






Feedback
Last date modified: 2026-Jun-30
Analyzing aiR for Review results
When aiR for Review analyzes documents, it makes predictions about the relevance of documents to different topics or issues. If it predicts that a document is relevant or relates to an issue, it includes a written justification of that prediction, as well as a counterargument and in-text citations. You can view these predictions, citations, and justifications either from the Viewer, or as fields on document lists.
Additionally, you can export the results to view data offline, share it with others, and compare information. See Exporting analysis results for details.
How aiR for Review analysis results work
After analyzing a document, aiR for Review provides a Prediction, a Score with recommendations on how to categorize the document, and the supporting Rationale for prediction. You can use this information to help update and improve your prompt criteria.
This analysis has several parts:
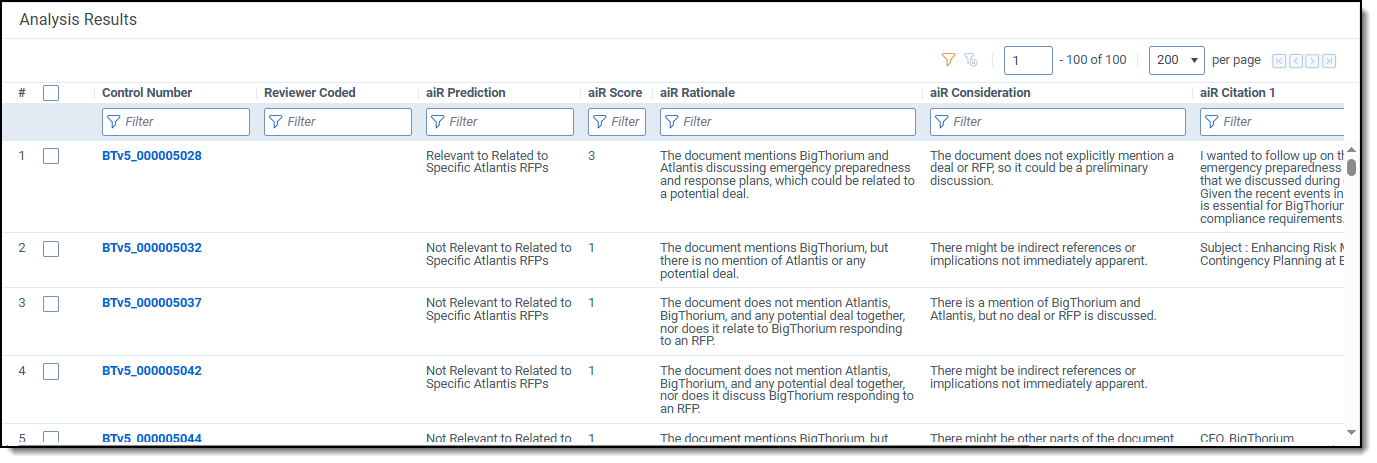
- aiR Prediction—the relevance, key, or issue label that aiR predicts should apply to the document. See Predictions versus document coding
- aiR Score—a numerical score that indicates how strongly relevant the document is or how well it matches the predicted issue. See Understanding document scores.
- aiR Rationale—an explanation of why aiR chose this score and prediction.
- aiR Consideration—aiR is asked to argue against itself, identifying what assumptions it's making or additional facts that could reverse the prediction.
- aiR Citation—excerpts from the document that support the prediction and rationale. For the Relevance and Relevance and Key Documents analysis types, a maximum of five citations will be presented per document. For the Issues analysis type, only one citation will be shown for each issue.In general, citations are left empty for non-relevant documents and documents that do not match an issue. However, aiR occasionally provides a citation for low-scoring documents if it helps to clarify why it was marked non-relevant. For example, if aiR is searching for changes of venue, it might cite an email that ends with "Hang on, gotta run, more later" as worth noting, even though it does not consider this a true change of venue request.
Predictions versus document coding
Even though aiR refers to the relevance, key, and issue fields during its analysis, it does not actually write to these fields. It is not coding the documents or writing to the coding fields. All of aiR's results are stored in aiR-specific fields, such as the Prediction field. This makes it easier to compare aiR's predictions to human coding while refining the prompt criteria.
If you have refined a set of prompt criteria to the point that you are comfortable adopting those predictions, you can copy those predictions to the coding fields using mass-tagging or other methods.
For ideas on how to integrate aiR for Review results into a larger review workflow, see Using aiR for Review with Review Center.
Document summaries
The Summaries tab in the document grid displays a descriptive topic and summary of each document. These remain the same for each document across all projects, regardless of analysis type chosen. They are not affected by the project settings, analysis type, prompt criteria, or other documents.
The generated columns are:
- aiR Topic—the descriptive topic aiR generated for this document.
- aiR Content Summary—the summary aiR generated for this document’s content.
These columns may populate either faster or slower than the analysis results. For more information on document summaries, see Generating document summaries.
- Document summaries and descriptive topics cannot be generated without running one of the analysis types.
- Document summaries do not affect the number of aiR Units used. For more information on aiR Units and billing, see aiR Units in RelativityOne standard workspaces and aiR Units, Thresholds, and Included Products on the Community (valid login credentials required).
- Because of data processing locations, document summaries are opt-in only for RelativityOne instances in France, Germany, Ireland, and the Netherlands. For more details or to opt in, contact your account representative.
Documents with an empty summary field
If the document has minimal content or unintelligible text, the aiR Topic will be “Poor Quality Content,” and it will not have an aiR Content Summary. Re-analyzing these documents will return a similar result.
If there is no content for either the aiR Topic or the aiR Content Summary, this means an error occurred when generating them. These errors are rare, and they do not affect whether the main document analysis succeeded. For more information, see How document errors are handled.
