






Feedback
Last date modified: 2026-Jun-30
aiR for Review
aiR for Review is powered by generative AI, large language models (LLM), and natural language processing to examine extracted document text based on your prompt instructions. It helps pinpoint significant documents, explains their significance, and provides citations from those documents.
A few benefits of the application include:
- Highly efficient, low-cost document analysis
- Quick discovery of important documents to the case based on prompt criteria
- Early detection of documents containing confidential business information based on prompt criteria
- Trustworthy predictions, explanations, and citations
- Consistent, cohesive analysis across all documents
Below are some common use cases for it:
- Beginning the review process—prioritize the most important documents to give to reviewers.
- First-pass review—determine what you need to produce and discover essential insights.
- Gaining early case insights—learn more about your matter right from the start.
- Internal investigations—find documents and insights that help you understand the story hidden in your data.
- Analyzing productions from other parties—help reduce the effort to find important material and get it into the hands of decision makers.
- Quality control for traditional review—compare aiR for Review's coding predictions to decisions made by reviewers to accelerate QC and improve results.
See these related resources for more information:
- aiR for Review Validation Concepts and Definitions (White paper)
- AI Advantage: Aiming for Prompt Perfection? Level up with Relativity aiR for Review
- A Focus on Security and Privacy in Relativity’s Approach to Generative AI
- Workflows for Applying aiR for Review
- aiR for Review example project
- aiR for Review Prompt Writing Best Practices
- Evaluating aiR for Review Prompt Criteria Performance
- Selecting a Prompt Criteria Iteration Sample for aiR for Review
- Six characteristics of Generative AI and their impact on aiR products
- Relativity aiR Ask the Expert: Generative AI Fundamentals in Relativity
aiR for Review process overview
The aiR for Review process uses Relativity instructions, SME-developed prompt criteria, and extracted document text as input. It processes this data to produce document citations with associated rationale, considerations on possible prediction errors, and its recommendation (such as relevant, not relevant, or borderline). aiR then verifies citations per document to help assess accuracy and reduce the likelihood of hallucinated content (up to five citations per document are allowed for Relevance and Relevance and Key Documents analyses, and one citation per issue for Issues analysis).

aiR for Review phases
The workflow is similar to training a human reviewer: explain the case and its criteria, hand over the documents, and check the results. If the application appears to misunderstand aspects of the prompt criteria, refine the instructions and iterate to improve results.
The workflow has three phases:
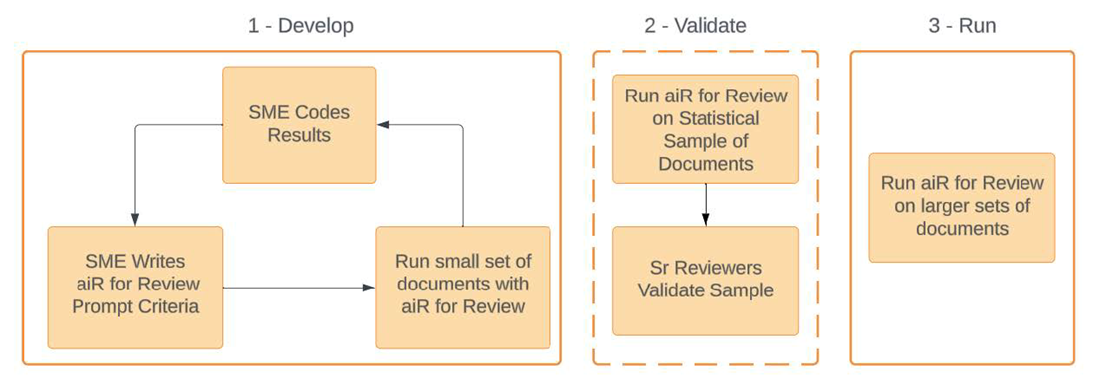
- Develop—write and iterate on the prompt criteria (review instructions) and test it on a small document set until aiR’s recommendations are reasonably aligned with expected results based on validation criteria.
- Validate—run the prompt criteria on a slightly larger set of documents and compare to results from reviewers to evaluate alignment and identify differences.
- Apply—use the validated prompt criteria on larger sets of documents, or the full set.
Within RelativityOne, the main steps are:
- Select the documents to review. See Choosing the data source for more information.
- Create an aiR for Review project. See Creating an aiR for Review project for more information.
- Write and submit the prompt criteria (review instructions). See Developing prompt criteria for more information.
- Review the results. See Analyzing aiR for Review results for more information.
When setting up the first analysis, we recommend running it on a sample set of documents that was already coded by human reviewers. If the resulting predictions are different from the human coding, revise the prompt criteria and try again. This could include rewriting unclear instructions, defining an acronym or a code word, or adding more detail to an issue definition.
For additional workflow help and examples, see Workflows for Applying aiR for Review on the Community site.
