






Feedback
Last date modified: 2026-Jun-22
Processing duplication workflow
The Processing Duplication Workflow is a way to identify and mark duplicate documents after discovery. This way you can review only one copy of each document, while leaving all copies of the document in place across the workspace. You can control how documents are published through the processing profile selected when creating a processing set. You can also create your own processing profile, then choose the deduplication method (global, custodial, or none) to use.
- Global deduplication—documents that are duplicates of documents that were already published to the workspace in a previous processing set aren't published again. For more information, see Deduplication considerations > Global deduplication.
- Custodial deduplication—documents that are duplicates of documents owned by the custodian specified on the data source aren't published to the workspace. For more information, see Deduplication considerations > Custodian deduplication.
- No deduplication—all documents and their duplicates are published to the workspace. For more information, see Deduplication considerations > No deduplication.
The scripts described on this page help identify duplicate files and their source locations. Use the scripts if you have deduplication set to No Deduplication or are working with files uploaded outside of Relativity. You should not use these scripts if you are running deduplication within Relativity processing.
Downloading and installing the solution to your instance
Before you begin, confirm you have the Processing Duplication Workflow application in your environment's application library. If you do, you can skip to section, Adding the solution to a workspace. If not, download the solution from the Community site, then deploy it to your environment. After it's deployed, you can add it to any workspaces within your environment.
Supported versions
Click the following link to access the solution files on the Community site.
Some versions of this application may not be eligible for support by Relativity Customer Support. For more information, see the Version support policy.
| Solution version | Supported Relativity version |
|---|---|
| 2024.2.0.1 | All supported versions of Relativity. |
You must have valid Relativity Community credentials to download files from the Community site. After accessing the ProcessingDuplicationWorkflow page, click the Download tab. If the file successfully downloads to your local drive, you will not see any other dialog. If you see an error stating "URL No Longer Exists," it may be due to a single sign-on error related to the SAML Assertion Validator, and you should contact your IT department.
Components
This custom solution consists of the following components:
- The Processing Duplication Workflow application.
- Item-level and family-level scripts that run at the workspace level. The scripts are described in greater detail in the Before you run the scripts section. They include:
- All Custodians (item-level and family-level)
- All Source Locations (item-level and family-level)
- Update Duplicate Status (item-level and family-level)
Considerations
- This script should only be run by a system administrator. If you are not a system administrator, you should not run this script.
- The solution may require you to create fields in your environment. Be sure to read the section Before you run the scripts to confirm you have the necessary fields and saved searches in place.
- You have the option of tagging a document as Responsive and then propagating that value to the document’s family members. For more information, see Applying propagation to documents.
Deploying and configuring the solution
After downloading the solution from the Community site, you must deploy it to your environment's Application Library.
To deploy the solution to your environment:
- Use the search bar to navigate to your environment's Application Library.
- Click the New Library Application button.
- Next to Application File, click Select File.
- Navigate to and select the ProcessingDuplicationWorkflow.rap file you downloaded from the Community site.
- Click the Save button.
Adding the solution to a workspace
The Processing Duplication Workflow solution is already deployed to all RelativityOne instances. To install the solution on a workspace, perform the following:
- Use the search bar to navigate to the Application Library in the Admin environment.
- Use the Name filter to locate the Processing Duplication Workflow application.
- Select the application to open the application information page
- Locate the Workspaces Installed section and click Select.
- Use the Workspace filter to locate your target workspace(s), then use the Move Selected Left to Right arrow to lock in your selection(s).
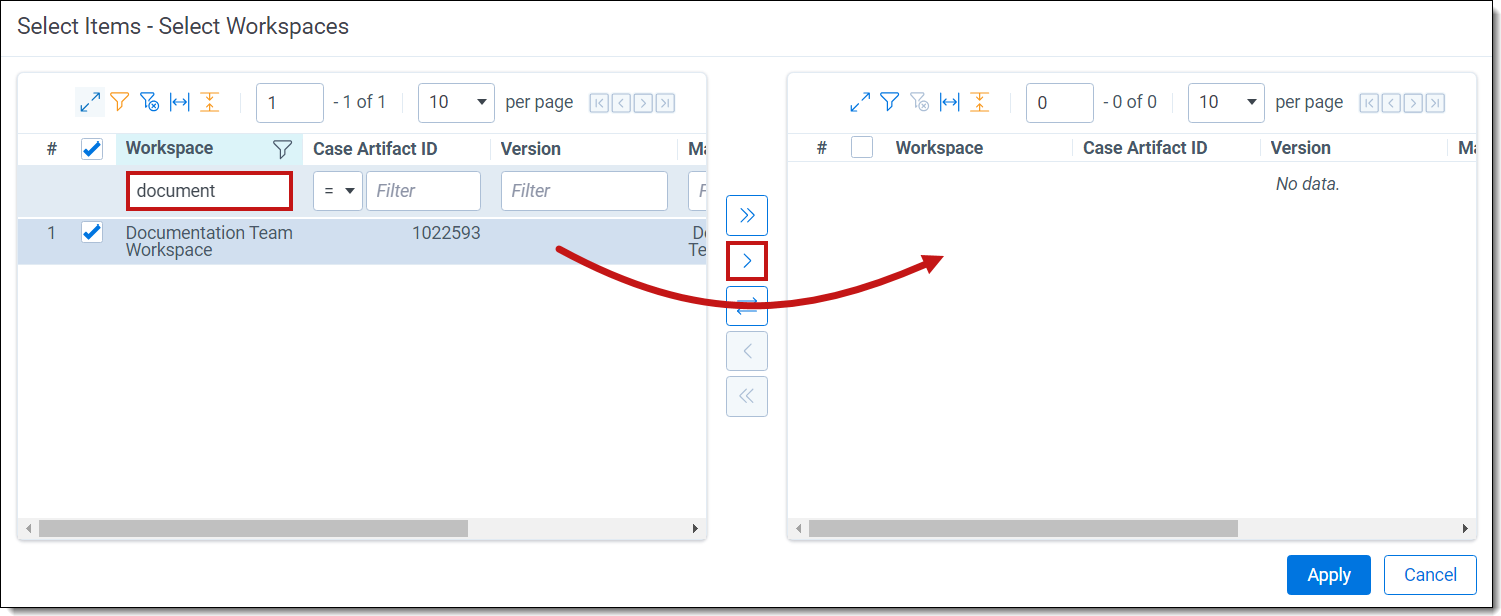
- Click Apply.
You are redirected back to the Workspaces Installed screen. When the installation complete, you should see your workspace with a status of Installed.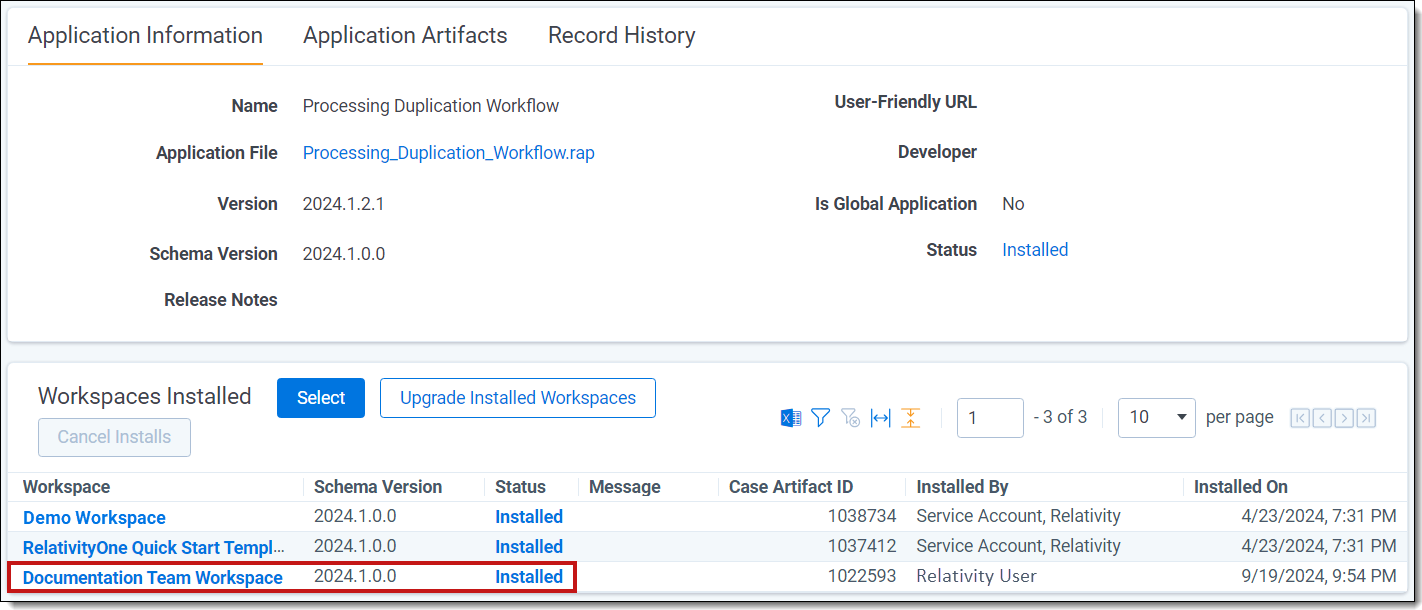
Before you run the scripts
To avoid delays later, take a few minutes to confirm you have the prerequisites required by the scripts. These include required fields, populated entities, and saved searches. If you have one or more missing items, create them now before proceeding.
