






Feedback
Last date modified: 2026-Jul-17
Setting up CJK document workspaces in Relativity
When working with documents that contain Asian character sets, specific settings help expedite your setup time in Relativity. This information can help you build a clean workspace with more accurate fields to support your Asian language document sets.
This document highlights items to be aware of as you work with workspaces that contain CJK character sets.
New workspaces created in RelativityOne have extracted text automatically stored in Data Grid. Workspaces restored into RelativityOne using the ARM application will automatically have the extracted text migrated to Data Grid. To search extracted text in workspaces, you must use dtSearch or Analytics searching; you cannot use keyword search.
Requirements
When setting up a workspace for CJK documents, there are the following requirements:
- Applicable to all versions of Relativity.
- Workspace access with the following permissions:
- Field: Edit, Delete
- Searches: Edit, Delete
- Import/Export application installed.
Import data with CJK characters
To import data with CJK characters:
- On your extracted text fields, confirm the Unicode field is set to Yes.
The Unicode field is set to Yes by default.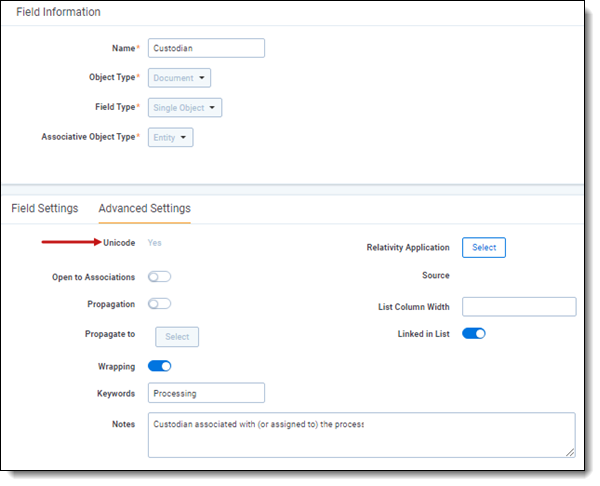
- Set up fields such as Custodian, email fields, File Name, and Extracted Text as Unicode-compliant to capture CJK characters.
- Open the data files that are Unicode/CJK character-compliant.
- Use Import/Export to Import the data in a Unicode-compliant format. For more information on importing extracted text files, see Image and extracted text files.
Be sure to include any extracted text.
Searching considerations
Consider the following with SQL, dtSearch, and CJK documents. Essentially each character is its own word, or token, so proximity searching works.
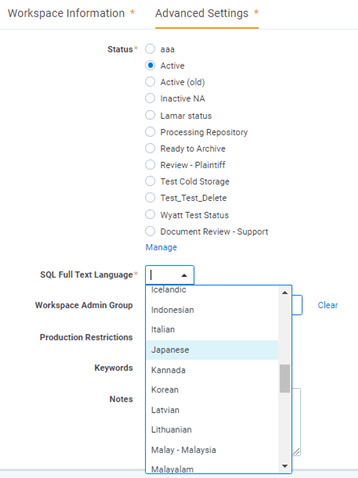
Once you configure your SQL full-text language to the correct language, you can perform keyword searching and filtering in that language. Japanese in this example.
dtSearch
dtSearch can search for words in the Chinese, Japanese, and Korean languages just as it can search for words in other languages. This is because Relativity stores these languages, or converts them to, Unicode.
However, while dtSearch can search for literal word matches, or wildcard or fuzzy matches, there are some limitations to dtSearch's support for Chinese, Japanese, and Korean text.
Index
To enable support for Chinese, Japanese, and Korean (CJK) languages in Relativity, ensure that all indexed fields are Unicode-enabled. When using the default dtSearch index configuration, no changes are required to the alphabet list. By default, the CJKRanges setting (0e00-0e4e 3040-30ff 4e00-9fff) ensures that each CJK character is treated as an individual word. This allows Relativity to perform accurate word breaking and searching across CJK text.
Word/Character search
You can store or convert Chinese, Japanese, and Korean text to Unicode so that you can use dtSearch to search for words in these languages just as you search for words in other languages. However, while dtSearch can search for literal word matches, or wildcard or fuzzy matches, there are some limitations on the support in dtSearch for Chinese, Japanese, and Korean text.
Those limitations include:
- Some documents store text in a way that does not separate the words with spaces. Instead, all of the text in a document runs together, and a language-specific dictionary is needed to find word breaks. dtSearch does not have the ability to identify word breaks in these documents because it does not include any language-specific dictionaries.
To make this type of text searchable, enable an option in dtSearch to automatically insert word breaks around Chinese, Japanese, and Korean characters. Once you enable this option, Relativity treats each character as a single word for indexing and searching purposes. - This feature is turned on by default in dtSearch. Because each term is searchable, we recommend searching for multiple characters to assist in retrieving more accurate results. When looking for multiple characters, use the proximity connectors to assist in finding desired results.
- The same text can be presented in different ways depending on the context. dtSearch searches for a word as it is provided in the search request and does not generate additional grammatical or script variations for words in Chinese, Japanese, and Korean.
