






Feedback
Last date modified: 2026-Jul-14
Import/Export load file specifications
A load file is used to transfer data and its associated metadata into a database. During import, the application reads the load file to determine what metadata should be written into each field and to copy it to the workspace. If your organization uses a processing vendor, you need to upload case data with a load file. You will also use load files when you receive a subset of data from another party, such as a production from opposing counsel.
Below are the load file specifications for Import/Export.
Supported file types
Import/Export supports the following file types.
- ZIP and PST files—for transferring data to the server-side.
- Native files for processing—see the list of supported file types for processing.
- Document Load File import—.dat, .csv, and .txt load files.
- Image Load File import—Opticon-formatted page-level files. Supported formats: single page TIFF (Group IV) files, single page JPG files, and single and multiple PDF files.
- Access DB load file import—.mdb or .accdb. For more information, see Access DB (MDB) load file specifications.
In RelativityOne you can restrict specific file types from being imported into their instances with the RestrictedFileTypes instance setting. Import/Export reads and applies this instance setting when importing materials into RelativityOne, therefore, skips all file types listed as restricted file types.
Import/Export web only accepts the following file types:
For Unstructured Processing Jobs
- PST—individual Entity and Custodian files
- ZIP containers:
- All loose files must be in a ZIP container
- Entity and Custodian identifier must be at the folder level
For Load Files and Structured Data Sets
- Load file—keep the Load File in .dat, .opt, or other format, separate from zipped documents
- Files—Native or Image/Production files must be in a ZIP container
Metadata, extracted text, and native files
Import/Export uses a flat, document-level load file to load metadata, document level extracted text, and natives files. Each line should represent one document.
Import/Export requires consistent line breaks, that is, end-of-line (EOL) characters, throughout the load file. Mixing line endings, such as UNIX (LF), Mac (LF), and Windows (CRLF), can cause errors or unexpected behavior during import. To ensure smooth processing, use only one type of line break in the entire file.
Encoding
- Arabic (ASMO 708)
- Arabic (ISO)
- Arabic (Windows)
- Baltic (ISO)
- Baltic (Windows)
- Central European (ISO)
- Central European (Windows)
- Chinese Simplified (GB18030)
- Chinese Simplified (GB2312)
- Chinese Traditional (Big5)
- Cyrillic (DOS)
- Cyrillic (ISO)
- Cyrillic (KOI8-R)
- Cyrillic (KOI8-U)
- Cyrillic (Mac)
- Cyrillic (Windows)
- Estonian (ISO)
- Greek (ISO)
- Greek (Windows)
- Hebrew (ISO-Logical)
- Hebrew (ISO-Visual)
- Hebrew (Windows)
- Japanese (EUC)
- Japanese (JIS 0208-1990 and 0212-1990)
- Japanese (JIS)
- Japanese (JIS-Allow 1 byte Kana - SO/SI)
- Japanese (JIS-Allow 1 byte Kana)
- Japanese (Shift-JIS)
- Korean
- Korean (EUC)
- Latin 3 (ISO)
- Latin 9 (ISO)
- Thai (Windows)
- Turkish (ISO)
- Turkish (Windows)
- Ukrainian (Mac)
- Unicode (UTF-16)
- Unicode (Big-Endian)
- Unicode (UTF-8)
- US-ASCII
- Vietnamese (Windows)
- Western European (ISO)
- Western European (Mac)
- Western European (Windows)
Header row
Import/Export does not require load file header rows. However, they are strongly recommended to ensure accuracy. The field names in your header do not need to match the field names in your workspace.
Fields
RelativityOne does not require any specific load file field order. You can create any number of workspace fields to store metadata or coding. During the load process, you can match your load file fields to the fields in your workspace. The identifier field is required for each load. When loading new records, this is your workspace identifier.
When performing an overlay, you can use the workspace identifier or select another field as the identifier. This is useful when overlaying production data. For example, you could use the Bates number field rather than the document identifier in the workspace.
All fields except Identifier are optional.
- Identifier—the unique identifier of the record.
- Group Identifier—the identifier of a document’s family group.
- The group identifier repeats for all records in the group.