Fields
The following is a list of all the fields used in the Processing Duplication Workflow scripts, along with their equivalent Relativity fields. We recommend you confirm that the Relativity field equivalents exist before proceeding. If they do not, use the field type and associative objects to create them.
| Field name in script | Relativity field equivalent | Used in script | Field type | Associative Object | Field purpose |
|---|---|---|---|---|---|
| Saved Search | [Your Saved Search Name] | All scripts | Single Object |
Search |
This field serves two purposes. First, it defines the data set you want to run the script against. Second, Relativity updates the fields with the results of the script after you run it. You can create one saved search for both item-level and family-level scripts since the results output have the same fields for both. |
| Custodian Object | Custodian | All Custodians - Item All Custodians - Family |
Single Object | Entity | The custodian associated with a file. More than one custodian can be associated with a single file. |
| Custodian Object Field | Full Name | All Custodians - Item All Custodians - Family |
Fixed-Length Text (255) | Entity | This processing field displays the first and last name of the custodian. |
| Destination Field (output) | All Custodians (Long Text) | All Custodians - Item All Custodians - Family All Source Locations - Item All Source Locations - Family |
Long Text | Document | When used with the All Custodians scripts, this field displays a semi-colon delimited list of all custodians associated with a file. |
| Destination Field (output) | All Paths/Locations | All Custodians - Item All Custodians - Family All Source Locations - Item All Source Locations - Family |
Long Text | Document | When used with the All Source Locations scripts, this field displays a semi-colon delimited list of the source locations for a file. |
| Duplicate Hash Field | Processing Duplicate Hash or EDRM MIH. See the EDRM MIH topic for more information on using the EDRM hash. |
All scripts | Fixed-length Text (64) | Document | The identifier of the physical native file. Alternatively, you can select another hash field in it's place, such as MD5 or SHA1. |
| Duplicate Sort Order Field | Custodian Sort Order | Update Duplicate Status - Item Update Duplicate Status - Family |
Whole Number | Entity | This is an option field that when selected, sorts the script results according to the custodian sort order rank. To use this field, you must manually assign a sort order value to the custodians in your saved search. See Other considerations for details on how to assign a sort order to custodians. |
| Duplicate Status Field | Duplicate Status or EDRM Duplicate Status See the EDRM MIH topic for more information on using the EDRM hash. |
Update Duplicate Status - Item Update Duplicate Status - Family |
Single Choice | Document | Displays one of three values: Unique, Master, or Duplicate based on the relational field (hash.) Unique files have a relational ID not shared with any other files. Master files have a relational ID shared by more than one file where the ID is the lowest of the files. Duplicate files have a relational ID shared by more than one file where the IDs are not the lowest in the files. |
| Family Identifier Field | Family Group | All Custodians - Family All Source Locations - Family Update Duplicate Status - Family |
Fixed-Length Text (64) | Document | Identifies the family group a file belongs to. |
| Level Field | Level | All Custodians - Family Update Duplicate Status - Family |
Whole Number | Document | Numeric value that represents how deeply nested a file is within a family. The higher the number, the deeper the file is nested. |
| Source Field | Source Path | All Source Locations - Item All Source Locations - Family |
Long Text | Document | The location of the file in the data set. |
Saved searches
Saved searches have two functions when using the duplication scripts:
- They identify the data set you are running the script against.
- After the script runs, it updates the saved search so that you can identify duplicate documents and their locations.
You can create three saved searches, one for each script type, and use them for both item and family levels.
All custodians
Create a saved search with the following fields:
- Control Number—the document identifier.
- Custodian—the custodian associated with the document.
- Family Group—the relational field that defines groups of related documents.
- All Custodians (Long Text)—the script uses this field to output a semicolon delimited list of custodians associated with the document or relational group (for family-level results).
All source locations
Create a saved search with the following fields:
- Control Number—the document identifier.
- Source Path—the location of the document in the data set.
- Family Group—the relational field that defines groups of related documents.
- Level—the nested level of the document. This field is useful when running the family-level script and tells you how deeply nested the document is.
- All Paths/Locations—the script uses this field to output a semicolon delimited list of source locations associated with the document.
Update duplicate status
Create a saved search with the following fields:
- Artifact ID—the unique identifier of the database object in Relativity.
- Control Number—the document identifier.
- Processing Duplicate Hash—the identifier of the physical native file, such as MD5 or SHA1.
- Custodian—the custodian associated with the document.
- Level—the numeric value that represents how deeply nested a file is within a family. The higher the number, the deeper nested.
- Duplicate Status—the script updates this field with one of the following options: Unique, Master, Duplicate.
Other considerations
Finally, there are a few other housekeeping items to consider.
- Script access and visibility—after installing the Processing Duplication Workflow application, Relativity adds links to the scripts in the workspace's general menu. You can access the menu by clicking the hamburger link at the bottom of the left column. However, if you intend to use the scripts often and want a quicker way to access them, read the section on Enabling the workflow tabs.
- Populated entities—if you uploaded your data from another solution outside of Relativity, you should confirm you have populated entities. If you have imported data from a solution outside of Relativity, read the section on Populating entities for data uploaded outside of Relativity.
- Custodian sort order—(optional) some scripts give you the option of ranking the results based on the custodian's sort order. To use this setting, custodians must have a sort order value, which you manually assign to the custodian's entity object. For example, Custodian A has a sort order of 10, while Custodian B's sort order is 20. If everything else is equal between the two custodians, Custodian A will rank higher in the results than Custodian B, based on the sort order value. If you want to use the sort order to rank custodians, read the section on Setting a custodian's sort order.
During the installation, Relativity creates three new tabs: Processing Duplication Workflow, Processing Item Level Scripts, and Processing Family Scripts. The tabs are not visible in the left-side menu by default.
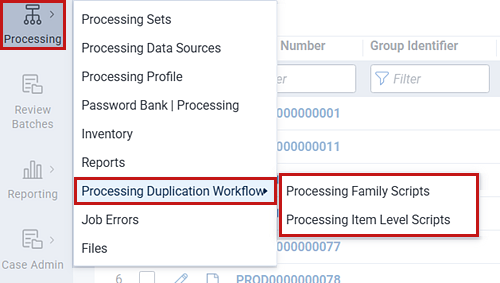
To enable workflow tab visibility:
- Open the workspace where you installed the Processing Duplication Workflow application.
- Use the search bar to navigate to the Tabs page.
- Use the filter on the Name field to locate the processing tabs.
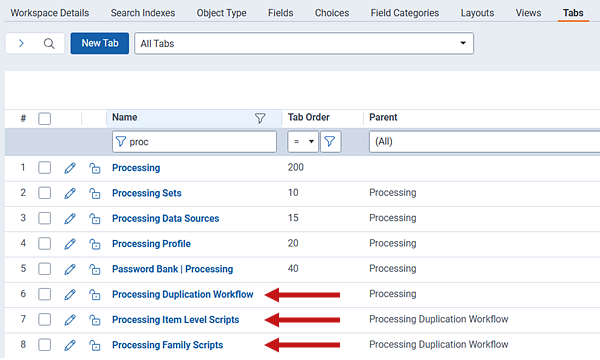
- Edit the Processing Duplication Workflow tab.
- In the Tab Location section, select Processing as the Parent value.
(Optional) Change the Order value to 100. Keep the remaining default values.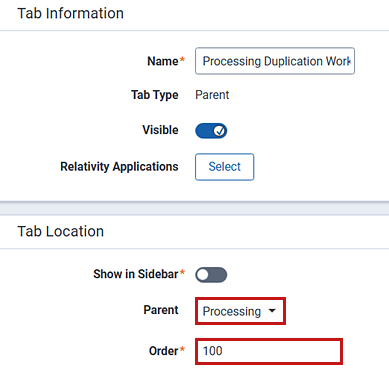
- Click Save and Back to set your changes.
- Edit the Processing Item Level Scripts tab.
- Select Processing Duplication Workflow as the Parent value.
(Optional) Change the Order to 100.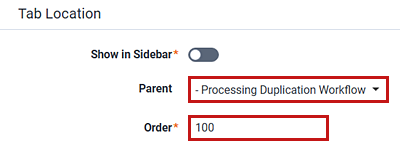
- Click Save and Back.
- Use the preceding steps to enable the Processing Family Scripts tab.
You are now ready to run the solution against a set of documents.
Entities are the individuals communicating within a data set. For example, custodians. When you upload data outside of Relativity, you may not have entities created. If you uploaded data with Relativity, the entities are created automatically. If you do not have any entities, use one of the following methods to create or import them into Relativity:
- Manually create an entity from the Entities tab. For more information, see Creating and editing an entity.
