






Feedback
Review statistics
Note: The Active Learning application is now read-only. Create new projects in Review Center.
If you have Active Learning and Review Center installed in your workspace, you can view data for previous projects on the Active Learning History tab. Please note that uninstalling Active Learning removes the project data.
For more information, see:
The Review Statistics tab contains project statistics for each queue as well as a model update history.
Review Summary
The Review Summary section contains four tabs:
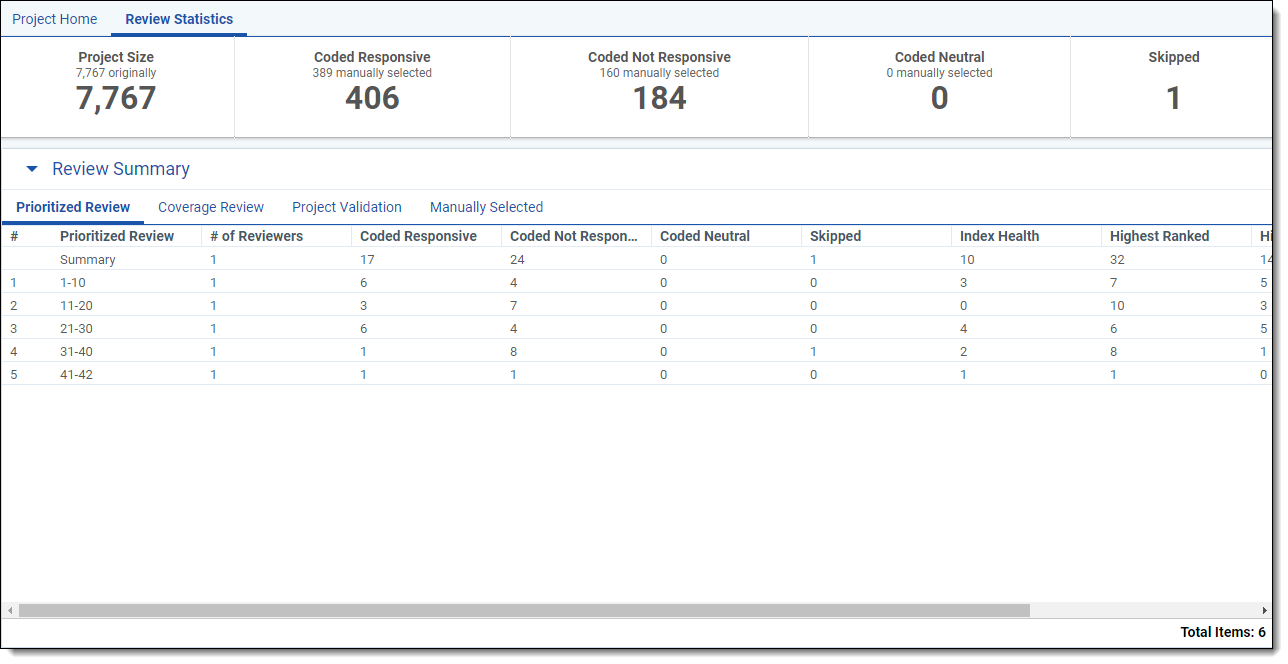
Prioritized Review
The Prioritized Review tab shows the effectiveness of the Prioritized Review queue’s ability to locate relevant documents by reporting the review field breakdown and relevance rate each 200 documents. For every 200 documents that are coded (excluding additional reviewed by family), a new row appears in the Prioritized Review table. The first row in the table provides a summary for the entire project.
The Prioritized Review table contains the following columns:
- Prioritized Review - the set of documents the statistics apply to (excludes additional reviewed by family). The sum of the count of Coded [Positive Choice], Coded [Negative Choice], and Skipped documents should equal 200.
- # of Reviewers - the number of unique reviewers who reviewed documents in the Prioritized Review queue during this interval.
- Coded [Positive Choice] - the number of documents coded with the positive designation on the review field (excludes additional reviewed by family).
- Coded [Negative Choice] - the number of documents coded with the negative designation on the review field (excludes additional reviewed by family).
