






Feedback
Last date modified: 2026-Jul-02
Deduplication considerations
The following scenarios depict what happens when you publish a processing set using each of the deduplication methods available on the processing profile.
Note the following special considerations regarding deduplication:
- Deduplication is applied only on Level 1 non-container parent files. If a child file (Level 2+) has the same processing duplicate hash as a parent file or another child file, then they will not be deduplicated, and they will be published to Relativity, regardless of whether the hash field has the same value. This is done to preserve family integrity. You can find out the level value for a file by mapping the Level metadata from the Field Catalog.
- In rare cases, it’s possible for child documents to have different hashes when the same files are processed into different workspaces. For example, if the children are pre-Office 2007 files, then the hashes could differ based on the way the children are stored inside the parent file. In such cases, the child documents aren’t identical (unlike in a ZIP container) inside the parent document. Instead, they’re embedded as part of the document’s structure and have to be created as separate files, and the act of separating the files generates a new file entirely. While the content of the new file and the separated file are the same, the hashes don’t match exactly because the OLE-structured file contains variations in the structure. This is not an issue during deduplication, since deduplication is applied only to the level-1 parent files, across which hashes are consistent throughout the workspace.
- At the time of publish, if two data sources have the same order, or if you don't specify an order, deduplication order is determined by Artifact ID.
- The deduplication method selected for a given Processing Set applies only to the data being published in that set. When a set is published with deduplication enabled, Relativity deduplicates it against all previously processed data in the workspace — regardless of what deduplication settings those prior sets used. See the following examples:
- If the current set is configured with None, all documents will be published, regardless if past sets had deduplication enabled.
- If the current set is configured with Custodial or Global, the current set will deduplicate against all applicable data (matching the Custodian or all previously Published sets), even data that was originally published with None.
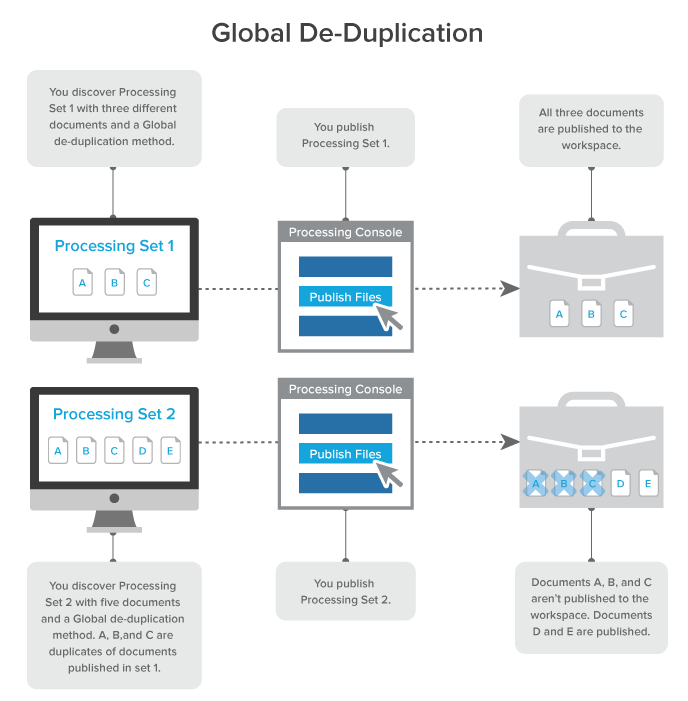
Global deduplication
When you select Global as the deduplication method on the profile, documents that are duplicates of documents that were already published to the workspace in a previous processing set aren't published again.