- Load and sync entities with Integration Points. For more information, see Integration Points.
- Load entities with Import/Export. For more information, see Importing entities through Import/Export.
- Run Analytics name normalization to identify entities from email headers. For more information, see Name normalization.
- Manually create a key entity in the Review Interface.
- A key entity is one that has the multi-choice field Classification set to either Key Person or Key Organization on the Entity object.
- These values are set automatically when you create an entity with either one of the respective views (Key People and Key Organization.) For more information, see Case Dynamics.
Use the Custodian Sort Order field to add a sort order value to custodians in your data set. You can use this field in scripts and saved searches to rank results by the field's value. The lower the value, the higher the rank.
To summarize the process of adding the sort value:
- Create a new field based on the Entity object.
- Create a new layout with the new field.
- Edit a custodian and change the layout so you can see the sort order field.
- Add the sort order value and save.
Step-by-step instructions:
- Use the search bar to navigate to the Fields tab.
- Create and save a new field with the following settings:
- Name—Custodian Sort Order
- Object Type—Entity
- Field Type—Whole Number
- Use the search bar to navigate to the Layouts tab.
- Create a new layout with the following settings:
- Object Type—Entity
- Name—Custodian Sort Order Layout
- Order—1000
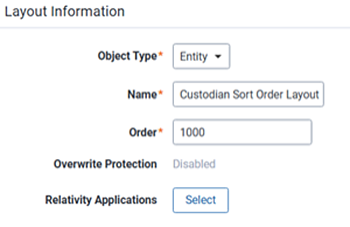
- Click Save.
After you click Save, the screen reloads and the Build Layout button is visible in the Build Layout console on the right side of the screen. - Click the Build Layout button.
- From the list of fields in the Layout Options console, add the Custodian Sort Order field to the layout canvas.
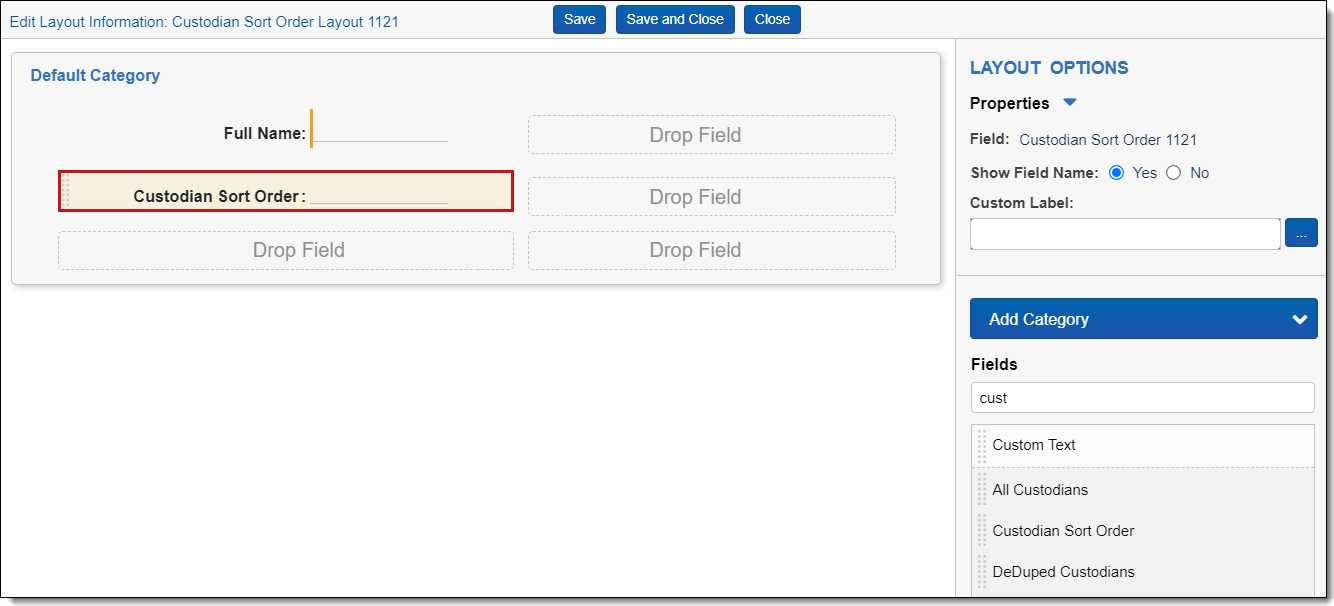
- Click Save and Close.
Next, you will assign a sort order value to the appropriate custodians. - Use the search bar to navigate to the Entities tab.
- Use the filters to find the appropriate custodian record to edit.
- You do not have to assign a sort order value to all custodians. For example, you will create a saved search that defines the data set for the script you are running.
- You might assign sort order values to only the custodians in the saved search to save time.
- Edit a custodian record.
- Change the layout to the Custodian Sort Order Layout.
If you see a message about leaving the page, click OK.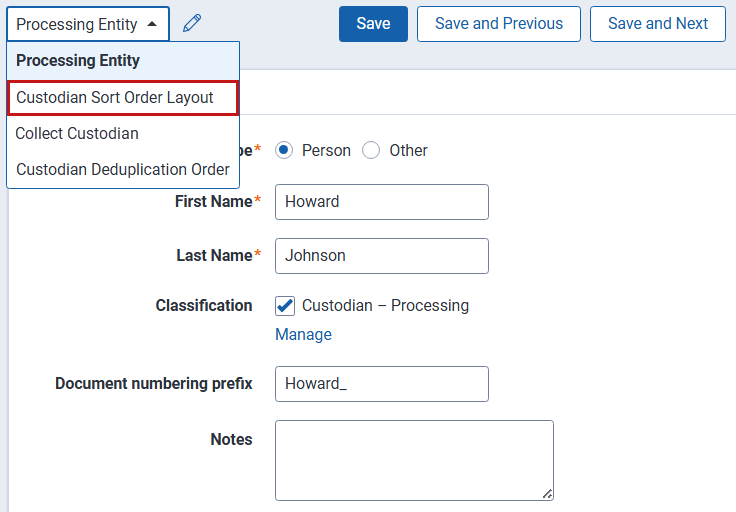
- Add a numeric value for the Custodian Sort Order field.
Lower numbers equate to higher custodian rankings.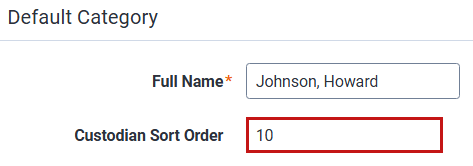
- Click Save and Back.
Repeat these steps for all appropriate custodians.
Next, you will create a new view to display the custodians and their assigned sort order values. You can review the list and confirm the sort order values are correct for your needs.
To create a new view:
- Still on the Entities tab, select New View from the Views drop-down menu.
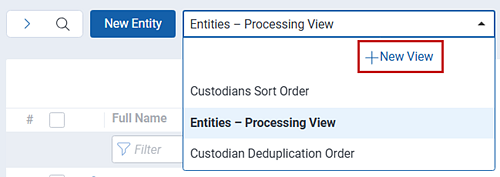
- Name the view Custodian Sort Order View.
- Add the following fields: Full Name, Custodian Sort Order.
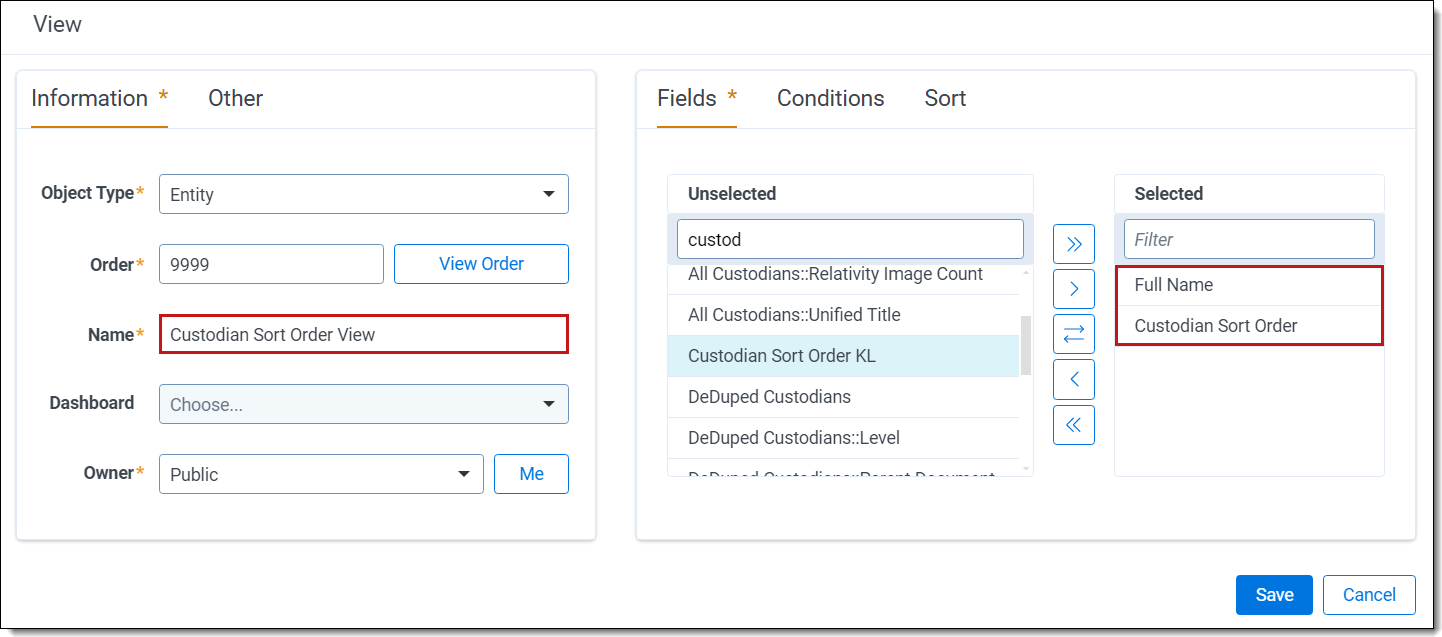
- Click Save to add the view.