Analysis review types
aiR for Review offers the following analysis types, each suited to a specific review or investigation phase.
| Analysis Type | Description |
|---|---|
| Relevance | Use for relevance reviews to help identify documents that are relevant to a case matter or situation that you describe, such as documents responsive to a production request. |
| Key Documents | Use to help identify documents that may be considered hot or important to a case or investigation, such as those that might be critical or embarrassing to one party or another. |
| Issues | Use for issues reviews to find documents that include content that falls under specific categories or legal issues that are relevant to the case. For example, you might use this to check whether documents involve coercion, retaliation, or a combination of both. |
| Confidential Business Information (CBI) | Use for a confidentiality review to find and classify documents that include confidential/sensitive information on the selected CBI types to ensure proper handling and protection. For example, use to locate documents containing business strategy, trade secrets, or non-public financial data. This functionality is being released through a phased rollout and is only available to clients in the US and EU Data Zone at this time. For more information on phased rollouts, see the Phased Rollout FAQ article available on the Community. |
| Custom | Use to create your own custom prompt-driven insights per project to analyze text and image documents based on your current needs. Each custom insight acts as an independent analysis for questions, extractions, classifications, or evaluative instructions applied to every eligible document. For example, extracting themes from documents and object detection in images. |
How it works
aiR for Review uses an Azure OpenAI LLM to analyze documents based on prompt criteria. Each document is reviewed separately, with results returned before the next document is sent. The LLM bases its predictions solely on prompt criteria and internal training, unlike Review Center, which learns from the document set.
For more information on using generative AI for document review, we recommend:
- Relativity Webinar - AI Advantage: How to Accelerate Review with Generative AI
- MIT's Generative AI for Law resources
- The State Bar of California's drafted recommendations for the use of generative AI
Security and privacy
Azure OpenAI does not retain any data from the documents being analyzed. Data you submit for processing by Azure OpenAI is not retained beyond your organization’s instance, nor is it used to train any other generative AI models from Relativity, Microsoft, or any other third party. For more information, see the white paper A Focus on Security and Privacy in Relativity’s Approach to Generative AI.
Generating document summaries
aiR for Review automatically generates descriptive topics and summaries for every document in a project, regardless of analysis type chosen. Relativity sends each document individually to Azure OpenAI. The LLM reviews each one independently and does not learn from previous documents. The topic and summary generation ignores the prompt criteria and relies solely on a document’s content, keeping these consistent across projects.
- Document summaries and descriptive topics cannot be generated without running one of the analysis types.
- Document summaries do not affect the number of aiR Units used. For more information on aiR Units and billing, see aiR Units in RelativityOne standard workspaces and aiR Units, Thresholds, and Included Products on the Community (valid login credentials required).
- Because of data processing locations, document summaries are opt-in only for RelativityOne instances in France, Germany, Ireland, and the Netherlands. For more details or to opt in, contact your account representative.
aiR units and billing
For billing purposes, an aiR Unit in aiR for Review is the extracted text from a single document. The initial pre-run estimate may be higher than the actual aiR Units billed because of canceled jobs or document errors. To find the actual aiR Units that are billed, use Cost Explorer. For more information, see Cost Explorer.
A document will be billed each time it runs through aiR for Review analysis, regardless of whether that document ran before. Document summaries do not affect the number of aiR Units used. For more information on aiR Units and billing, see aiR Units in RelativityOne standard workspaces and aiR Units, Thresholds, and Included Products on the Community (valid login credentials required).
Customer may not consolidate documents or otherwise take steps to circumvent the aiR for Review Document Unit limits, including for the purpose of reducing the Customer's costs. If Customer takes such action, Customer may be subject to additional charges and other corrective measures as deemed appropriate by Relativity.
Language support
The underlying LLM used by aiR for Review has been evaluated for use with 83 languages. While aiR for Review itself has been primarily tested on English-language documents, unofficial testing with non-English datasets shows encouraging results.
If you use the application with non-English data sets, we recommend the following:
- Rigorously follow best practices for writing. For more information, see Best practices.
- Iterate on the prompt criteria. For more information, see Revising the prompt criteria.
- Analyze the extracted text as-is. You do not need to translate it into English.
- When possible, write the prompt criteria in the same language as the documents being analyzed. This should also be the subject matter expert's native language. If that is not possible, write the prompt criteria in English.
When reviewing analysis results, all citations remain in the language of their respective source documents. By default, rationales and considerations are provided in English. To request rationales and considerations in another language, include this sentence within the Additional Context field of your prompt criteria: Write rationales and considerations in <Language>. While this approach has been effective in many instances, the LLM may not consistently generate output in the specified language.
Analyzing emojis
aiR for Review has not been specifically tested for analyzing emojis. However, the underlying LLM does understand Unicode emojis. It also understands other formats that could normally be understood by a human reviewer. For example, an emoji that is extracted to text as :smile: would be understood as smiling.