- Usually, this is the document identifier of the group’s parent document. For example, if an email with the document identifier of AS00001 has several attachments, the email and its attachments have a group identifier of AS00001.
- If a group identifier for a record is not set, the document identifier populates the group identifier field in the case. This effectively creates a “group” of one document.
- MD5 Hash—the duplicate hash value of the record.
- You can enter any type of hash value, and rename the field in your case.
- If documents share the same hash value, the software identifies the documents as a duplicate group.
- If a hash field for a record is not set, the document identifier populates the hash field in the case. This effectively creates a “group” of one document.
- Extracted Text—the text of the document. Either the OCR or Full Text. The extracted text appears in the viewer and is added to search indexes. This field can contain either:
- The actual OCR or Full Text.
- The path to a document level text file containing the OCR or Full Text. Both relative and absolute (full) paths are supported. However, to import load file data that contains absolute paths, you must activate Express Transfer. Relative paths can start with Blank or .\, as in: MainFolder\SubFolder\File.extension or .\MainFolder\SubFolder\File.extension. Absolute paths can start with a backslash (\), as in: \MainFolder\SubFolder\File.extension.
- Native File Path—the path to any native files you would like to load. Both relative and absolute (full) paths are supported; however, to import load file data that contains absolute paths, you must activate Express Transfer. Relative paths can start with Blank or .\, as in: MainFolder\SubFolder\File.extension or .\MainFolder\SubFolder\File.extension. Absolute paths can start with a backslash (\), as in: \MainFolder\SubFolder\File.extension.
- To avoid import errors, run a load file precheck using the Pre-check Load File button. This process validates whether the native file paths are correct and that linked native files exist and are accessible.
- Currently, the application does not check if duplicate native file paths exist in the load file. Therefore, you may want to manually review your load file data to ensure there are no duplicated file paths before starting an import job. Duplicated native file paths do not cause import errors, but may lead to billing consequences.
- Folder Info—builds the folder browser structure for the documents.
- This field is backslash “\” delimited.
- If not set, the documents load to the root of the case.
- Each entry between backslashes is a folder in the system's folder browser.
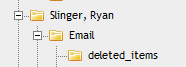
- Each backslash indicates a new sub-folder in the browser. For example, if the load file contains the following entry in the folder information field, “Slinger, Ryan\Email\deleted_items”, the software builds the following folder structure. Each document with the above entry is stored in the “deleted_items” folder.
- Relativity Native Time Zone Offset—numeric field in decimal format that applies a time zone offset to date/time values displayed in the Native Viewer, such as the Sent Date/Time in email headers.
- If the field value is blank or 0, no offset is applied, and the date/time is displayed in Coordinated Universal Time (UTC).
- The field accepts whole or fractional numbers, positive or negative, to represent the desired offset from UTC. For example, “-5”, “5.5”, “-6.0”. To display time in India Standard Time (IST), enter “5.5” because IST is UTC+5:30. If you want to display time in Central Time for Chicago, use “-6.0” for standard time or “-5.0” if Daylight Saving Time (CDT) is in effect.
- The value should account for any Daylight Saving Time (DST) adjustments based on the document’s date and the intended time zone. The Native Viewer does not automatically adjust for DST.
- This offset only affects how date/time values appear in the Native Viewer. Metadata fields and extracted text are displayed exactly as imported.
Accepted date formats
RelativityOne accepts date and time as one field. For example, Date Sent and Time Sent should be one field. If date sent and time sent ship separately, you must create a new field for time. You can format date fields to accept the date without the time, but not the time without the date. Dates cannot have a zero value. Format dates in a standard date format such as “6/30/2023 1:23 PM” or “6/30/2023 13:23”.
To import or export data with a date/time format that differs from the US format, be sure to select the correct Regional Settings option when creating a new Import/Export job.