- Test the view by selecting the Custodian Sort Order View from the View drop-down menu.
You see a list of all custodians and their sort order assignments. Some custodians may not have a value if you did not assign one.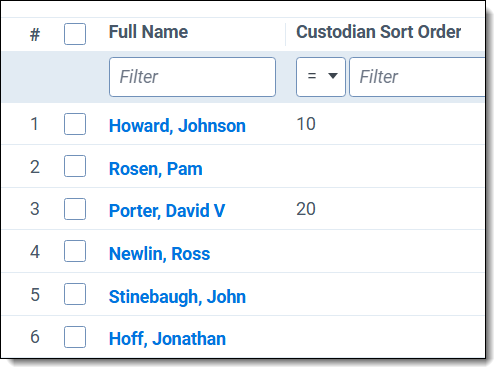
- To view a list of custodians having a sort order assigned, use the filter on the Custodian Sort Order field to eliminate custodians not having an assigned value.
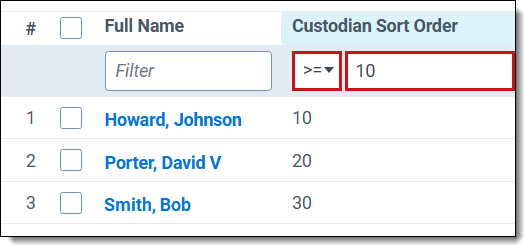
The sort order field is optional in the scripts where it's available. If you choose to map the script field to the Custodian Sort Order field, the script results will display a list based on the custodian sort order rank. The Custodian Sort Order field itself does not appear in the results.
Running the scripts
You can run the processing duplication scripts at the item level or family level. When deciding which level you should choose, consider the following:
- Item level scripts identify all instances of duplicate documents, regardless of email families.
- For example, an email sent to five custodians has one master and four duplicates.
- An Excel file attached separately to two different emails is identified as a duplicate.
- Family level scripts only identify entire duplicate email families, such as an email and its attachments.
- For example, an email sent to five custodians has one master and four duplicates.
- An Excel file attached separately to two different emails is not identified as a duplicate.
For each level, there are three scripts:
- All Custodians—populates a field with a list of all custodians owning a document. Use this script to identify all duplicates in your data set, regardless of family identity. For more information, see All custodians script.
- All Source Locations—identifies source locations for duplicates. Use this script to identify source locations of duplicates. For more information, see All Source Locations script.
- Update Duplicate Status—populates a single-choice field with one of three values: Master, Duplicate, or Unique. Rerunning the script overwrites any existing values. Use this script to update the duplicate status of the document. Running this script at the family level also identifies the level, such as parent or child, of the document. For more information, see Update Duplicate Status script.
All Custodians script
The All Custodians script populates a field with the names of all custodians who own a document (item level) or own a document within a given family (family level). At the family level, the script populates a field with the level of document. For example, a parent document (1) or child (2 or greater). You can use this script to identify duplicates regardless of family. The steps for running the script are similar for the item-level and family-level searches. The instructions below use the item-level UI as a base, with any family script differences highlighted.
To run the All Custodians script:
- Navigate to the Processing Item Level Scripts sub-tab.
- Family-level: Navigate to the Processing Family Scripts sub-tab.
- From the landing page, select the All Custodians (Item Level) option.
- Family-level: Select the All Custodians (Family) option.
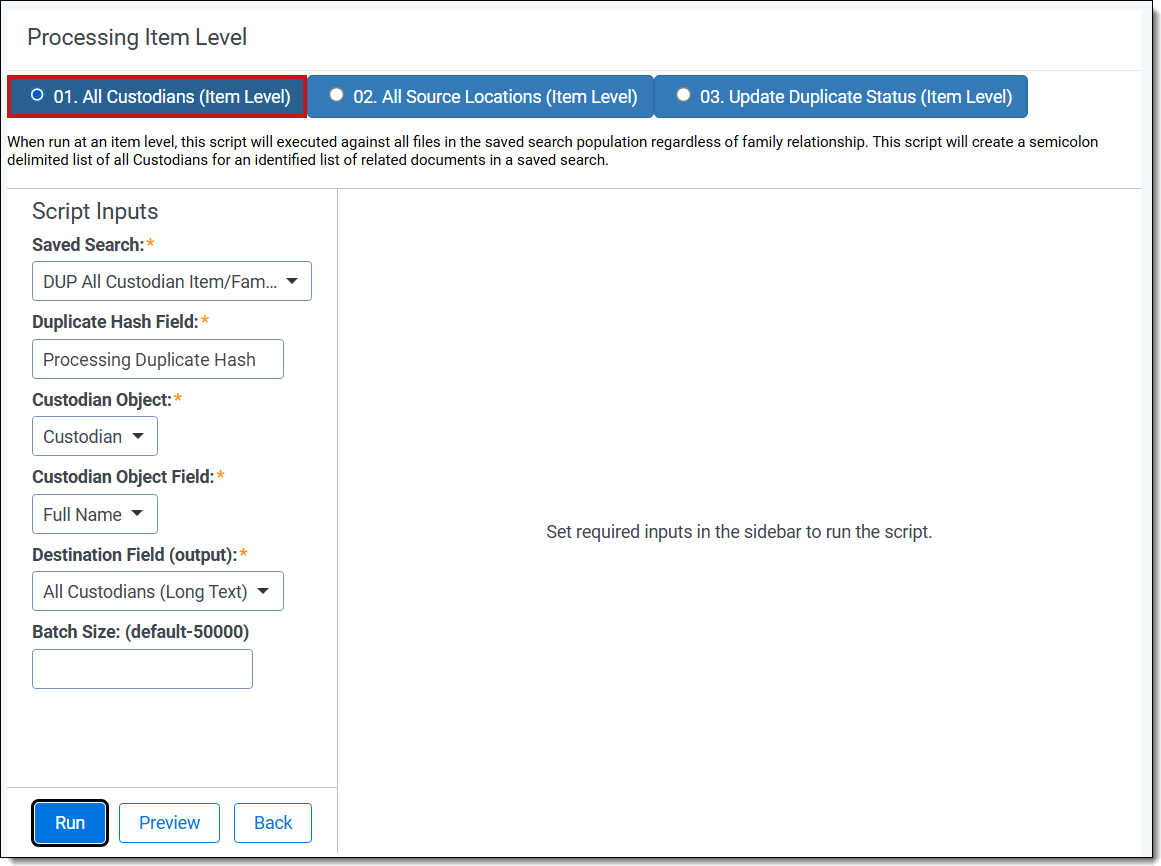
All custodians family-level script
- Complete the following fields:
- Saved Search—select the saved search that has the group of documents to run the script against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another.
- Duplicate Hash Field—select the relational field which defines groups of duplicate documents. For example, MD5, SHA1, or Processing Duplication Hash.
- Family Identifier Field (Family-level only)—select the relational field which defines groups of family documents.
- Level Field (Family-level only)—select the whole number field which defines a numeric value indicating how deeply nested the document is within the family. This is commonly called the Level field if you discovered and published the data through Relativity Processing.
- Custodian Object—select the Custodian object that has your custodian information.
- Custodian Object Field—select the field that has the custodian's full name.
- Destination Field (output)—select the long text field to store the semi-colon delimited list of custodians.
- Batch Size—(Optional—not all product versions have this field.) This field is optional and is the number of files in a saved search batch. Leave this field blank to use the default value of 50,000 or enter a value below 50,000 to increase the script execution speed.
- Click Run.
Viewing the results
Return to the saved search used in the script and refresh the list if necessary.
