






Feedback
Last date modified: 2026-Feb-13
Alphabet list
Some of the characters in the alphabet file are not printable. Screenshots were used instead of the actual text. You cannot copy or paste the Spaces or Ignore characters since they are not printable. Instead, use the dtSearchDefaultAlphabetFile instance setting to update the dtSearch default alphabet file.
Each sequence must start with a leading, or empty, space. Not having the leading space may produce errors.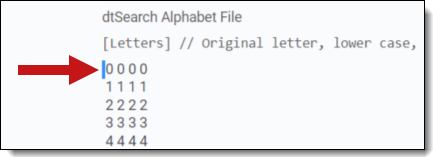
dtSearch Alphabet File
The following is the default dtSearch Alphabet file you'll find in Relativity. It contains letters, numbers, hyphens, spaces, ignore, and end (CJK ranges) sections.
This section only accepts ASCII characters (code points between 33 and 127) as input. We currently do not support ignoring extended Unicode values.
[Letters] // Original letter, lower case, upper case, unaccented
0 0 0 0
1 1 1 1
2 2 2 2
3 3 3 3
4 4 4 4
5 5 5 5
6 6 6 6
7 7 7 7
8 8 8 8
9 9 9 9
A a A A
B b B B
C c C C
D d D D
E e E E
F f F F
G g G G
H h H H
I i I I
J j J J
K k K K
L l L L
M m M M
N n N N
O o O O
P p P P
Q q Q Q
R r R R
S s S S
T t T T
U u U U
V v V V
W w W W
X x X X
Y y Y Y
Z z Z Z
_ _ _ _
a a A a
b b B b
c c C c
d d D d
e e E e
f f F f
g g G g
h h H h
i i I i
j j J j
k k K k
l l L l
m m M m
n n N n
o o O o
p p P p
q q Q q
r r R r
s s S s
t t T t
u u U u
v v V v
w w W w
x x X x
y y Y y
z z Z z
[Hyphens]
-
[Spaces]
\09\0a\0c\0d !@"#$&'()*+,./:;<=>?[\5c]^`{|}~
[Ignore]
[End]
CJKRanges = 0e00-0e4e 3040-30ff 4e00-9fff
Previous guidance hid some characters that should not have been hidden. Those non-printable characters are critical to index function and should never be removed. The "\08" text represents the "backspace" text, and should also never be removed or split up (that is, trying to index the backslash).
Alphabet file validation
When you save a dtSearch index, Relativity runs a validation check on the alphabet list. You will see a warning message if Relativity detects invalid spacing or syntax. You cannot save the index if there are errors with the alphabet list.
The validation check includes:
- Header sections
- Header section appears first in Alphabet
- Exact header section without any added whitespace
- Required newline before section
- Letters
- Exact title, allowing any whitespace and comments preceding double slash //
- Each letter on own line with preceding space
- Each letter variant separate by single space
- Allow any extra whitespace after letter
- Hyphens, Spaces, and Ignore
- Exact title, allowing any whitespace
- Single line of characters with preceding space
- Optional newlines before next section
- Footer sections
- Exact title
- Skip validating any text following title
- General
- Purple, Pink, Red, Green sections are each optional and can be in any order
Alphabet file sections
The following descriptions are for characters in the ASCII 33-127 range.
Letters
dtSearch defines letters as characters to index. This includes all alphabetical characters (a-z and A-Z) and all digits (0-9).
dtSearch is case insensitive. You cannot make dtSearch case-sensitive in Relativity by modifying the Letters section of the Alphabet file.
Hyphens
dtSearch defines hyphens as characters that receive special processing in dtSearch. By default, dtSearch only classifies the - character as a hyphen.
[Hyphens]
-
Hyphens are separated into their own category because dtSearch has special processing for them. Hyphens in this section include the normal hyphen ( - ) the em dash (—) and the en dash (–). Relativity does not distinguish these as different, regardless of what goes into the hyphen section. By default, dtSearch will index the hyphen as a space.
In the following example, we have three documents:
Doc 1 = "I sent it by first-class mail"
Doc 2 = "I sent it by first class mail"
Doc 3 = "I sent it by firstclass mail"
A search for first class on an dtSearch index with default noise words and Alphabet file, will return documents 1 and 2.
If we remove the Hyphen from the hyphen section, then a search for first class will return documents 1 and 2.
To force dtSearch to recognize the hyphen characters in dtSearch, add it to the alphabet section of the Alphabet File. To do this, see Searching for symbols and emojis, and replace all % signs with the hyphen ( - ) character.
You will need to remove the hyphen from the Hyphen section, and it does not appear in the spaces section. You will not need to use a regular expression to search for the hyphen.
After running a full build, dtSearch will recognize the hyphen as a searchable character. This will return cases where all three commonly used hyphens are used: the hyphen, em dash and the en dash. There is no way to distinguish between the hyphen, em dash, and the en dash.
After making this change, a search for first class will only return Doc 2. A search for first-class will only return Doc 1, and a search for firstclass will only return Doc 3.