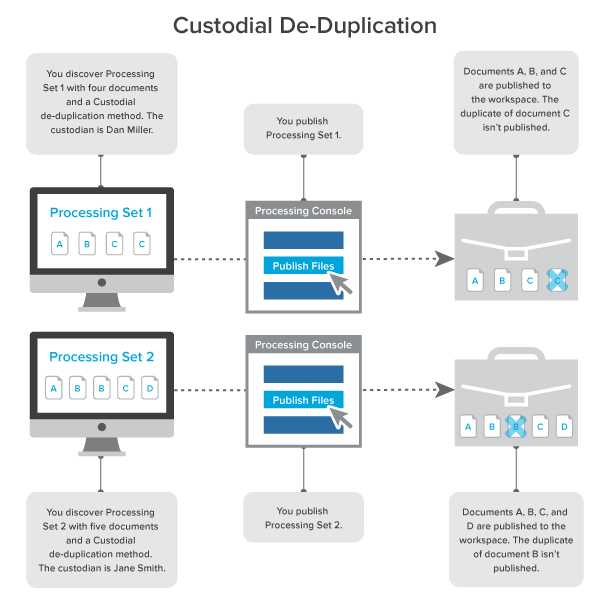
Custodial deduplication
When you select Custodial as the deduplication method on the profile, documents that are duplicates of documents owned by the custodian specified on the data source aren't published to the workspace.
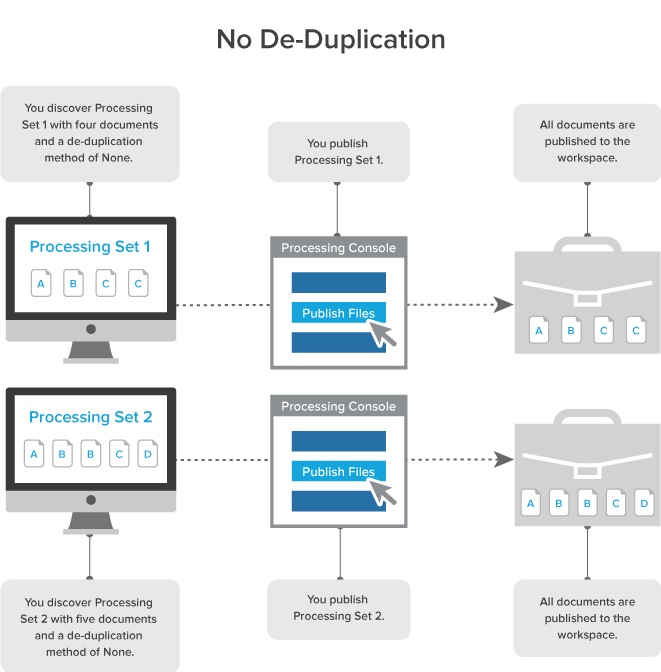
No deduplication
When you select None as the deduplication method on the profile, all documents and their duplicates are published to the workspace.
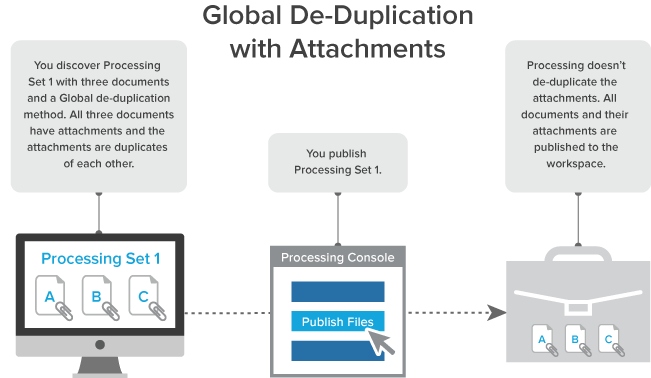
Global deduplication with attachments
When you select Global as the deduplication method on the profile and you publish a processing set that includes documents with attachments, and those attachments are duplicates of each other, all documents and their attachments are published to the workspace.
Global deduplication with document-level errors
When you select Global as the deduplication method on the profile, and you publish a processing set that contains a password-protected document inside a zip file, you receive an error. When you unlock that document and republish the processing set, the document is published to the workspace. If you follow the same steps with a subsequent processing set, the unlocked document is de-duplicated and not published to the workspace.