All custodians item-level script results
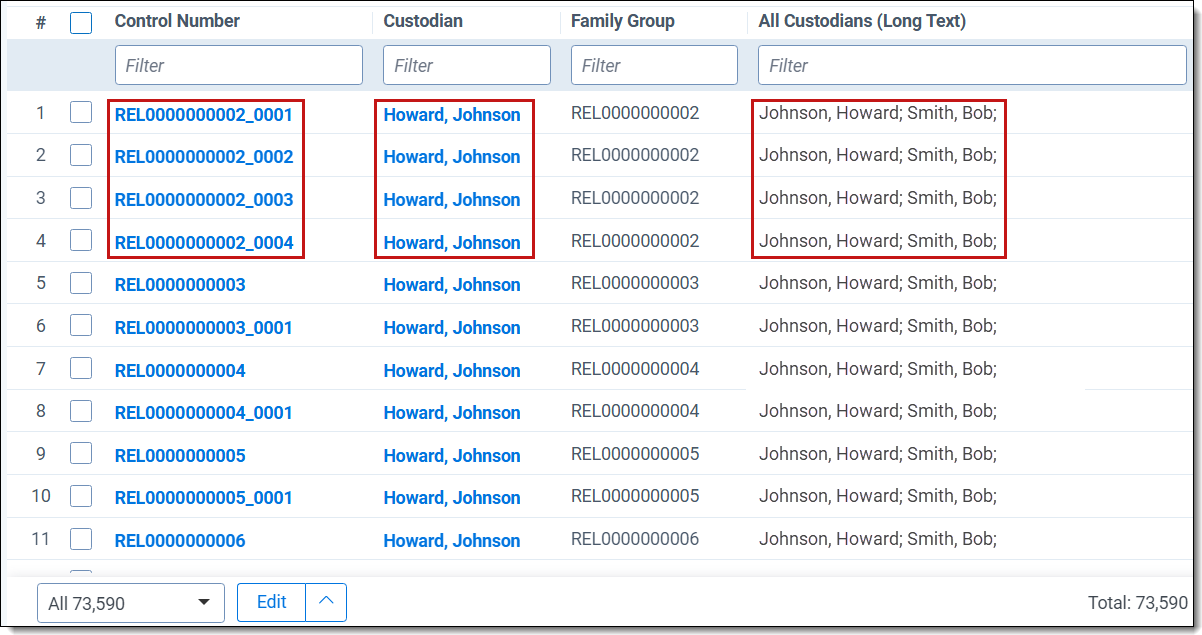
All custodians family-level script results
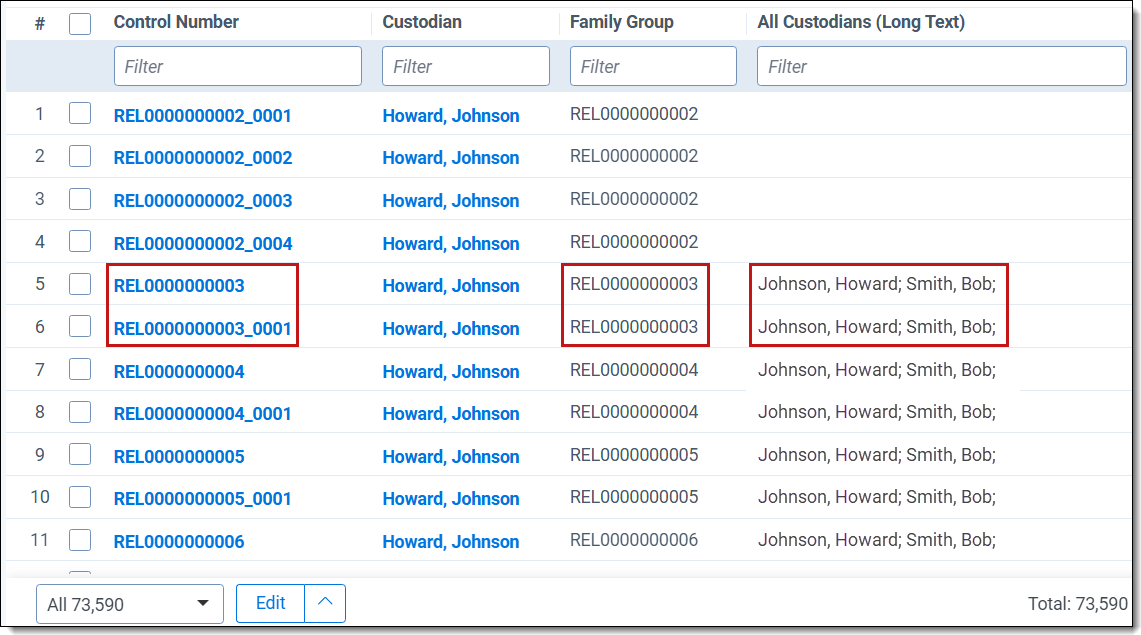
The following table describes the two report results:
| Column | Description |
|---|---|
| Control Number | This is the file's ID. Child documents have an underscore and secondary number that tells you where the file is located within a family. For example, _0003 indicates the file is the third duplicate in the family group. |
| Custodian | The primary custodian associated with the document. The primary custodian is the entity having the lowest Artifact ID where there are more than one custodians associated with a file. |
| Family Group | The relational field that defines groups of related documents. Use this field to identify and filter families of documents. |
| All Custodians (Long Text) | The semi-colon delimited list of all custodians associated with the document or relational group. |
All Source Locations script
The All Source Locations script identifies all source locations for a duplicate document. The steps for running the script are similar for the item-level and family-level searches. The instructions use the item-level UI as a base, highlighting family script differences.
To run the All Source Locations script:
- Navigate to the Processing Item Level Scripts sub-tab.
- (Family-level) Navigate to the Processing Family Scripts sub-tab.
- From the landing page, select the All Source Locations (Item Level) option.
- (Family-level) Select the All Source Locations (Family) option.
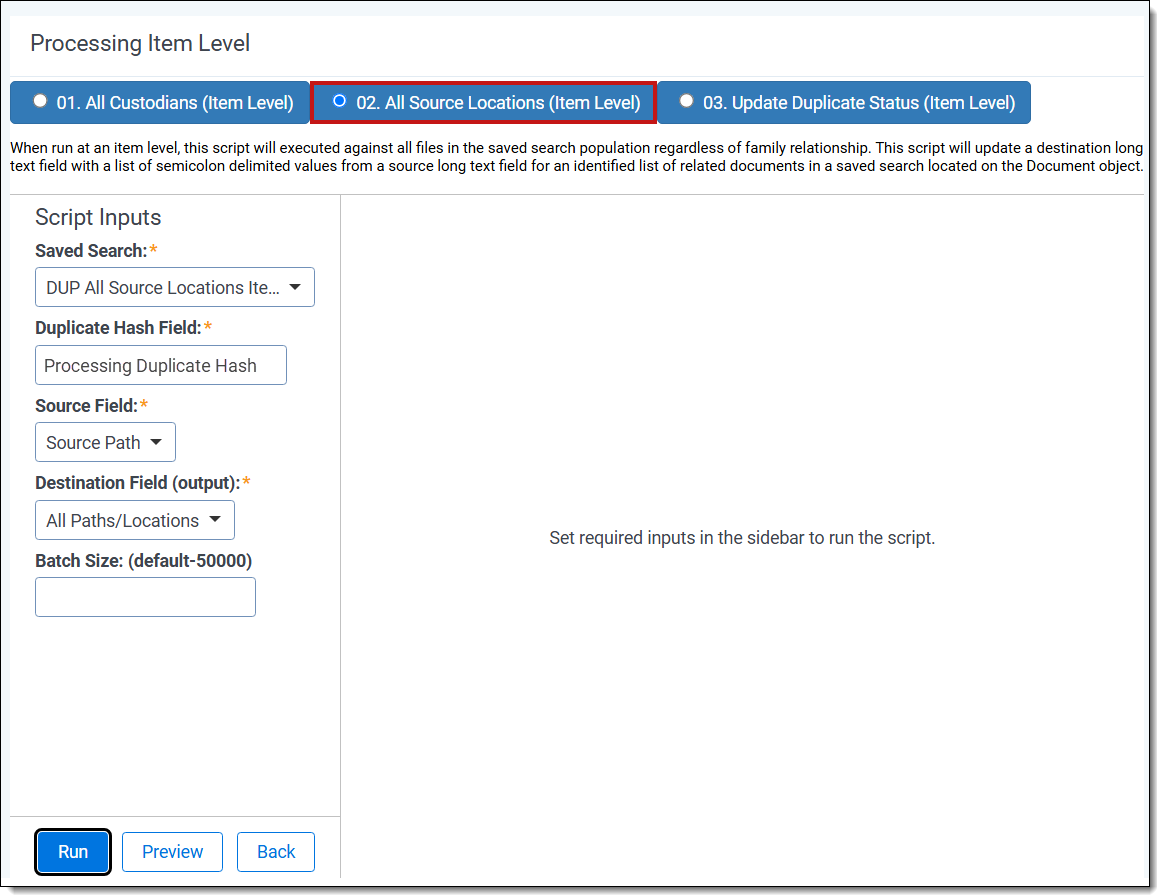
All source locations family-level script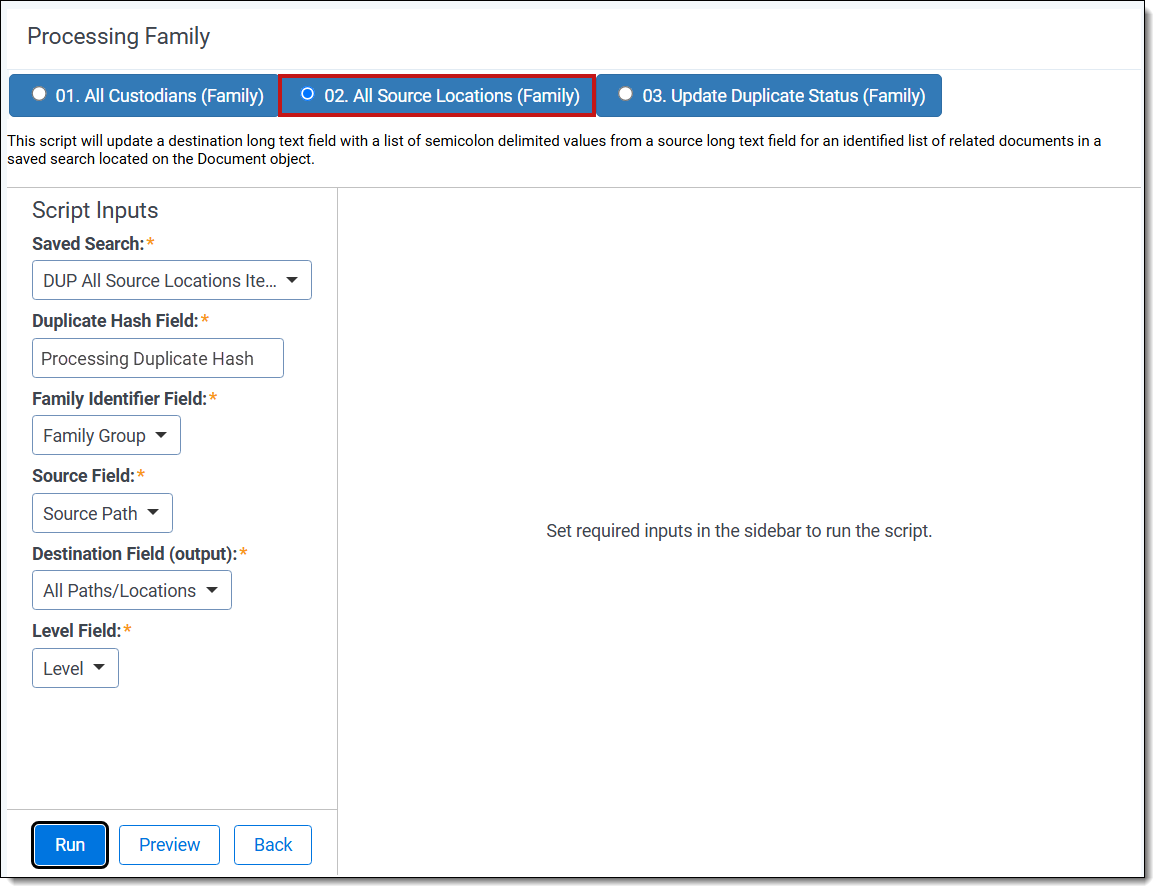
- Complete the following fields:
- Saved Search—select the saved search that has the group of documents to run the script against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another.
- Duplicate Hash Field—select the relational field which defines groups of duplicate documents. For example, MD5, SHA1, or Processing Duplication Hash.
- Family Identifier Field (Family-level only)—select the relational field which defines groups of family documents.