Custom insight analyses results
Once the analyses completes, each custom insight displays as individual columns in the Analysis Results table and in a dedicated Custom Projects card within the Viewer.
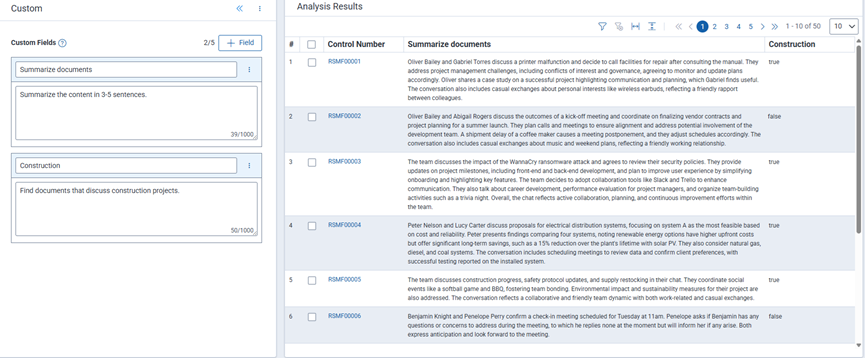
Click on the Control Number link to open the document in the Viewer.
If an error displays for an insight, see How document error are handled in Custom analyses for guidance.
If you modify custom insights, change the data source, or create a new project set, only the updated insights will re-run on the next analyses.
Understanding document scores
aiR scores documents from 0 to 4 according to how relevant they are or how well they match an issue. The higher the number, the more relevant the document is predicted to be.
A score of -1 is assigned to any errored documents. They cannot receive a normal score because they were not properly analyzed.
Below are the aiR for Review scores:
| Score | Description |
|---|---|
| 4 | Highly Relevant: The document is predicted very relevant to the issue. aiR found direct, strong evidence that the content relates to the case or issue. Citations show the relevant text. |
| 3 | Relevant: The document is predicted relevant to the issue. Citations show the relevant text. |
| 2 | Borderline Relevant: The document is predicted borderline relevant. aiR found some content that might relate to the case or issue. It usually has citations. |
| 1 | Not Relevant: The document is predicted not relevant. aiR did not find any evidence that it relates to the case or issue. |
| 0 |
Junk: (For aiR versions below 2026-04-14) The document contains no useful information or is considered “junk” data, such as system files, an empty document, or sets of random characters. Refer to the aiR for Review Jobs tab for the aiR version used for the job. Highly Not Relevant:(For aiR versions 2026-04-14 and above) The document either contains no useful information or is predicted highly not relevant to the case or issue. Refer to the aiR for Review Jobs tab for the aiR version used for the job. |
| -1 | Error: The document either encountered an error or could not be analyzed. For more information, see How document errors are handled. |
How document errors are handled
If aiR encounters a problem when analyzing a document, it will not return results for that document. Instead, it scores the document as -1 and returns an error message in the Error Details column. Your organization is not charged for any errored documents, and they do not count towards your organization's aiR for Review total document count.
For information on errors when using Custom analyses, see How document error are handled in Custom analyses.
The possible error messages are:
| Error message | Description | Retry? |
|---|---|---|
| Completion is not valid JSON | The aiR system encountered an error. | Yes |
| Failed to parse completion | The aiR system encountered an error. | Yes |
| Document text is empty | The extracted text of the document was empty. | No |
| Document text is too long | The document's extracted text was too long to analyze. | No |
| Document text is too short | There was not enough extracted text to analyze in the document. | No |
| Model API error occurred | A communication error occurred within the aiR system. This is usually a temporary problem. | Yes |
| Uncategorized error occurred | An unknown error occurred. | Yes |
| Ungrounded citations detected in completion | The results for this document have a chance of including an ungrounded citation. For more information, see Ungrounded citations. | Yes |
If the Retry? column says Yes, you may get better results trying to run that same document a second time. For errors that say No in that column, you will always receive an error running that specific document.
If you retry a document and keep receiving the same error, the document may have permanent problems that aiR for Review cannot process.
In rare cases, there may be an error generating the document's topic or summary. As long as the main document analysis succeeded, these are not considered errored documents. An error in the aiR Topic or aiR Content Summary field does not affect any of the other results.
You can re-run the document to try for better results, but the document will be charged normally.
Variability of results
Due to the nature of large language models and how they analyze each document individually, output results may vary slightly from one run to another, even using the same inputs. aiR's scores may shift slightly, typically between adjacent levels, such as from 1-not relevant to 2-borderline. Significant changes, like moving from 4-very relevant to 1-not relevant, are rare. Similarly, when running prompts on Custom Analyses, tweaks to prompts between different iterations will result in different responses for those insights. For more information on variability of results, see the Community article, Why might aiR for Review (a4R) results change even when using the same prompt?
Ungrounded citations
An ungrounded citation may occur for two reasons:
- When the aiR results citation cannot be found anywhere in the document text. This is usually caused by formatting issues. However, just in case the LLM is citing sentences without a source, we mark it as a possible ungrounded citation.
- When the aiR results citation comes from something other than the document itself, but which is still part of the full prompt. For example, it might cite text that was part of the prompt criteria instead of the document's extracted text.
When aiR receives the analysis results from the LLM, it checks all citations against the prompt text. Any possible ungrounded citations are marked as errors, and they receive a score of -1 instead of whatever score they were originally assigned. If retrying documents with these errors does not succeed, we recommend manually reviewing them instead.
Actual ungrounded citations are extremely rare. However, highly structured documents, such as Excel spreadsheets and .pdf forms, are more likely to confuse the detector and trigger these errors.