The table below lists the date formats recognized by Import/Export and Import Service (IAPI). It contains both valid and invalid date formats.
| Entry in Load File | Object Type | Definition |
|---|---|---|
| Monday January 4 2023 | 1/4/2318 0:00 | |
| 05/28/2023 7:11 AM | 05/28/2023 7:11 AM | |
| 5.08:40 PM | 6/30/2023 17:08 | The current date will be entered if the date is missing. For this example, assume the import was done on 6/30/2023. |
| 17:08:33 | 6/30/2023 17:08 | The current date will be entered if the date is missing. For this example, assume the import was done on 6/30/2023. |
| 17:08 | 6/30/2023 17:08 | The current date will be entered if the date is missing. For this example, assume the import was done on 6/30/2023. |
| 5:08 PM | 6/30/2023 17:08 | The current date will be entered if the date is missing. For this example, assume the import was done on 6/30/2023. |
| 14-Apr | 4/14/2023 0:00 | The current year will be entered if the year is missing. |
| 9-Apr | 4/9/2023 0:00 | The current year will be entered if the year is missing. |
| 14-Mar | 3/14/2023 0:00 | The current year will be entered if the year is missing. |
| 1-Mar | 3/1/2023 0:00 | The current year will be entered if the year is missing. |
| 22-Feb | 2/22/2023 0:00 | The current year will be entered if the year is missing. |
| 20230420 | 4/20/2023 0:00 | |
| 20230420 2:22:00 AM | 4/20/2023 0:00 | |
| 4/9/2023 16:13 | 4/9/2023 16:13 | |
| 4/9/2023 8:49 | 4/9/2023 8:49 | |
| 9-Apr-23 | 4/9/2023 0:00 | |
| Apr. 9, 23 | 4/9/2023 0:00 | |
| 4.9.2023 | 4/9/2023 0:00 | |
| 4.9.23 | 4/9/2023 0:00 | |
| 4/9/2023 | 4/9/2023 0:00 | |
| 4;9;2023 | 4/9/2023 0:00 | |
| Wednesday, 09 April 2023 | 4/9/2023 0:00 | |
| 12-31-2023 | 12/31/2023 12:00 AM | |
| 2023-11-28T17:45:39.744-08:00 | 11/28/2023 0:00 | |
| 4/9/23 13:30 PM | Results in an error | |
| 2023-044-09 | Results in an error | |
| 4/9/2023 10:22:00 a.m. | Results in an error | |
| 00/00/0000 | Results in an error |
Delimiters
During import, you can choose which delimiters are used in your load file. You can select each delimiter from the ASCII characters, 001 – 255.
The delimiter characters have the following functions:
- Column—separates load file columns.
- Quote—marks the beginning and end of each load file field. It is also known as a text qualifier.
- Newline—marks the end of a line in any extracted or long text field.
- Multi-value—separates distinct values in a column. This delimiter is only used when importing into a RelativityOne multi-choice field.
- Nested-values—denotes the hierarchy of a choice. This delimiter is only used when importing into a RelativityOne multi-choice field.
For example, a load file contains the following entry, and is being imported into a multi-choice field: “Hot\Really Hot\Super Hot; Look at Later”,
with the multi-value delimiter set as “;” and the nested value delimiter set as “\"”, the choices appears in RelativityOne as: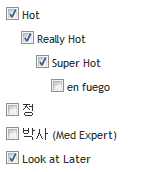
All checkboxes are automatically selected under each nested value. You must provide the full path to each multi-choice element. For example:
| DocID |
New Privilege |
|---|---|
|
NZ997.001.00000048 |
04. Redact;01. Yes\b. Solicitor/Client; |
appears as:
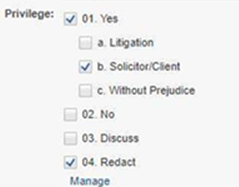
To select "01. Yes/a. Litigation," add it to the record after ";".
Default delimiters
If you generate your own load files, you may choose to use the system defaults:
- Column—Unicode 020 (ASCII 020 in the application)
- Quote—Unicode 254 (ASCII 254 in the application)
- Newline—Unicode 174 (ASCII 174 in the application)
- Multi-Value—Unicode 059 (ASCII 059 in the application)
- Nested Values—Unicode 092 (ASCII 092 in the application)
ZIP archive with extracted text and natives
To import any text or native file when not using Express Transfer, you need to zip the files and upload the zip file in the Choose Load File And Location dialog in Import/Export. The zip file structure can be either flat or hierarchical with multiple levels of sub-folders. You must ensure that file paths in the related load file match the zip file's structure. The following image shows a sample hierarchical zip file structure and a matching load file.