- Source Field—select the long text field that has the source location for documents.
- Level Field (Family-level only)—select the whole number field which defines a numeric value indicating how deeply nested the document is within the family. This is commonly called the Level field if you discovered and published the data through Relativity Processing.
- Destination Field (output)—select the long text field to store the semi-colon delimited list of source paths.
- Batch Size—(Optional—not all product versions have this field.) This field is optional and is the number of files in a saved search batch. Leave this field blank to use the default value of 50,000 or enter a value below 50,000 to increase the script execution speed.
- Click Run.
Viewing the results
Return to the saved search used in the script and refresh the list if necessary.
All source locations item-level script results
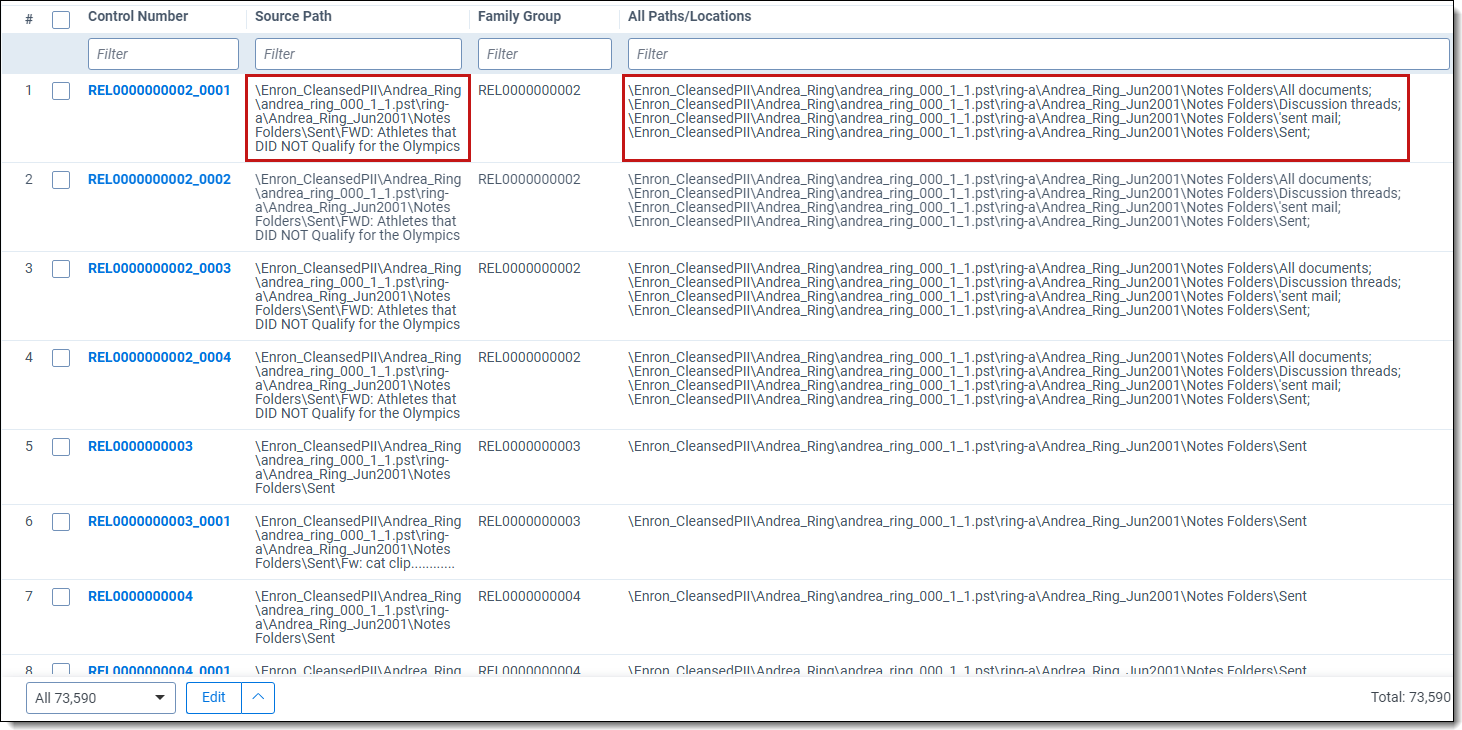
All source locations family-level script results
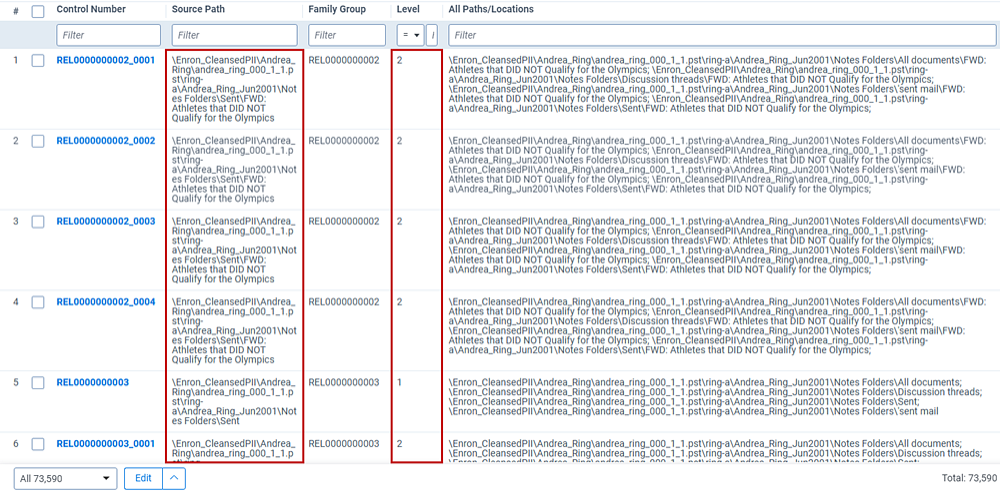
| Column | Description |
|---|---|
| Control Number | This is the file's ID. Child documents have an underscore and secondary number that tells you where the file is located within a family. For example, _0003 indicates the file is the third duplicate in the family group. |
| Source Path | The file location associated with the document. |
| Family Group | The relational field that defines groups of related documents. Use this field to identify and filter families of documents. |
| Level | Use this field value when running the family-level script. This number tells you the nested level of the document. The higher the number, the deeper the document is nested. |
| All Paths/Locations | The semi-colon delimited list of all source locations associated with the document or relational group. |
Update Duplicate Status script
The Update Duplicate Status script assigns a duplicate status value to each document: Unique, Master, or Duplicate. Rerunning the script overwrites any existing values with new values. The steps for running the script are similar for the item-level and family-level searches. The instructions use the item-level UI as a base, highlighting family script differences.
