the deduped custodians, deduped paths, all custodians, and all paths field data to children documents, which allows you to meet production specifications and perform searches on those fields without having to include family or overlay those fields manually.
- Publish group ID—the unique identifier of a published group of documents.
- Publish time complete—time it took for a file to finish publishing.
- Retry jobs remaining—number of errors attached to a file that needs trying.
- Rolled up file count—the number of files rolled up during discovery. This setting references rolled up image text where child images have had their text rolled up into the parent document.
- Security—level of accessibility of files to users.
- Source folder structure retained—the folder structure of the source of the files you process when you bring these files into Relativity is maintained.
- Source path—the location of the data you want to process.
- Start Number—the starting number for documents that are published from the processing set(s) that use this profile.
- Storage file size—the sum of all file sizes, in bytes, as they exist in storage.
- System Created By—identifies the user who created the document.
- System Created On—the date and time when the document was created.
- System Last Modified By—identifies the user who last modified the document.
- System Last Modified On—the date and time at which the document was last modified.
- Time zone—determines what time zone is used to display date and time on a processed document.
- Total file count—the count of all native files (including duplicates and containers) as they exist after decompression and extraction.
- Total file size—the sum of all native file sizes (including duplicates and containers), in bytes, as they exist after decompression and extraction.
- When extracting children, do not extract—excludes MS Office embedded images, MS Office embedded objects, and/or Email inline images when extracting children.
- Word Text Extraction Method—determines whether the processing engine uses Word or dtSearch to extract text from Word files during publish.
Deleting a processing set
If your Relativity environment contains any outdated processing sets that haven't yet been published and are taking up valuable space, or sets that simply contain mistakes, you can delete them, depending on what phase they're currently in.
The following table breaks down when you're able to delete a processing set.
| Point in processing | Can delete? |
|---|---|
| Pre-processing—before Inventory and Discovery have been started | Yes |
| While Inventory is in progress | No |
| After Inventory has been canceled | Yes |
| After Inventory has completed | Yes |
| While Discovery is in progress | No |
| After Discovery has been canceled | Yes |
| After Discovery has completed | Yes |
| While Publish is in progress | No |
| After Publish has been canceled | No |
| After Publish has completed | No |
If you need to delete a processing set that is currently being inventoried or discovered, you must first cancel inventory or discovery and then delete the set.
Deletion jobs will always take the lowest priority in the queue. If another job becomes active while the delete job is running, the delete job will be put into a paused state and will resume once all other jobs are complete.
Permissions
The following security permissions are required to delete a processing set:
- Tab Visibility—Processing Application. (Processing and Processing Sets at minimum.)
- Other Settings—Delete Object Dependencies. This is required to delete the processing set's child objects and linked associated objects.
- Object Security
- Edit permissions for Field, with the Add Field Choice By Link setting checked
- (Optional) Delete permissions for OCR Language
- Delete permissions for Processing Data Source, Processing Error, Processing Field, and Processing Set
Feature Permissions provide an alternative to Relativity's security management by shifting the focus from Object Types and Tab Visibility to feature-based permissions. This method is an alternative option. Any feature-specific permissions information already in this and other topics is still applicable. The Feature Permissions interface enables administrators to manage permissions at the feature level, offering a more intuitive experience. By viewing granular permissions associated with each feature, administrators can ensure comprehensive control, ultimately reducing complexity and minimizing errors. For details see Instance-level permissions and Workspace-level permissions .
To delete a processing set, perform the following steps:
- In the processing set list, select the checkbox next to the set(s) you want to delete. If you're on the processing set's layout, click Delete at the top of the layout.
If you use the Delete mass operation to delete a processing set, but then you cancel that deletion while it is in progress, Relativity puts the set into a canceled state to prevent you from accidentally continuing to use a partially deleted set. You can't process a set for which you canceled deletion or in which a deletion error occurred.
- (Optional) Click View Dependencies on the confirmation window to view all of the processing set's child objects that will also be deleted and the associated objects that will unlink from the set when you proceed with the deletion.