Here is the dtSearch Hyphen page: https://support.dtsearch.com/dts0154.htm
Spaces
dtSearch defines a space character as a character that causes a word break. These characters are not indexed and are not searchable. By default, dtSearch treats the following characters as spaces:
[Spaces]
\09\0a\0c\0d !@"#$&'()*+,./:;<=>?[\5c]^`{|}~
Values listed as \## are Unicode code points. Their definitions are:
- \09—horizontal tab
- \0a—line feed
- \0c—form feed
- \0d—carriage return
- \5c—backslash (\)
For more information, log into the Relativity Community to review the dtSearch Unicode values for Special Characters article.
You can do so by using a Regular Expressions (RegEx) workflow to get around the fact that * is a reserved dtSearch operator. Wrapping up (or you can think of this as insulating) the asterisk * in a RegEx allows * to be treated as the literal character *, and not the wildcard operator *.
You will need to do the following:
- Make the asterisk * a searchable character in your dtSearch index by adjust the alphabet file. Building a second dtSearch index is recommended, as opposed to making * searchable in the main dtsearch index.
- Refer to the recipe “Regular expression searching – symbols“, which contains detailed instructions on how to make characters searchable . In the recipe, substitute the % sign for the asterisk *.
- Use Regular Expressions (RegEx) to bring back the proper results.
Now, the recipe directs you to use the RegEx metacharacter \W to search for the % sign. Instead, you will just need to escape the * asterisk with a backslash \. Once you’ve made * searchable, the exact RegEx search terms you will need to plug into your dtSearch box to search for **REHAB is:
"##\*\*rehab"
"##" signals to dtSearch that what’s contained in between needs to be treated as a RegEx. The backslash \ escapes the * character so that it is treated as * and not a RegEx metacharacter.
In this example below, I'm searching for **REHAB and have made * a searchable character in my index. Note first the test data. The goal is to bring back only those records on lines 1 and 2.
When searching for **REHAB using the RegEx "##\*\*rehab", I get the correct results:
**Rehab by itself will not work even though you made * a searchable character because without the RegEx, * is still treated as the wildcard operator. Surrounding "**Rehab" in quotes also will not work.
Parenthesis are used for grouping search request terms in Boolean expressions. Quoting them makes them part of the search term instead. However it is possible to make the parentheses searchable by taking the following steps:
- Add the parentheses to your alphabet file, using the steps in documentation for adding symbols. For more information, see Searching for symbols and emojis
- Run a full build on your dtSearch index.
- Add quotes around your dtSearch search term when searching. Quotes tell dtSearch we want the term in the quotes treated as characters, not syntax.
For example, if you are searching for the term (apple) with parenthesis in the term, then you would just add quotes around the term like so: "(apple)".
Permanently adding ( and ) to the alphabet file is not recommended because of the role of parentheses in search requests as logical operators, which will be confusing for users. Worse, parentheses in document text will cause search terms to be effectively lost. For example, consider this excerpt:
The defendant (John Smith) ...
If parentheses are indexed, then neither John nor Smith will be indexed, because the parentheses become part of the word. The search terms in the index would be "(John" and "Smith)". An index created this way is effectively useless for anything except specifically searching for parenthesis.
Because of this, we recommend that you only make parentheses searchable in a separate dtSearch index for use with the searches which contain the parentheses.
Ignore
dtSearch defines an ignored character as a character that is not indexed and does not create a word break when processing text. These characters are not searchable. By default, dtSearch ignores the following characters:
[Ignore]
- \08—backspace character
- %—percent sign
Values listed as \## are Unicode code points. Currently, the only code point that is ignored by default is the backspace character (\08).
End
dtSearch has defined ranges for CJK characters and these will make each Thai, Chinese, and Japanese character a separate word.
[End]
CJKRanges = 0e00-0e4e 3040-30ff 4e00-9fff
Non-ASCII characters
Non-ASCII characters have a Unicode value greater than 0x7F. Many characters that are not ASCII are searchable by default. For those which are not, for example € and £, you can index them by adding their hexadecimal code to the AdditionalLetters section of the alphabet file. For more information, see Searching for symbols.
Restricted characters
Some characters cannot be queried with standard syntax because of a limitation in dtSearch or because of how Relativity uses the dtSearch API. The following characters require special treatment in your query:
" ( ) * ? % ~ # & =
For searching with parenthesis, see Search for parentheses
You can use a regular expression to search for these characters. For example, Searching for an asterisk.
Searching for a symbol or character
To search for a symbol or character in Relativity, see Searching for symbols.
Searching for emojis
To search for emojis in Relativity, see Searching for emojis.
Reserved characters in the alphabet file
If you add a reserved character to the alphabet and was able to bring it back in your results, it's because dtSearch treats reserved characters as operators regardless of what you set in the Alphabet file. Consider how those operators act when you determine whether a solution works.
For example, you added the % to your Alphabet file and removed it from the Ignore list, and you were able to bring back apple%.
The % is the fuzzy operator, meaning you can have any one character, or no character, in this spot and bring results back. This is very similar to how *, wildcard, or ?, wildcard for any single character, work. Remember that because % is no longer being ignored, it will be indexed and will show up as part of the term. The word apple% was returned indirectly, because you matched the pattern apple + any indexed character. You cannot search for just % and bring back correct results.