To run the Update Duplicate Status script:
- Navigate to the Processing Item Level Scripts sub-tab.
- (Family-level) Navigate to the Processing Family Scripts sub-tab.
- From the landing page, select the Update Duplicate Status (Item Level) option.
- (Family-level) Select the Update Duplicate Status (Family) option.
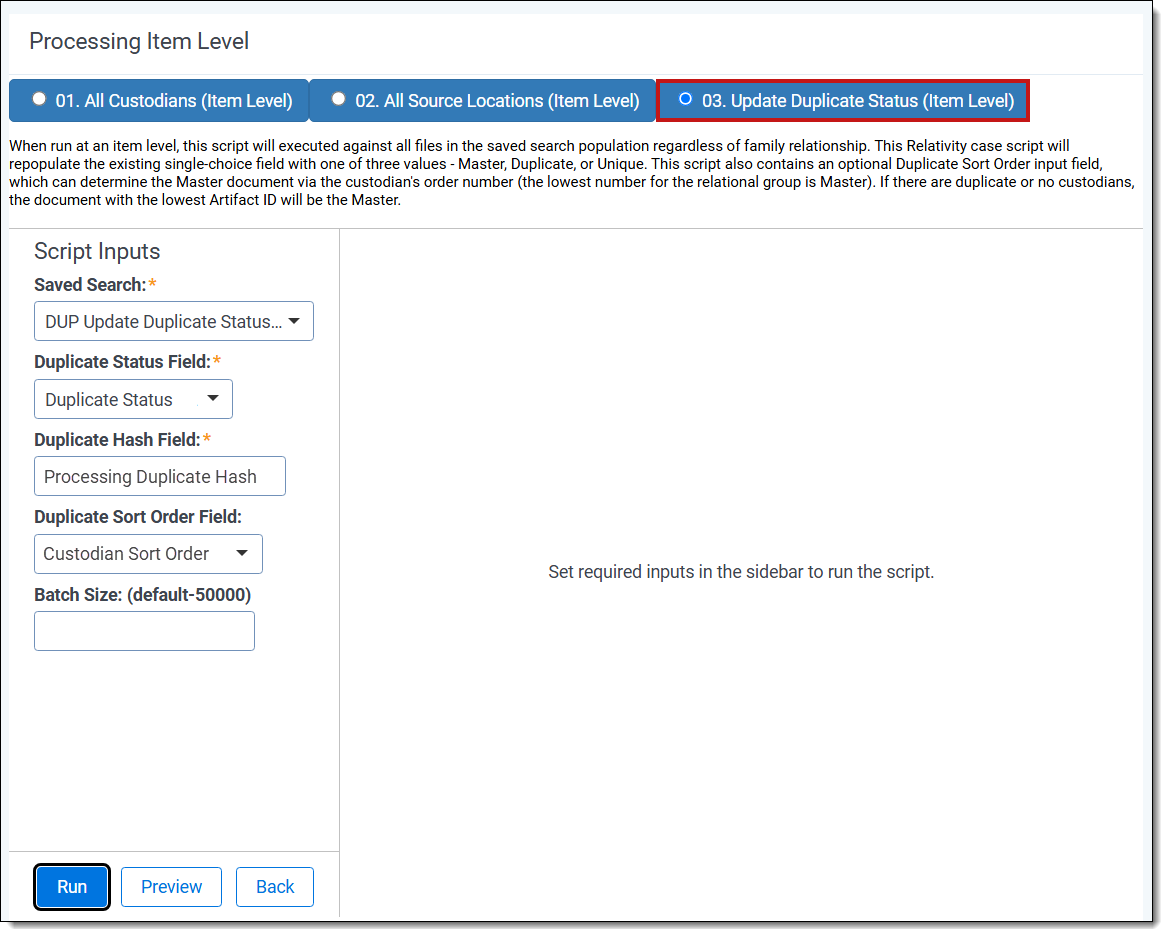
Update duplicate status family-level script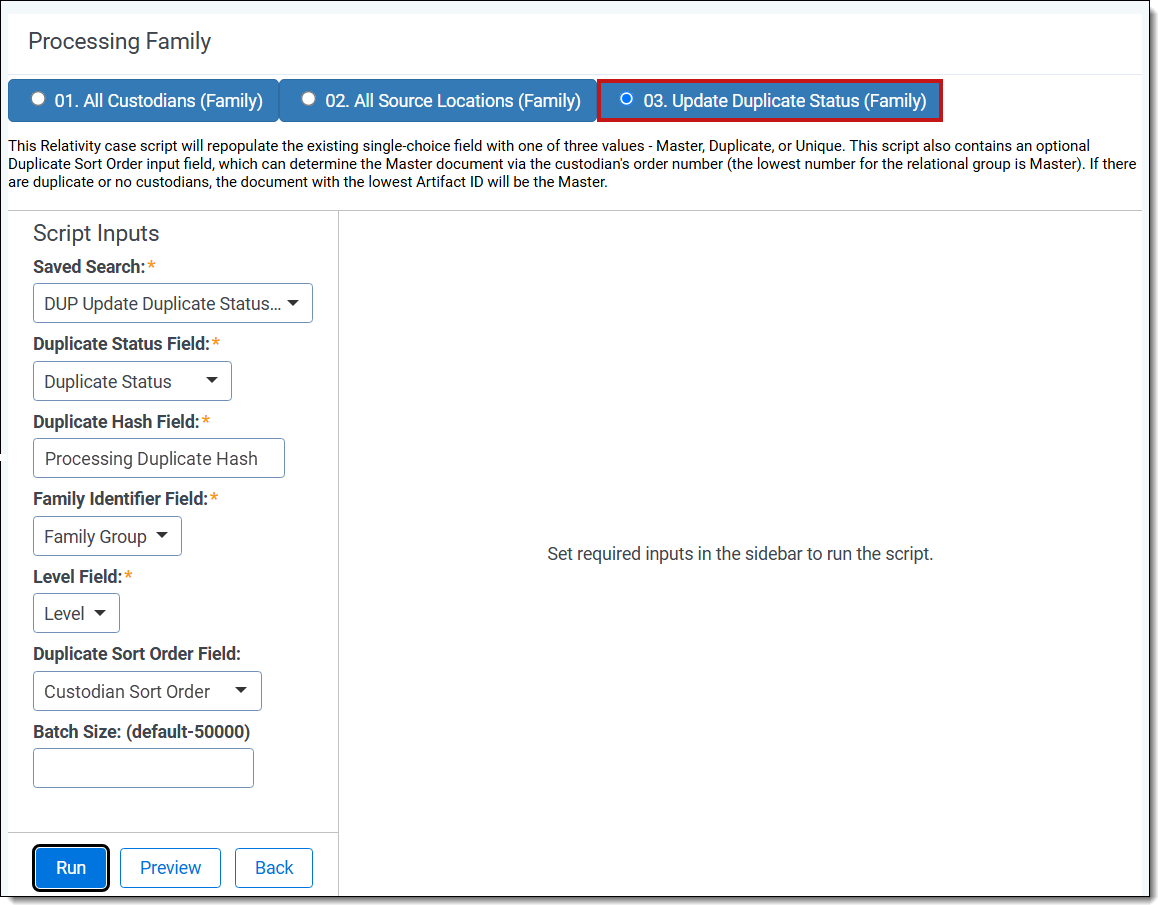 If using EDRM MIH, your script settings will be:
If using EDRM MIH, your script settings will be:
Update duplicate status item-level script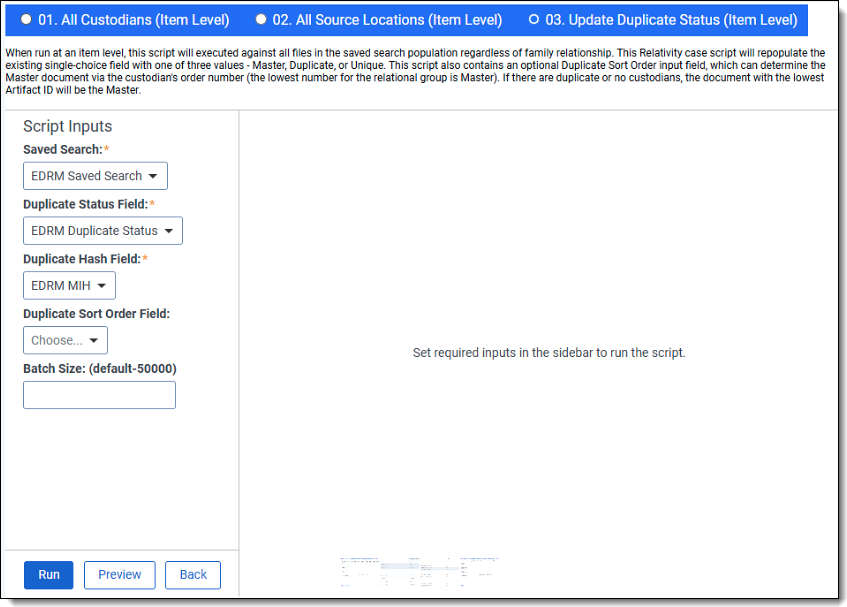
- Complete the following fields:
- Saved Search—select the saved search that has the group of documents to run the script against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another. Map this field to the EDRM Saved Search if using the EDRM MIH to identify potential duplicates.