- Coded Neutral - the number of documents coded with a neutral designation on the review field (excludes additional reviewed by family).
- Skipped - the number of documents that were saved or had Save and Next selected with no coding decision supplied on the review field (excludes additional reviewed by family).
- Index Health - the number of index health documents reviewed in the Prioritized Review queue. These documents are excluded from the relevance rate calculation.
- Highest Ranked - the number of highly ranked documents reviewed in the Prioritized Review queue.
- Highest Ranked Coded [Positive Choice] - the number of highly ranked documents that were coded with the positive designation in the Prioritized Review queue.
- Relevance Rate - the percentage of documents that were chosen for being highly ranked that were then confirmed as relevant by reviewers' coding decisions. You can calculate the relevance rate manually using the following formula: Highest Ranked Coded [Positive Choice] / Highest Ranked.
- Additional Reviewed by Family - the number of family documents reviewed in the Prioritized Review queue.
- Additional Review by Family Coded [Positive Choice] - the number of family documents coded with the positive designation in the Prioritized Review queue.
Coverage Review
The Coverage Review tab shows the progress of the Coverage Review by reporting the review field breakdown every 200 documents. For every 200 documents that are coded, a new row appears in the Coverage Review table. The first row in the table provides a summary for the entire project.
The Coverage Review table contains the following columns:
- Coverage Review - the set of documents the statistics apply to.
- # of Reviewers - the number of unique reviewers who reviewed documents in the Coverage Review queue during this interval..
- Coded [Positive Choice] - the number of documents coded with the positive designation on the review field.
- Coded [Negative Choice] - the number of documents coded with the negative designation on the review field.
- Coded Neutral - the number of documents coded with a neutral designation on the review field.
- Skipped - the number of documents that were saved or had Save and Next selected with no coding decision supplied on the review field.

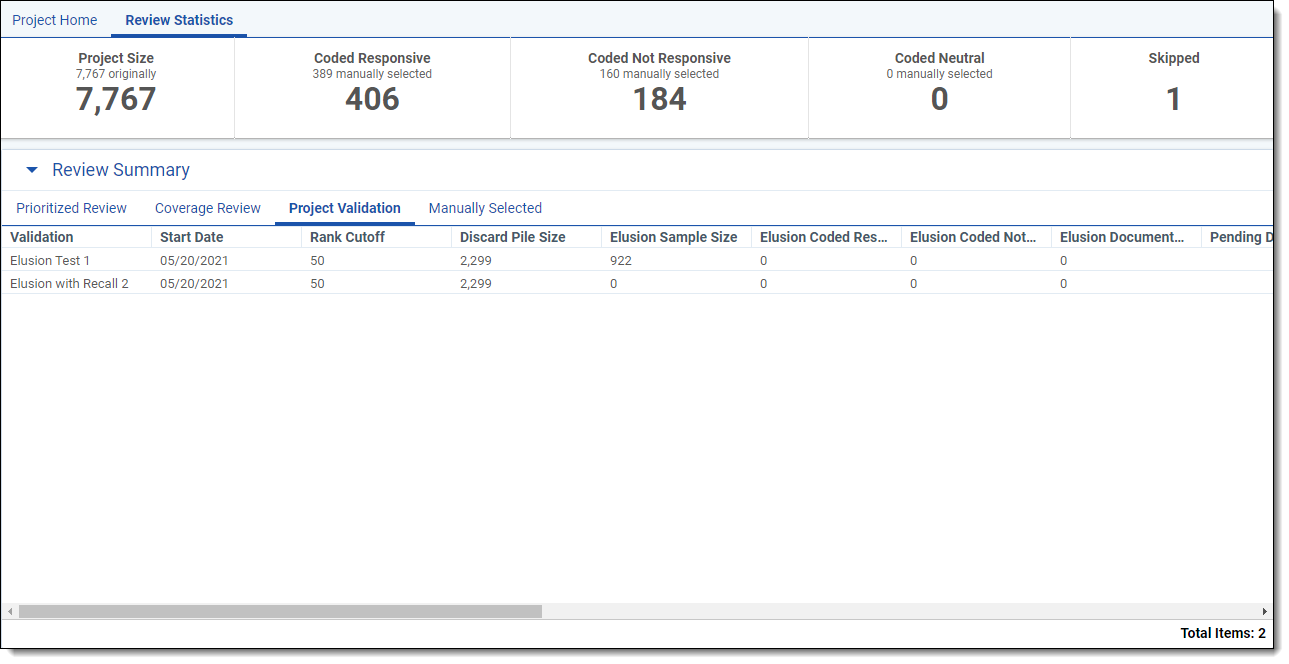
Project Validation
Use the Project Validation tab to monitor validation testing. A new row is created when Project Validation starts and is populated with the available information about the validation. As documents are coded, the counts and calculations update upon page refresh. If Project Validation is stopped before completion, statistics are calculated based on what has been coded so far.