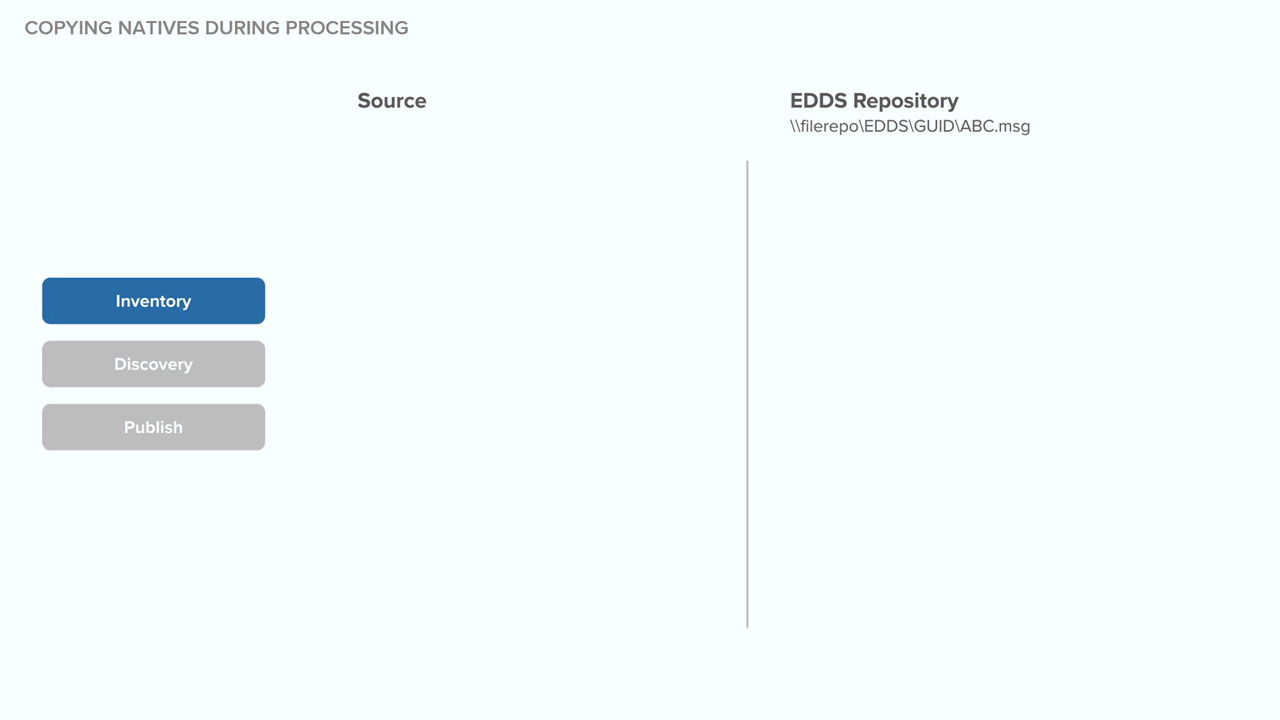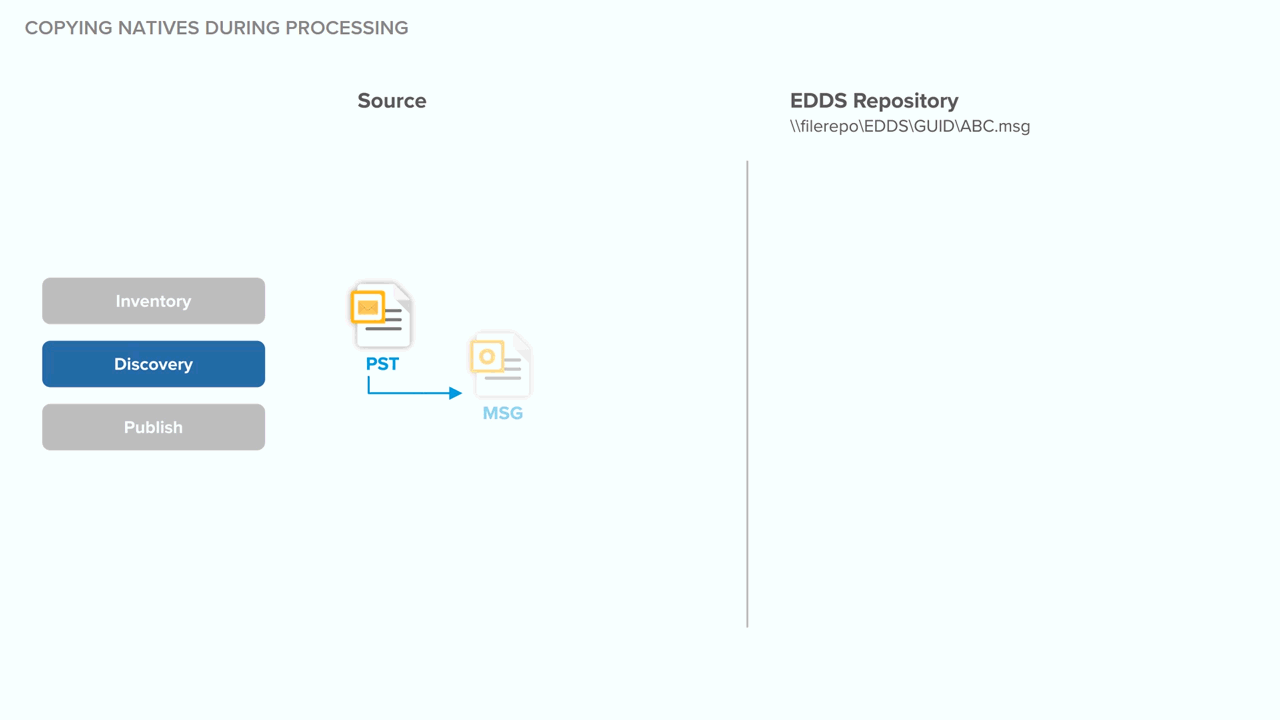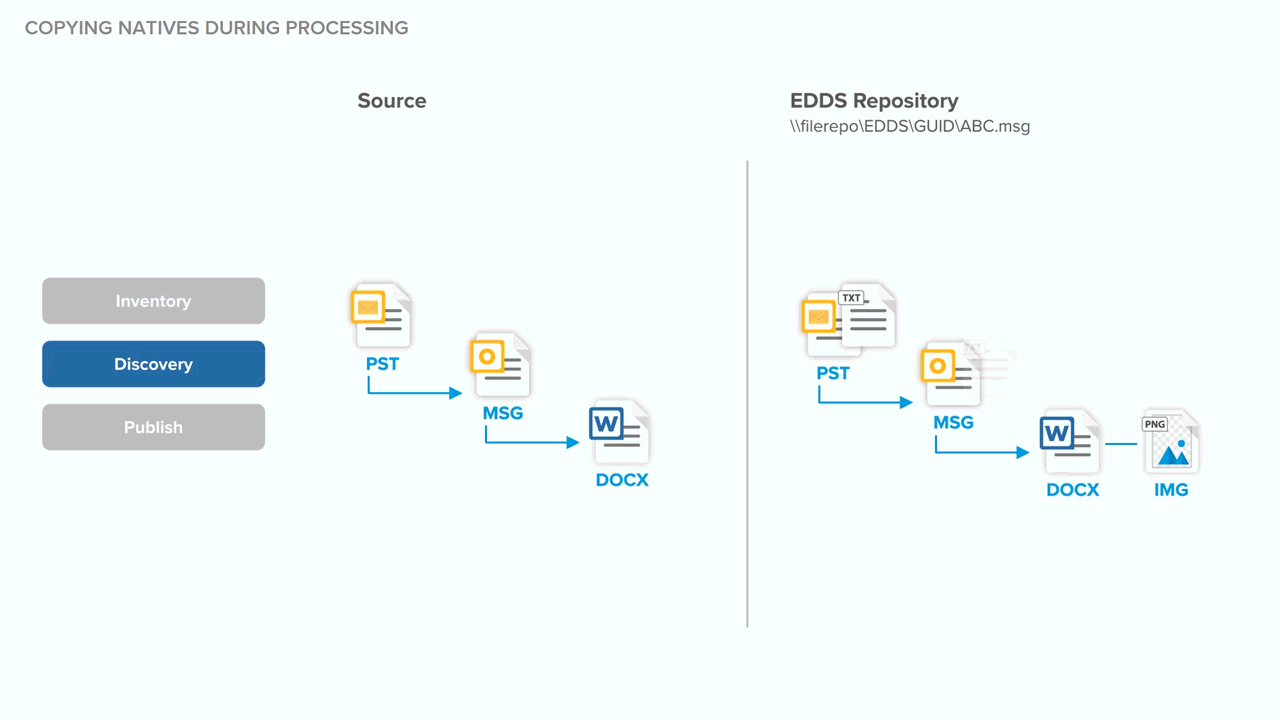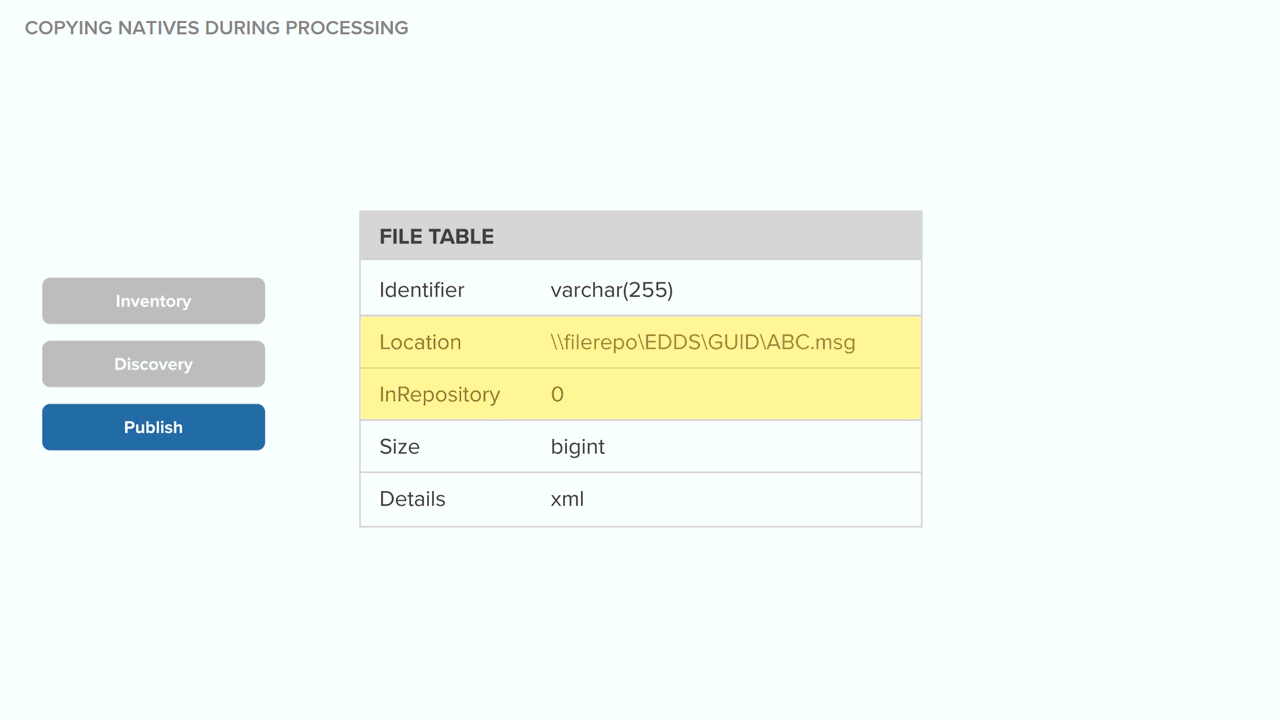
Technical notes for deduplication
Relativity is updating the underlying engine that handles EML file discovery. For most customers, the transition requires no action. The exception is if your workflows use EML email hash metadata outside of standard deduplication — for example, in custom scripts, field mappings, or exports to other systems. To learn more about this update and what it means for your workflows, see Email Message (EML) discovery update (Advanced Access) .