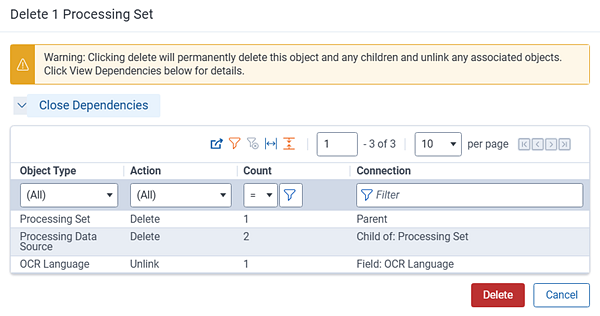
- Click Delete on the confirmation window. When you proceed, you permanently delete the processing set object, its children, and its processing errors, and you unlink all associated objects.
The following table breaks down what kinds of data is deleted from Relativity and Invariant when you delete a processing set in certain phases.
| Phase deleted | From Relativity | From Invariant |
|---|---|---|
| Pre-processed (Inventory and Discovery not yet started) | Processing set object - data sources | N/A |
| Inventoried processing set | Processing set object - errors, data sources, inventory filters | Inventory filter data; inventoried metadata |
| Discovered processing set | Processing set object - errors, data sources | Discovered metadata |
When you delete a processing set, the file deletion manager deletes all physical files and all empty sub-directories. Files that the system previously flagged for future deletion are also deleted.
The following graphic and accompanying steps depict what happens on the back end when you delete a processing set:
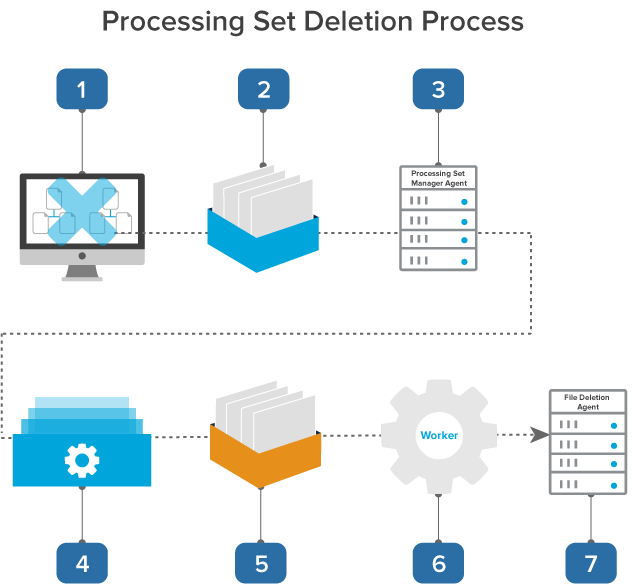
- You click Delete on the processing set.
- A pre-delete event handler inserts the delete job into the queue while Relativity deletes all objects associated with the processing set.
- A processing set agent picks up the job from the queue and verifies that the set is deleted.
- The processing set agent sends the delete job to Invariant.
- The delete job goes into the Invariant queue, where it waits to be picked up by a worker.
- A worker deletes the SQL data associated with the processing set and queues up any corresponding files to be deleted by the File Deletion agent.
- The File Deletion starts up during off hours, accesses the queued files and deletes them from disk.
If an error occurs during deletion, you can retry the error in the Discovered Files tab. see
Avoiding data loss across sets
Due to the way that processing was designed to deal with overwrites during error retry, there is the chance that you can inadvertently erase data while attempting to load documents into Relativity across different modes of import.
To avoid an inadvertent loss of data, do NOT perform the following workflow:
- Run a processing set.
- After the processing set is complete, import a small amount of data using Import/Export so that you can keep one steady stream of control numbers and pick up manually where the previous processing set left off.
- After importing data through Import/Export, run another processing set, during which Relativity tries to start the numbering where the original processing job left off. During this processing set, some of the documents cause errors because some of the control numbers already exist and Relativity knows not to overwrite documents while running a processing set.
- Go to the processing errors tab and retry the errors. In this case, Relativity overwrites the documents, as this is the expected behavior during error retry. During this overwrite, you lose some data.