- The dtSearch engine has an API that you can use to integrate with dictionary-based language analyzers from companies such as Basis Technologies. But while the dtSearch standalone desktop does allow for integration, the instance within the Relativity environment does not support integration.
For non-Western languages, such as Chinese, Japanese, and Korean, there are additional considerations and workarounds that may provide assistance in locating search hits.
Keyword search
Within a Relativity workspace, a system admin can select the language to use in the SQL Full Text Language. SQL Full Text Language determines the correct stemming and word-break characters used in the full text index.
For multiple language workspaces, Microsoft recommends setting the most complex prevalent language as the SQL Full Text language.
Language considerations
Each language has its own considerations. This section covers a few common languages and the things you should consider.
Mandarin considerations
When setting up workspaces for Mandarin, keep in the following considerations:
- Relativity treats Mandarin characters as words. Therefore the Mandarin characters do not need an extra space because each character can be compared against a list. If there is a match, then it's highlighted.
- Numbers are not treated like Mandarin characters. For example, when you use the number 54, you need everything until there is a space. Add a space to the subject so the term is 54 所[space], then the rest of the line, it will highlight.
- The term 54 所 does not match the subject. The subject has the additional characters, hence no match.
- The Mandarin characters do not need the space because each character, such as 所, is treated uniquely, therefore, it highlights.
- Keyword Search—once you configure your SQL full-text language to the correct language, you can perform keyword searching and filtering in that language.
- dtSearch—once you set up all indexed fields to be Unicode compliant, no changes are required to the alphabet list. The default CJKRanges setting (0e00-0e4e 3040-30ff 4e00-9fff) ensures that each CJK character is treated as an individual word. This allows Relativity to perform accurate word breaking and searching across CJK text.
| emp | emp | emp |
|---|---|---|
| 54 所 (other characters) | 54所 | No match |
| 所 | Match | |
| 54所 (other characters) | Match | |
| 54 所 space (other characters) | 54 所 | Match |
| 所 | Match | |
| 54 所 (other charaters) | No Match | |
| (other characters) | Match | |
Chinese considerations
When setting up workspaces for Chinese, keep in the following considerations:
- Relativity can treat Chinese characters as words. Therefore, the Chinese characters do not need an extra space because Relativity can compare each character against a list. If there is a match, then it's highlighted.
- Relativity does not treat numbers like Chinese characters. For example, when you use the number 54, followed by a Chinese character or characters, you need a match on everything until there is a space. Add a space to the search term so the term is 54 所[space], and then the rest of the line, then it will highlight.
- The term 54 所 does not match the subject. The subject has the additional characters, hence no match.
- The Chinese characters do not need the space because each character, such as 所, is treated uniquely. Therefore, it highlights.
- Keyword Search—once you configure your SQL full-text language to the correct language, you can perform keyword searching and filtering in that language.
- dtSearch—remember that highlighting and search hits are separate implementations. Thus, there are cases where the search returns a document as a hit, but the highlighting does not show how the hit occurred.
Analytics considerations
Take the following into consideration before using Analytics:
- Use the structured data analytics language identification operation, or PLI language technique, to identify the languages of the documents in your workspace.
- Training your Analytics index in one language as opposed to multiple languages generally produces a better quality index. However, if many of your documents contain multiple languages, this can change.
- Be sure to set up your noise words in the same language as your index.
- Relativity does not provide stop words for languages other than English-configuration is left up to the administrator.
Refer to the Analytics - Support for CJK and other non-English Languages article for more detailed considerations.
Tokenization considerations
Languages like Chinese, Japanese, and Korean are fundamentally more difficult to process than European languages because their words are not consistently separated by spaces. Chinese and Japanese do not use spaces between words. Korean uses some spaces, but not between every word, and inconsistently depending on the writer.
Tokenization are methods used to produce indexable units in these languages. Each resulting in different degrees of search precision. Tokenization, which is based on morphological analysis, breaks up text into real words. Morphological analysis in linguistics examines morphemes, which are the smallest units of meaning within a word , such as “un” in the word “unremarkable.”
When the system performs tokenization on the following example, there are at most three items to index. Possibly only two because the possessive marker might be treated as a noise word. A noise word in this case is the same as in English, namely a word that occurs so frequently within a language that it does not help in finding search results and is thus ignored by some search engines.
The following example breaks down how the system would tokenize the phrase sightseeing spots in Tokyo, which in Japanese appears as: 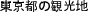 .
.
| Characters | English translation |
|---|---|
| 東京の観光スポット | sightseeing spots in Tokyo |
| 東京 | Tokyo |
| の | (possessive marker) |
| 観光 | sightseeing |
Technical workflow for tokenized character handling
When working with documents that contain certain Asian character sets, specific settings help expedite your setup time in Relativity. This information can help you build a clean workspace with more accurate fields to support your Asian language document sets.
- In your workspace, set the Unicode field to Yes for your text and choice fields.
This ensures that you can store non-Western European characters in these fields. - Set up fields such as Custodian, email fields, File Name, and Extracted Text as Unicode-compliant to capture characters accurately.
- Your processing vendor should have provided you with data files that are Unicode/CJK character-compliant. If this is the case, choose the encoding of the load file and any extracted text files.
Failure to set the source encoding correctly will lead to corrupt storage in your Relativity fields.