






Feedback
Last date modified: 2026-Feb-05
Sentiment analysis
Sentiment analysis is an artificial intelligence tool that scores documents on the likelihood that they contain negativity, anger, desire, or other emotions. Through this analysis, you can quickly and easily locate documents that show unusual or highly charged interactions between participants.
By detecting unusual communications between key actors, you can locate communications that need further investigation and build deeper context around the conversations and ideas that are central to a case or matter.
See these related pages:
Other related articles:
Installing Sentiment Analysis
Sentiment Analysis is not installed by default in new workspaces, but it is included in some workspace templates. If you choose to install it yourself, it is available as a secured application from the Application Library.
To install it:
- Navigate to the Relativity Applications tab in your workspace.
- Select Install from application library.
- Select the Sentiment Analysis application.
- Click Install.
After installation completes, the following tabs will appear in your workspace:
- Sentiment Analysis Jobs—shows status and other information for each sentiment analysis job.
- Sentiment Results—shows detailed results for each document analyzed.
Installing Sentiment Analysis also adds the Detect Sentiment mass operation to your workspace. To make this mass operation available to user groups, see Sentiment analysis security permissions.
For more information on installing applications, see
Running sentiment analysis
Running sentiment analysis involves three basic steps:
- Choose the document set.
- Run the mass operation.
- Review results.
Before you begin, make sure you have the right permissions. See Sentiment analysis security permissions.
Sentiment analysis is not currently supported in ECA workspaces.
Choosing the document set
When setting up a sentiment analysis project, we recommend that you:
- Use preselected document sets—instead of running sentiment analysis on all documents in a workspace together, run it on smaller, more focused saved searches.
- Consider processing time—running sentiment analysis on large documents can cause jobs to take a long time to complete. To improve speed, focus on emails and smaller documents.
- Include only English documents—because sentiment analysis works specifically in English, we recommend running language identification first and excluding non-English documents. For more information, see Running structured analytics.
If you have a very large set of documents to analyze, break it into smaller groups. You can divide these up in any way that makes sense for reviewers, such as by custodian or date.
Use the following size limits as guidelines when grouping documents:
- Document count—300,000 maximum.
- Document size—5MB maximum for the Extracted Text field.
After deciding how to divide your documents, create saved searches for each group. For more information, see Create and edit a saved search.
Running the sentiment analysis mass operation
To run the sentiment analysis mass operation:
- From the document list, select the saved search you want to analyze.
- Open the Mass Operations menu and choose Detect Sentiment.
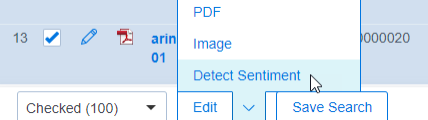
- In the options pop-up, check the sentiments you want to analyze.
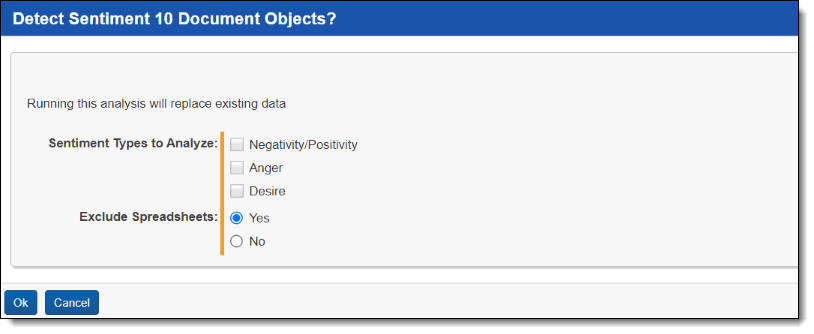
- Under Exclude Spreadsheets, select Yes or No. We recommend choosing Yes to improve performance.
- Click Ok.
This starts the analysis and brings you to a progress screen. After the job has been queued up for processing, it will automatically bring you back to the document list.
Re-running sentiment analysis
If you have previously run sentiment analysis on a document, running it again will overwrite some older results:
- If the document does not have results yet for a newly analyzed sentiment, those results will be added.
- If the document already has results for a specific sentiment, those results will be replaced with the newest results for the same sentiment.
Example 1
Scenario: A document already has results for Anger, and you run sentiment analysis on Desire.