The Project Validation tab contains the following columns:
- Validation - each review is called Elusion with Recall or Elusion Test plus a numeral. For example, the first Elusion with Recall is "Elusion with Recall 1," and the second is "Elusion with Recall 2."
- Start Date - the UTC date and time when Project Validation was started.
- Rank Cutoff - the numeric cutoff for positive prediction, fixed before project validation begins.
- Discard Pile Size - the number of documents below the rank cutoff that are not coded when Project Validation was started.
- Elusion Sample Size - the number of documents sampled for elusion rate. This number is computed when Project Validation is started.
- Elusion Coded [Positive Choice] - the number of sampled documents from below the cutoff which were coded positive during project validation.
- Elusion Coded [Negative Choice] - the number of sampled documents from below the cutoff which were coded negative during project validation.
- Elusion Documents Skipped/Coded Neutral - the number of sampled documents from below the cutoff that were either saved with no coding decision on the review field, or saved with a neutral coding decision. Note: For best results, we strongly recommend coding every document in the Project Validation queue as positive or negative. Avoid skipping documents or coding them as neutral. For more information, see How Project Validation handles skipped and neutral documents.
- Pending Document Count - the number of documents whose coding has changed since the last model build (prior to Project Validation starting). This includes documents coded in Project Validation, and documents coded through other means. For instance, if a reviewer manually codes documents after Project Validation is underway, these will be counted as Pending.
- Elusion Rate (Range) - the error rate of the discard pile. This is calculated as the percentage of sampled, previously uncoded documents from below the cutoff which are coded positive during Project Validation. The range applies this sampled rate to the entire discard pile, using the confidence level provided by the user and the margin of error calculated from sample size.
- Confidence Level for Elusion - user input or calculated when setting up Project Validation.
- Elusion Margin of Error - margin of error calculated based on the elusion sample size, the discard pile size, and the elusion rate on the validation sample.
- Estimated Eluded Documents (Range) - the projected number of eluded documents. This estimates the number of relevant documents you would miss if you produced all documents marked relevant, as well as those with ranks at or above the cutoff.
- Recall Rate (Range at CL80%) - the percentage of truly positive documents which were found by the Active Learning process. A document has been "found" if it was previously coded positive, or if it is uncoded with a rank at or above the cutoff. Recall is calculated on the sample, then estimated for the total population with a confidence level (CL) of 80%.
- Precision Rate (Range) - the percentage of found documents which are truly positive. A document has been “found” if it was previously coded positive, or if it is uncoded with a rank at or above the cutoff. Documents which were predicted positive but coded negative during validation will count against precision. Precision is calculated on the sample, then estimated for the total population with a confidence level (CL) of 80%.
- Precision Margin of Error (CL80%) - the margin of error for precision as estimated from the sample size, the equivalent portion of the whole project, and the observed precision rate on the validation sample.
- Richness Rate (Range) - the percentage of documents which are relevant (positive choice). This is calculated by dividing the number of positive-coded documents in the sample by the total number of documents in the sample. The range predicts the richness for the whole project, subject to a 95% confidence level.
- Richness Margin of Error (CL95%) - the margin of error for richness as estimated from the sample size, the whole project size, and the observed richness rate on the sample.