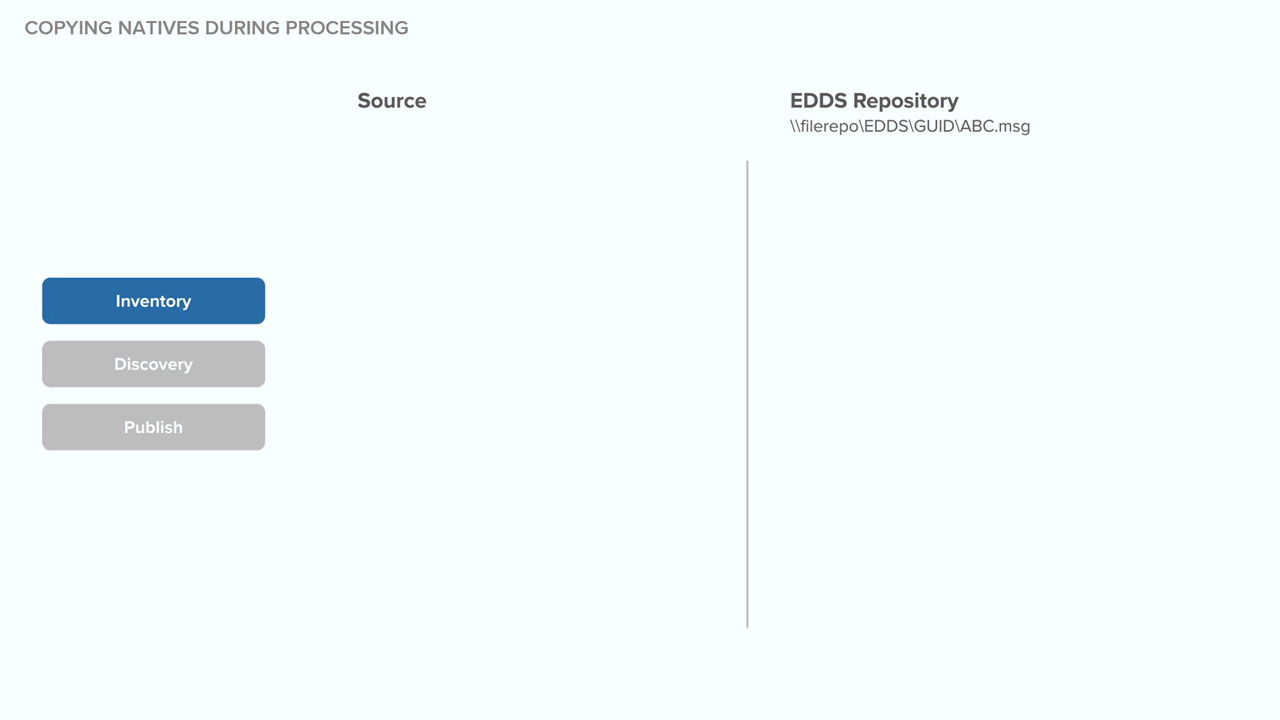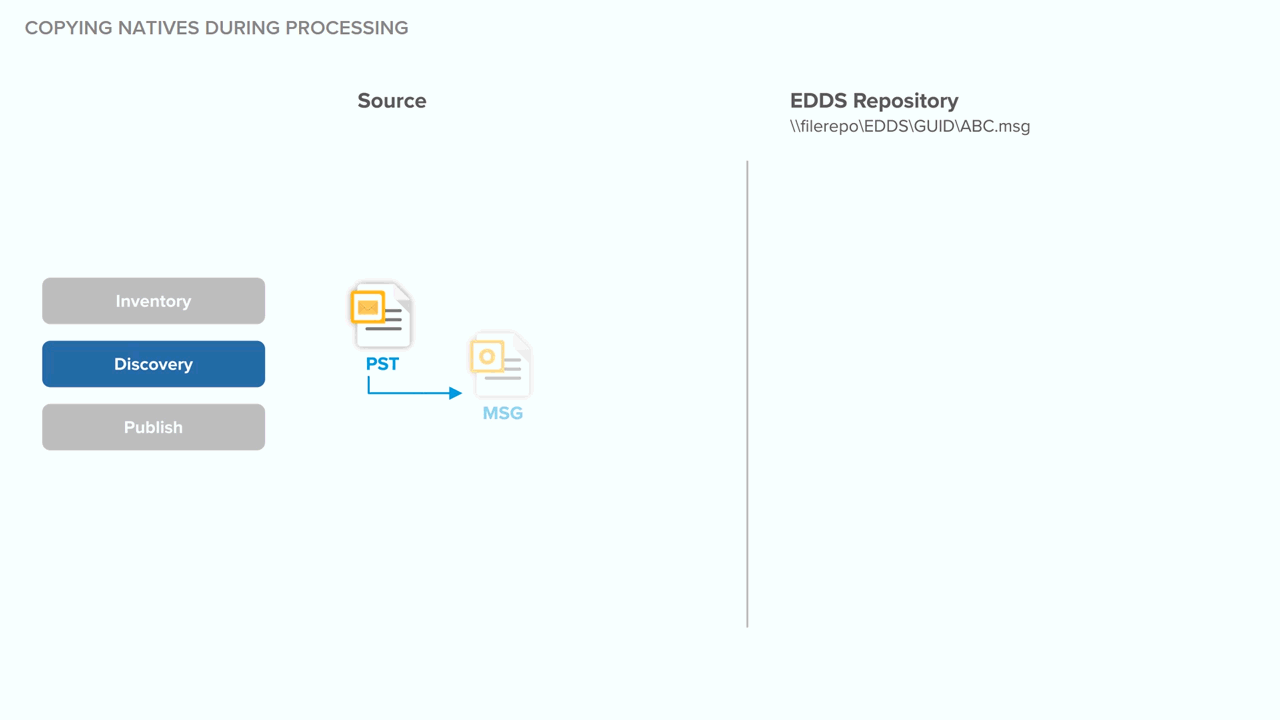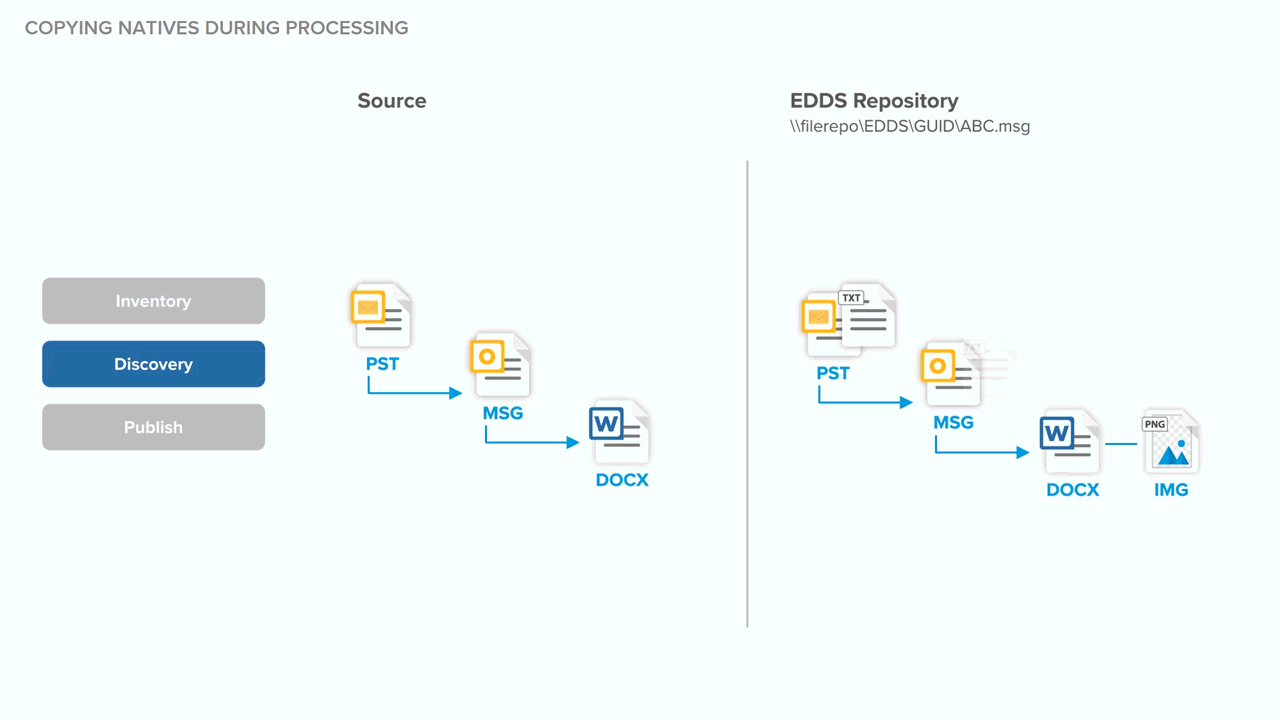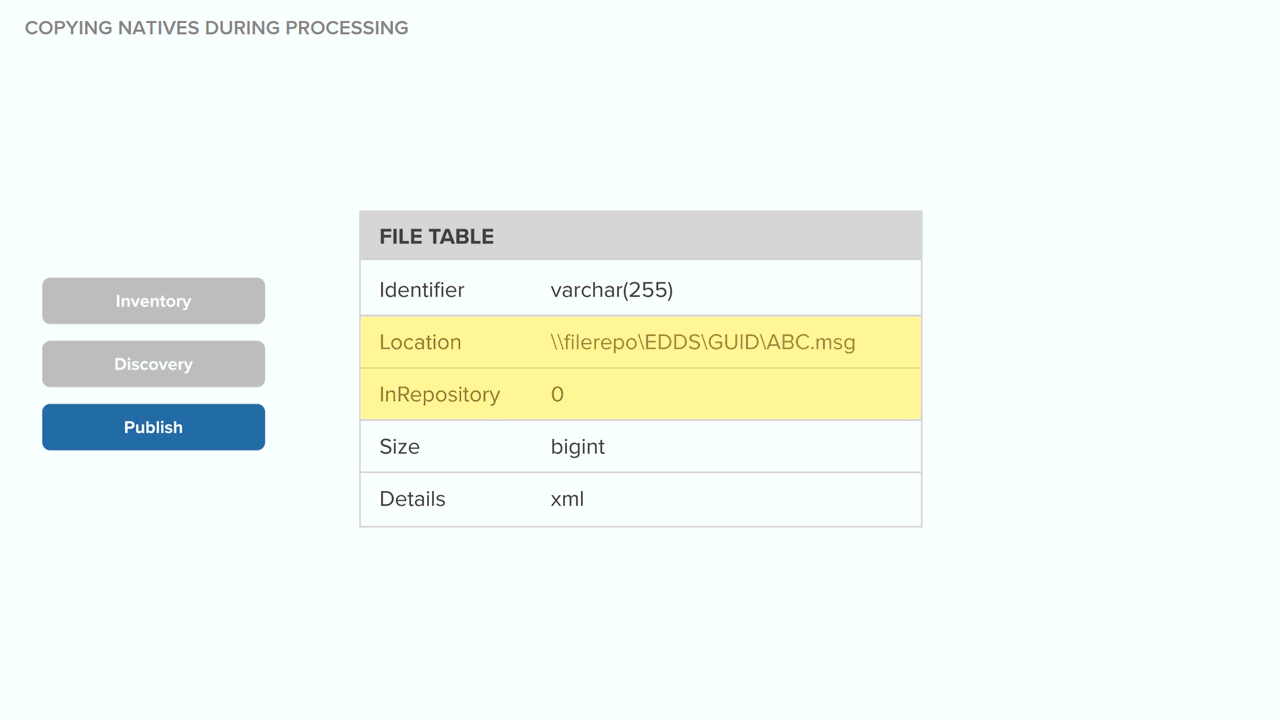
Copying natives during processing
To gain a better understanding of the storage implications of copying natives during processing, note the behavior in the following example.
When you process a PST file containing 20,000 unique total documents while copying natives:
- You copy the PST from the original source to your Processing Source Location, as this is the identified location where Relativity can see the PST. Note that you can make the original source a processing source by opening the original source to Relativity.
 If you run Inventory on this set, Relativity will identify all parents and attachments, but it will only extract metadata on the parent email.
If you run Inventory on this set, Relativity will identify all parents and attachments, but it will only extract metadata on the parent email.- The EDDS12345\Processing\ProcessingSetArtifactID\INV12345\Source\0 folder displays as the original PST.
- Relativity begins to harvest individual MSG files in batches and processes them. If an MSG has attachments, Relativity harvests files during discovery and places them in the queue to be discovered individually. Throughout this process, the family relationship is maintained.
- Relativity discovers the files, during which the metadata and text are stored in Relativity Processing SQL.
- Relativity publishes the metadata from the Relativity Processing SQL Datastore to the Review SQL Datastore and imports text into the text field stored in SQL or Relativity Data Grid. This metadata includes links to the files that were harvested and used for discovery. No additional copy is made for review.
- Once processing is complete:
- You can delete the processing source PST.
- You can delete the PST file in the EDDS folder, assuming there are no errors.You can't automate the deletion of files no longer needed upon completion of processing. You need to delete this manually.
- You should retain files harvested during processing, as they are required for review.
The following graphic depicts what happens behind the scenes when the system copies native files to the repository during processing. Specifically, this shows you how the system handles the data source and EDDS repository across all phases of processing when that data source isn't considered permanent.
This graphic is designed for reference purposes only.