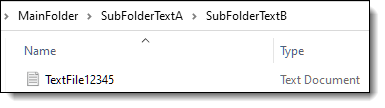
^Control Number^|^Extracted Text^|^Native File^
^DOCUMENT_12345^|^MainFolder\SubFolderTextA\SubFolderTextB\TextFile12345.txt^|^MainFolder\SubFolderNatives\NativeFile12345.xls^
Image and extracted text files
For image imports, Import/Export uses Opticon load files that reference the Control ID on a page level. The first page should match up to any data you intend to load. The same process applies when importing page‑level extracted text. You should save these .opt files using UTF‑8 encoding. You must convert images in unsupported formats using a third‑party conversion tool before Import/Export can successfully upload them.
Supported image file formats
Import/Export accepts only the following file types for image loads:
- Single page, Group IV TIF (1 bit, B&W)
- Single page JPG
- Single page PDF
- Multi page PDF
- Multi page TIF can be imported into the system, but you must load them as native files.
- Only one PDF per document is supported.
Load file format
The Opticon load file is a page-level load file in which each line represents one image.
A sample of Opticon load file is the following:
REL00001,REL01,D:\IMAGES\001\REL00001.TIF,Y,,,3
REL00002,REL01,D:\IMAGES\001\REL00002.TIF,,,,
REL00003,REL01,D:\IMAGES\001\REL00003.TIF,,,,
REL00004,REL01,D:\IMAGES\001\REL00004.TIF,Y,,,2
REL00005,REL01,D:\IMAGES\001\REL00005.TIF,,,,
The fields are, from left to right:
- Field One (REL00001)—page identifier.
- Field Two (REL01)—volume identifier; not required and not used in Import/Export.
- Field Three (D:\IMAGES\001\REL00001.TIF)—path to the image to be loaded.
- Field Four (Y)—document marker: “Y” indicates the start of a unique document.
- Field Five (blank)—used to indicate a folder; not required and not used in Import/Export.
- Field Six (blank)—used to indicate a box; not required and not used in Import/Export.
- Field Seven (3)—used to store page count; not required and not used in Import/Export.
ZIP archive with images
To import images when not using Express Transfer, you need to zip the image files and upload the zip file in the Choose Load File And Location dialog in Import/Export. The zip file structure can be either flat or hierarchical with multiple levels of sub-folders. You must ensure that image file paths in the related load file match the zip file's structure.
Importing extracted text during an image load
You can also import extracted text during the image import process by setting a relevant option in Import/Export.
Processed data
Some data originates from client files and needs processing to extract the metadata. The following table shows the delimiters that your internal processing software must use to present data as fields.
| Value | Character | ASCII Number |
|---|---|---|
| Column | ¶ | 020 |
| Quote | þ | 254 |
| Newline | ® | 174 |
| Multi-Value | ; | 059 |
| Nested Value | \ | 092 |
You can provide this list to your vendor to help communicate the required delivery format for load files. You should deliver the fielded data as delimited files with column or field names located in the first line.
Supported transcript file types
Import/Export only supports these transcript file types: .ptf, .xmptf, .rtf, .txt, .trn, and .lef. See Uploading transcripts for more information on transcripts.
Multiple references to the same native file
Import/Export supports load files that reference the same native, image, or text file across multiple documents. When importing with Express Transfer enabled, the file is uploaded only once and linked to documents based on the load file configuration. Each reference is counted individually for billing purposes.
You can run Pre-check Load File process to identify duplicated references to the same files before starting an import job. This validation helps you review potential data issues early and decide whether to proceed with the import as configured.
During the Pre-check Load File process, the system scans the load file for cases where the same file path is referenced more than once. When duplicated references are detected, Pre-check does not block the import, but it surfaces the findings as warnings displayed in the Warnings tab that appears in the Pre-check results.

This tab provides detailed information to help you understand where and how duplicates occur in your load file, including:
- Name of the load file column that contains the duplicated reference
- Number of occurrences for each duplicated file
- Duplicated file path as specified in the load file
You can use this information to verify whether the duplicated references are expected, for example, for intentional reuse of the same file across multiple documents, or whether the load file should be corrected before running the import.