The system uses the algorithms described below to calculate hashes when performing deduplication on both loose files (standalone files not attached to emails) and emails for processing jobs that include either a global or custodial deduplication.
The system calculates hashes in a standard way, specifically by calculating all the bits and bytes that make the content of the file, creating a hash, and comparing that hash to other files in order to identify duplicates.
The following hashes are involved in deduplication:
- MD5/SHA1/SHA256 hashes—provide a checksum of the physical native file.
- Deduplication hashes—the four email component hashes (body, header, recipient, and attachment) processing generates to de-duplicate emails.
- Processing duplicate hash—hash values generated during processing duplication are as follows: for loose files, a SHA256 hash is generated from the physical file's SHA256 hash. For emails, a hash is generated from the email's metadata properties. See Calculating deduplication hashes for emails for more details.
Fields used for comparing files in deduplication
The following fields are used when comparing emails for deduplication:
- With global deduplication, the Processing Duplicate Hash field is compared to the Processing Duplicate Hash fields for processed files, much like loose files.
- With custodial deduplication, the Processing Duplicate Hash field is compared to the Processing Duplicate Hash fields of specific custodians.
- The MD5, SHA256, SHA1, and Email Conversation Index are not considered in deduplication of email files.
Office 2024 impact on EML Appointments in Processing
Starting in September 2025, Relativity handlers are using Office 2024 instead of Office 2016 for processing. This change may have an impact on the processing of EML Appointments. Hash values generated using Office 2016 may be different than hash values generated using Office 2024. As a result, some files previously identified as duplicates may no longer match if they are processed before and after the change. To ensure consistent hash values and discovery results, reprocess the files.
See the KB article, Office 2024 impact on EML Appointments in Processing for more detailed information.
The upgrade from Office 2016 to Office 2024 will be released via a phased roll-out, which means some customers will receive the update before others. We anticipate the roll-out phase being complete by the end of September. For more information on phased roll-outs, see the Phased Rollout FAQ on the Community.
Starting in September 2025, Relativity handlers are using Office 2024 instead of Office 2016 for processing. This change may have an impact on the processing of EML Appointments. Hash values generated using Office 2016 may be different than hash values generated using Office 2024. As a result, some files previously identified as duplicates may no longer match if they are processed before and after the change. To ensure consistent hash values and discovery results, reprocess the files.
See the KB article, Office 2024 impact on EML Appointments in Processing for more detailed information.
The upgrade from Office 2016 to Office 2024 will be released via a phased roll-out, which means some customers will receive the update before others. We anticipate the roll-out phase being complete by the end of September. For more information on phased roll-outs, see the Phased Rollout FAQ on the Community.
Calculating MD5/SHA1/SHA256 hashes
To calculate a file hash for native files, the system:
- Opens the file.
- Reads 8k blocks from the file.
- Passes each block into an MD5/SHA1/SHA256 collator, which uses the corresponding standard algorithm to accumulate the values until the final block of the file is read. Envelope metadata (such as filename, create date, last modified date) is excluded from the hash value.
- Derives the final checksum and delivers it.
Relativity cannot calculate the MD5 hash value if you have FIPS (Federal Information Processing Standards cryptography) enabled for the instance.
Calculating deduplication hashes for emails
Relativity calculates the MessageBody, Header, and Recipient hash values from the text metadata, which are case-sensitive. A hash generated from Bob.Smith@Email.com will be different from a hash generated from bob.smith@email.com. Attachment hash values are generated from the attached native and are not case sensitive.
MessageBodyHash
To calculate an email’s MessageBodyHash, the system:
- Captures the PR_BODY tag from the MSG (if it’s present) and converts it into a Unicode string.