Result: The document will have results for both Anger and Desire. The old Anger results are kept, and the new Desire results are added.
Example 2
Scenario: A document already has results for both Anger and Desire, and you run sentiment analysis on Anger.
Result: The new Anger results will overwrite the old Anger results. The old Desire results will stay the same.
Reviewing sentiment analysis results
Sentiment analysis results appear in several places:
- Document list—you can view basic results directly in the document list by adding more columns.
- Sentiment Results tab—shows detailed results for each document.
- Sentiment Analysis Jobs tab—shows status and other information for each sentiment analysis job.
For detailed information on viewing these results, see Sentiment analysis results.
Common ways to use sentiment analysis
Sentiment analysis speeds up the review process in key ways:
- Detecting unusual communications—see when participants have suddenly shifted their tone of communication, or see trends over time.
- Prioritizing review—quickly identify documents to batch and send to reviewers based on their proximity to charged communications.
These benefits can be helpful for any case or investigation, but are particularly helpful for certain types of investigations such as:
- Employee relations—investigating matters such as harassment, wrongful termination, or discrimination.
- Exfiltration—investigating matters such as IP theft or leaving with a book of business.
- Fraud—investigating matters such as embezzlement.
How sentiment analysis works
Sentiment analysis looks at the content of a document and predicts which sentences contain certain emotions, or “sentiments,” by analyzing the words that were used. It runs on a sentence-by-sentence level, and it assigns each sentence a set of confidence scores that show the likelihood of a specific sentiment being present. The sentiments it looks for include negativity, positivity, desire, and anger. The higher the score, the higher the chances of that sentiment being present.
If you use sentiment analysis to detect multiple sentiments, it will assign a separate confidence score for each sentiment. For example, analyzing negativity and anger will give you an anger confidence score and a negativity confidence score for each sentence in the document. It will also provide document-level information such as the number of sentences in the document predicted to have a specific sentiment, and it will list sentences with higher scores.
When sentiment analysis runs, it:
- Runs on a sentence level—each document is broken up into sentences for the AI engine to analyze, with a maximum of 1000 characters per sentence. If a sentence has no words to analyze or contains only special characters, it will not receive a score.
- Stop words such as “a” and “the” are ignored.
- Brief, one- or two-word positive phrases such as “yes,” “love you,” “thank you,” and "best regards" are ignored. These phrases are often used for politeness, greetings, or email signatures. Brief phrases with other sentiments, such as "this stinks," still receive a score.
- Runs on the Extracted Text field—if you want to analyze text contained in an OCR field or another field, transfer the text to the Extracted Text field.Before replacing the text in the Extracted Text field, consider how this will affect other parts of review. For example, if you redacted documents before running OCR, the OCR text will not include redacted text.
- Analyzes each sentiment separately—each sentiment being analyzed receives a separate score.
- Analyzes each sentence's content, not its surroundings—the scores are based only on words contained in each sentence. They are not affected by surrounding sentences, other documents, or metadata.
The sentiment predictions are not affected by:
- Capitalization
- Punctuation or special characters
- Stop words such as “a” and “the”
- Brief, one- or two-word positive phrases such as "greetings" or "best regards"
- Images or emoji
- Document metadata such as the file name or date modified
Predictions versus certainty
Sentiment analysis makes predictions about what sentiments are in a sentence, but those predictions are not guarantees. Even if a sentence has a high confidence score for a specific sentiment, the actual sentiment of the sentence could be different after taking into consideration the surrounding context, culture, slang, sarcasm, and many other factors.
The final evaluation of whether a sentiment is present should be done by a human being, regardless of how high or low a confidence score is. For more information, see Best practices for interpreting results.
How emails are analyzed
When analyzing emails, sentiment analysis treats them as follows:
- Only email bodies are analyzed—sentiment analysis does not look at headers or footers.
- All body text is analyzed—sentiment analysis looks at body text from all segments, including replies and quoted text. It does not check whether text is inclusive or non-inclusive before scoring it.
Sentiment list
Sentiment analysis looks for the following sentiments:
- Negativity—generally includes critical or pessimistic statements. This is calculated at the same time as positivity, but the confidence scores are shown separately.
- Example 1: “Hope you guys don't flake out.”
- Example 2: “I feel so bad leaving her.”