- Duplicate Status Field—select the field where Relativity outputs the duplicate status.Map this field to the EDRM Duplicate Status field if using the EDRM MIH to identify potential duplicates.
- Duplicate Hash Field—select the relational field which defines groups of duplicate documents. For example, MD5, SHA1, or Processing Duplication Hash.Map this field to EDRM MIH if you are using the EDRM MIH to identify potential duplicates
- Family Identifier Field (Family-level only)—select the relational field which defines groups of family documents.
- Level Field (Family-level only)—select the whole number field which defines a numeric value indicating how deeply nested the document is within the family. This is commonly called the Level field if you discovered and published the data through Relativity Processing.
- Duplicate Sort Order Field—this is a field located on the Entity object. Leave this blank unless you have set up a field on the Entity object to store a priority sort order value for the custodian. When this field is blank, the system sorts on the document Artifact ID field from the Document object. The first document loaded in the workspace becomes the Primary document when duplicates are identified. See Viewing the Results for more information on how this field operates.
- Batch Size—(Optional—not all product versions have this field.) This field is optional and is the number of files in a saved search batch. Leave this field blank to use the default value of 50,000 or enter a value below 50,000 to increase the script execution speed.
- Saved Search—select the saved search that has the group of documents to run the script against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another.
- Click Run.
- You see a message indicting the results are permanent. Select Accept.
- Return to your saved search to view the results.
Viewing the results
When the script runs, it clears the Duplicate Status field for all documents in the workspace. After clearing, the field updates with the one of the following values for the documents in the saved search:
(If you used the EDRM MIH for your script, see Viewing EDRM results for sorting and filtering the EDRM Saved Search.
- Unique—the document in the saved search has a relational identifier that is unique compared to all the other documents.
- Master—documents in the saved search where more than one document has the same relational identifier.
- If you specify the Duplicate Sort Order field, the document with the lowest order of the associated custodian is the master. If multiple documents in the same group share the same custodian, the document with the lowest Artifact ID becomes the master.
- If you do not specify the Duplicate Sort Order field, the document having the lowest document Artifact ID in the relational group is the master.
- Duplicate—documents in the saved search where more than one document has the same relational identifier.
- If you specify the Duplicate Sort Order field, documents not having the lowest ordered custodian in the relational group are duplicates.
- If you do not specify the Duplicate Sort Order field, documents not having the lowest Artifact ID in the relational group are duplicates.
- Not Set—the relational identifier for the document in the saved search is not set.
Any documents not included in the selected saved search are excluded from the logic to calculate duplicate status and the Duplicate Status field is not populated.
You will see an Update Complete message when the script completes. Return to the saved search selected in the script to view the results.
Update duplicate status item-level script results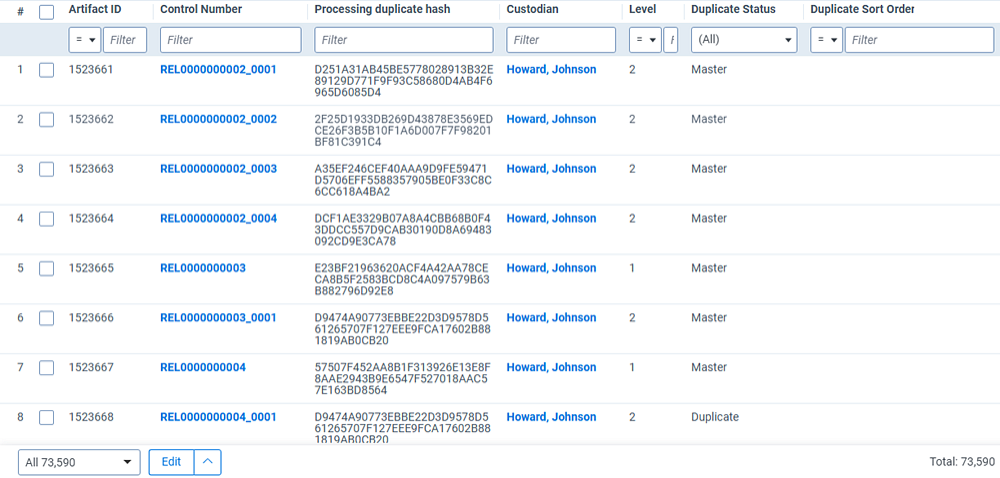
Update duplicate status family-level script results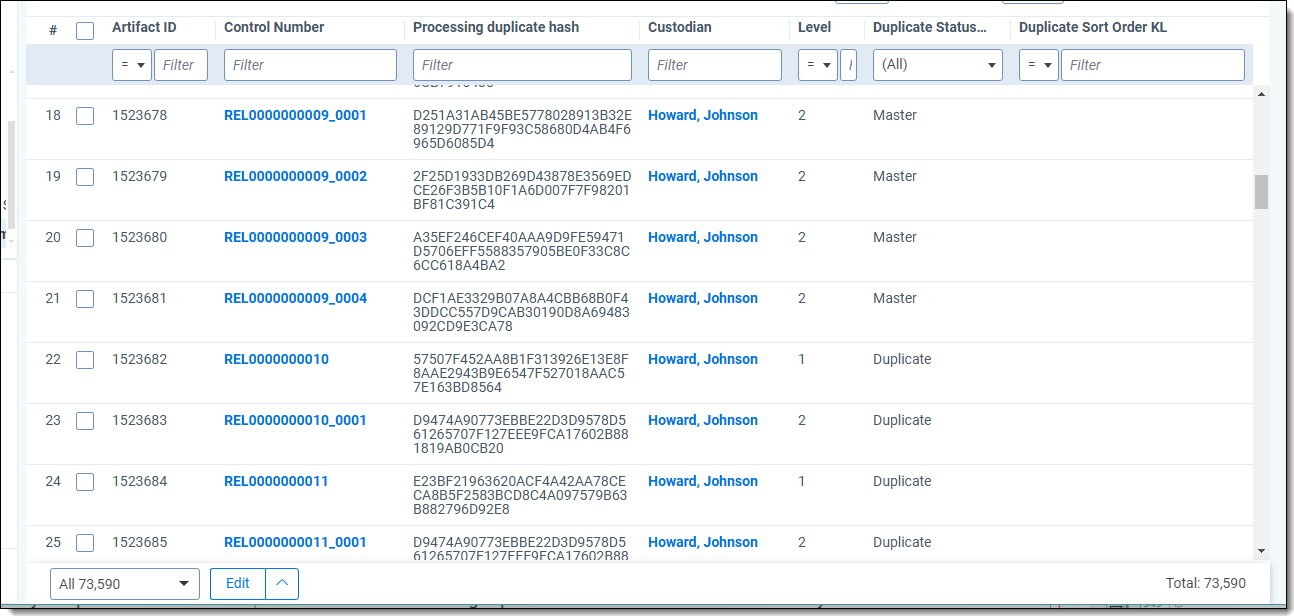
| Column | Description |
|---|---|
| Control Number | This is the file's ID. Child documents have an underscore and secondary number that tells you where the file is located within a family. For example, _0003 indicates the file is the third duplicate in the family group. |
| Processing Folder Path | The file location associated with the document. |
| Family Group | The relational field that defines groups of related documents. Use this field to identify and filter families of documents. |
| All Paths/Locations | The script uses this field to output a semicolon delimited list of source locations associated with the document. |
If you mapped the Duplicate Sort Order Field in the script to the Custodian Sort Order field, the script results will display a list based on the custodian sort order rank. The Custodian Sort Order field itself does not appear in the results.