- Gets the native body from the PR_RTF_COMPRESSED tag (if the PR_BODY tag isn’t present) and either converts the HTML or the RTF to a Unicode string.
- Removes all carriage returns, line feeds, spaces, and tabs from the body of the email to account for formatting variations. An example of this is when Outlook changes the formatting of an email and displays a message stating, “Extra Line breaks in this message were removed.”
The removal of all the components mentioned above is necessary because if the system didn't do so, one email containing a carriage return and a line feed and another email only containing a line feed would not be deduplicated against each other since the first would have two spaces and the second would have only one space.
- Constructs a SHA256 hash from the Unicode string derived in step 2 or 3 above.
HeaderHash
To calculate an email’s HeaderHash, the system:
- Constructs a Unicode string containing Subject<crlf>SenderName<crlf>SenderEMail<crlf>ClientSubmitTime.
- Derives the SHA256 hash from the header string. The ClientSubmitTime is formatted with the following: m/d/yyyy hh:mm:ss AM/PM. The following is an example of a constructed string:
- RE: Your last email
- Robert Simpson
- robert@relativity.com
- 10/4/2010 05:42:01 PM
RecipientHash
The system calculates an email’s RecipientHash through the following steps:
- Constructs a Unicode string by looping through each recipient in the email and inserting each recipient into the string. Note that BCC is included in the Recipients element of the hash.
- Derives the SHA256 hash from the recipient string RecipientName<crlf>RecipientEMail<crlf>. The following is an example of a constructed recipient string of two recipients:
- Russell Scarcella
- rscarcella@relativity.com
- Kristen Vercellino
- kvercellino@relativity.com
AttachmentHash
To calculate an email’s AttachmentHash, the system:
- Derives a SHA256 hash for each attachment.
- If the attachment is a not an email, the normal standard SHA256 file hash is computed for the attachment.
- If the attachment is an e-mail, we use the e-mail hashing algorithm described to Calculating deduplication hashes for emails to generate all four de-dupe hashes. Then, these hashes are combined, as described in Calculating the Relativity deduplication hash, to generate a single SHA256 attachment hash.
- Encodes the hash in a Unicode string as a string of hexadecimal numbers without <crlf> separators.
- Constructs a SHA256 hash from the bytes of the composed string in Unicode format. The following is an example of constructed string of two attachments:
- 80D03318867DB05E40E20CE10B7C8F511B1D0B9F336
⤷EF2C787CC3D51B9E26BC9974C9D2C0EEC0F515C770B8
⤷282C87C1E8F957FAF34654504520A7ADC2E0E23EA
- 80D03318867DB05E40E20CE10B7C8F511B1D0B9F336
ICS/VCF files are deduplicated not as emails but as loose files based on the SHA256 hash. Since the system now considers these loose files, Relativity is no longer capturing the email-specific metadata that it used to get as a result of ICS/VCF files going through the system's email handler.
Calculating the Relativity deduplication hash
To derive the Relativity deduplication hash, the system:
- Constructs a string that includes the SHA256 hashes of all four email components described above, as seen in the following example. For more information, see Calculating deduplication hashes for emails.
- 6283cfb34e4831c97e363a9247f1f01beaaed01d
⤷b3a65a47be310c27e3729a3ee05dce5acaec3696
⤷c681cd7eb646a221a8fc376478b655c81214dca7
⤷419aabee6283cfb34e4831c97e363a9247f1f01b
⤷eaaed01db3a65a47be310c27e3729a3ee3843222
⤷f1805623930029bad6f32a7604e2a7acc10db9126e3
⤷4d7be289cf86e
- 6283cfb34e4831c97e363a9247f1f01beaaed01d
- We convert the above string to a UTF-8 byte array.
- We then take that byte array and generate a SHA256 hash of it.
- If two emails have an identical body, attachment, recipient, and header hash, they are duplicates.
- For loose files, the Processing Duplicate Hash is a hash of the file's SHA256 hash.