- Example 3: “He's such a push over.”
- Positivity—generally includes approving or optimistic statements. This is calculated at the same time as negativity, but the confidence scores are shown separately.
- Example 1: “I just got my dream job and I couldn't be more excited.”
- Example 2: “Love makes everything better.”
- Example 3: “The beauty of nature never ceases to amaze me.”
- Desire—statements that involve wanting something or wishing for something to happen.
- Example 1: “That would be perfect! Wish I had that.”
- Example 2: “This just makes me want sushi.”
- Example 3: “I really need to get more sleep.”
- Anger—statements that involve feelings of annoyance, displeasure, or hostility.
- Example 1: “What an idiot.”
- Example 2: “I hate you.”
- Example 3: “Shut up [NAME]”
“Negative” sentiment does not necessarily mean a statement is bad or wrong. For example, "I hate discrimination" and "I hate diversity" are both negative statements, but with very different meanings. Likewise, "positive" sentiment does not necessarily mean a statement is good or ethical; "I love my friends" and "I love theft" are both positive.
Language and culture considerations
Because sentiment is expressed differently across languages, regions, cultures, generations, and circumstances, there is no such thing as a universally applicable sentiment analysis model. Every sentiment analysis tool works best when it is used on documents from the same language and culture as the documents used to train the model.
Relativity's sentiment analysis tool uses a machine learning model trained on thousands of samples of English-language text from multiple countries. It is designed only for use with English-language documents.
The sentiment analysis model is designed for use with English-language text, and it has not been trained on the variations in tone and wording that can occur with translation from other languages.
Because translation removes a great deal of cultural and linguistic context, sentiments in translated text can be especially easy to misinterpret. Use caution when running sentiment analysis on translated text, and consult reviewers who are familiar with the original language and culture.
Although the sentiment analysis model was trained on samples from a variety of countries, the samples do not equally represent all cultures or modes of speech. When looking through sentiment predictions, consider how these may affect what was said:
- Cultural differences—cultures express emotion in different ways, even when they speak the same language. Differences in word choice, intensity of expression, and politeness standards are among the factors that can affect or mislead analysis.
- Regional differences—the meaning of words and commonly used expressions can change from one region to another.
- Membership in a group—some words are used neutrally or affectionately among members of a minority or cultural group, but are considered an insult if said by outsiders.
- Age and gender—communication patterns vary among different age groups and genders. For example, use of the ellipsis ("...") in messages is sometimes considered passive-aggressive by young people, but neutral by people who are older.
- Humor and sarcasm—people may use words that are offensive and negative in a joking way, or words that are overly polite and positive in a sarcastic way. Sentiment analysis does not detect sarcasm or joke context.
- Contextual cues such as images or emoji—surrounding context can completely change the meaning of a statement. Currently, sentiment analysis does not parse images, emoji, or document metadata.
Addressing bias in sentiment analysis
When a machine learning model produces results that systematically favor or harm specific subjects, this is referred to as bias. All machine learning models have errors, and if those errors favor or disfavor a specific group, using that model can lead to unequal treatment or unfair outcomes.
Relativity's sentiment analysis model has been designed to reduce bias. In particular, we have trained the model to treat all terms referring to protected classes—gender, sexual orientation, religion, race, nationality, age, and disability status—as neutral. As a result, statements such as "I don't trust [protected class]" will be scored similarly regardless of which protected class is mentioned.
Debiasing is an ever-evolving effort, and Relativity will continue to test the model against bias and maintain this work on an ongoing basis.
Best practices for interpreting results
When interpreting sentiment analysis results, use the following best practices:
- Use human judgment—have a human review the results to find nuance and evaluate context.
- Treat scores as predictions, not verdicts—sentiment analysis scores are estimates, not certainties.
- Consider linguistic and cultural context—educate reviewers on cultural, linguistic, and demographic factors that may affect the scores. For more information, see Language and culture considerations.
- Consider document context—sentences with low sentiment scores may have counterclaims or provide context that changes the course of the review. Pay attention to context within the document and to related documents, even if they have low sentiment scores, and use other review tools such as concept search to find additional related documents.
Ultimately, sentiment analysis is a tool for finding potential documents of interest. What those documents mean to an investigation and whether they are relevant remains up to human judgment.