






Feedback
Last date modified: 2026-Mar-10
Sampling for repeated content
Conceptual indexes benefit from targeted removal of boilerplate text, especially email confidentiality footers. Analytics offers repeated content identification, but on large document sets it can be slow and resource intensive.
This topic provides a method of running repeated content identification on random samples from a large document set. The sampling method is more efficient and uses fewer resources than running it on the full set, without sacrificing the quality of the results.
If your document set is smaller than 100,000 documents, there is no need to sample for repeated content.
See this related page:
Creating the sample
To create a sample for repeated content:
- On the Documents tab, search or filter for the documents you want to focus on. It might be everything in the workspace, the searchable documents from your index, or a set limited by file type, email inclusives, or some other subset.
- When you're looking at the document set you want to analyze, create a random sample by clicking the Sampling icon at the top of the document list.

- In the Sampling dialog, set the following:
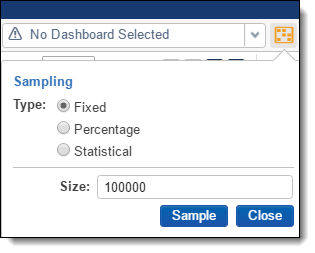
- Type: Fixed
- Size: 100,000
- Click Sample.
You should now see only 100,000 documents listed on the page.
Saving the sample as a list and a saved search
In order to use the sample in your Repeated Content Identification run, first save it as list, then as a saved search.
To create the list:
- At the bottom of the page, click All 100,000.
- From the Mass Operations drop-down, select Save as List.
- When prompted, name the list "100k Random Sample - List".
- Click Save.
To create the saved search:
- At the top of the page, click Clear Sample.
- Under Search Conditions, click Add Condition. Set the condition as the following:
- Lists: 100k Random Sample - List
- Click Run Search.
The 100,000 sampled documents will appear in the document grid. - At the bottom of the page, click Save Search.
- Name the list "100k Random Sample".
- Click Save.
A green banner appears confirming that the saved search was created.
To view the sample, click the Saved Search icon in the Browsers panel. The "100k Random Sample" search will appear in the browser.
Running repeated content identification as Structured Analytics set
To create a Structured Analytics Repeated Content Identification Set:
- From the Indexing and Analytics tab, select Structured Analytics Set. A list of existing Structured Analytics sets appears.
- To create a new set, click New Structured Analytics Set. The Structured Analytics Set layout appears.
- In the Structured Analytics Set Information layout, set the following:
- Name: Enter a name for your Structured Analytics set, such as "Repeated Content Identification on sample".
- Prefix: Leave as default.
- Operations to run: Repeated content identification
- Data source: select your saved search, 100k Random Sample.
- In the Repeated Content Identification layout, modify the Repeated content settings to suit your needs:
- For most settings, we recommend the defaults.
- For Minimum number of occurrences, set it in proportion to the number of documents. While 400 is generally appropriate for 100,000 document samples, you may need to raise or lower it for larger or smaller sets. For more information, see Setting the minimum number of occurrences.
- Click Save. The Structured Analytics Set Console appears.
- To run repeated content identification analysis, click Run, then click Run again in the pop-up options box. You can monitor the progress of the operation in a separate window by clicking the export icon in the upper right corner of the progress pane.
Review results
After the operation completes, review the filters it created and check that they are truly content you want to filter out, such as signatures or boilerplate text. You can do this by using filters along with the Ready to index field.
Setting the minimum number of occurrences
We recommend setting the Minimum number of occurrences as follows:
- If you are using a random sample, set this to 0.004 (0.40%) multiplied by the number of documents you are submitting. For example, with 100,000 documents, set the Minimum number of occurrences to 400.
- If you are not using a sample (for example, if you have a small collection with fewer than 100,000 documents), set the Minimum number of occurrences to 0.005 times the number of documents you are submitting.
To create more filters, you can reduce the Minimum number of occurrences. However, we do not recommend setting it lower than 100 on a 100,000 document sample, because the results can become more subject to sampling error. Consider running the operation across a judgmental sample instead. For example, you could run it across just parent emails, or just Word and PDF documents.