- Estimated Total Relevant Documents - the estimated number of relevant documents in the whole project. This is calculated by projecting the richness rate across the whole project.
- Total Documents in Project - the number of documents in the project at the time of project validation.
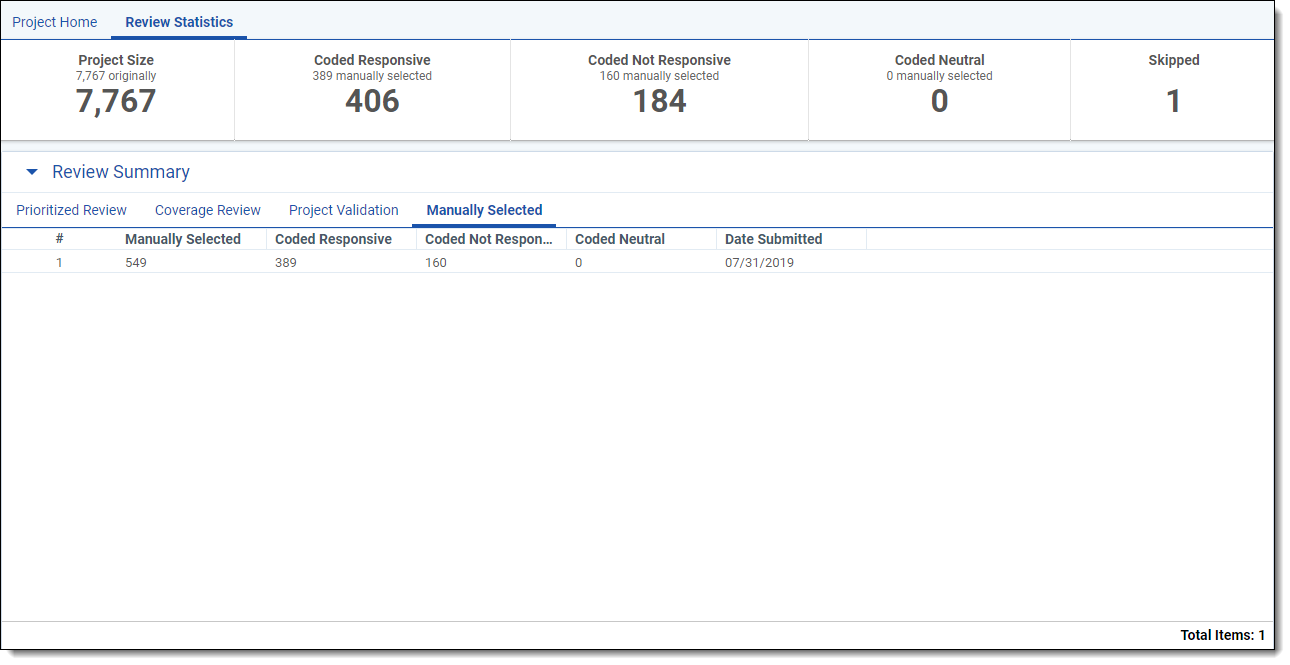
Manually-Selected
The Manually-Selected tab contains the following columns:
- Manually-selected Documents - the number of documents coded outside of the Active Learning queue.
- Coded [Positive Choice] - the number of these documents coded with the positive designation on the review field.
- Coded [Negative Choice] - the number of these documents coded with the negative designation on the review field.
- Coded Neutral - the number of these documents coded with a neutral designation on the review field.
- Date submitted (UTC) - the date in UTC that the statistics were submitted.
Model Updates
The Model Updates section contains a history of Active Learning model builds. A new row is added each time the model builds, and the statistics are based off of the <Positive Choice> Cutoff set in the Project Settings. If you update the <Positive Choice> Cutoff at any point, the statistics will update accordingly.
- Build Date - a timestamp indicating when the model build completed, displayed in local time.
- Above or At Cutoff - the number of documents above or at the <Positive Choice> Cutoff.
- Below Cutoff - the number of documents below the <Positive Choice> Cutoff.
The subsequent columns indicate the number of documents in each relevance rank range.
