






Feedback
Last date modified: 2026-May-28
Conflicts
During entity normalization, aiR for Data Breach Response may identify records that share some — but not all — Personal Information (PI) identifiers. These are called conflicts. A conflict occurs when two or more records have overlapping PI (such as a shared email address) but also contain contradictory PI (such as different SSNs), making it unclear whether they represent the same individual or different individuals.
After the normalization process completes, you can review conflicts on the Conflicts subtab under Entity Analysis. Resolving conflicts helps you determine whether entities should be merged or kept separate before you finalize your entity report.
Review Conflicts
To review conflicts after normalization:
- Navigate to Entity Analysis and open the Conflicts subtab.
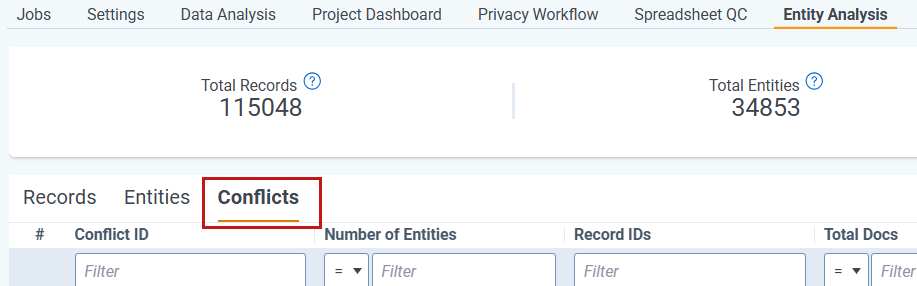
- Review the Conflict Reason column to understand why records were grouped together.
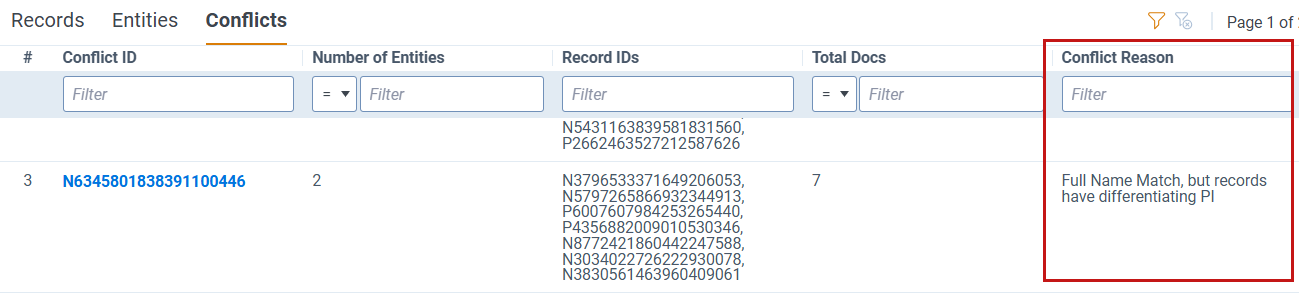
- Review Total Conflicts and any Primary Conflicts, Secondary Conflicts, and Tertiary Conflicts.
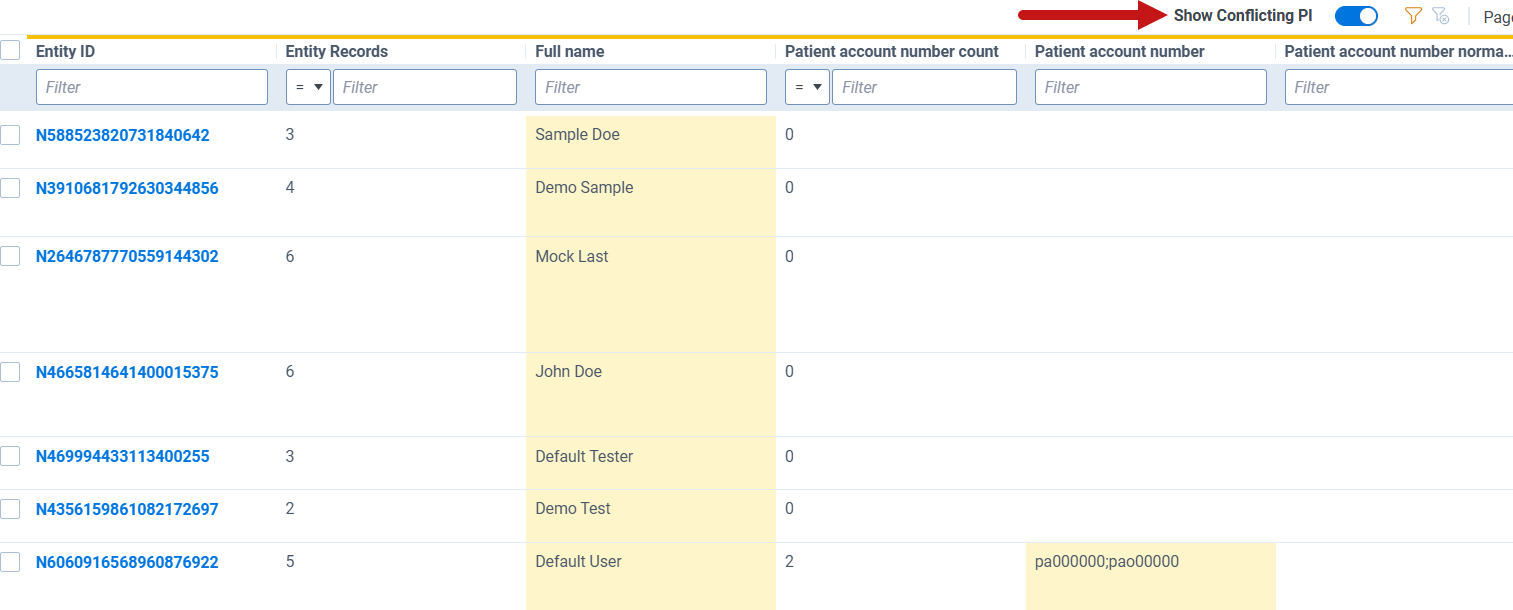
- Click a Conflict ID to open the conflict details and investigate the individual records.
- Determine whether the entities in the cluster represent the same individual (and should be merged) or different individuals (and should remain separate).
- To merge entities, select the Entity IDs and click Merge on the Mass Operations bar.
- To mark a cluster as reviewed, update its Status in the Conflict Details view.
- Repeat this process for all conflict clusters before finalizing your entity report.
Entity and conflict counts update after each Data Analysis run.
Recommended workflow
Use the following workflow to prioritize your conflict review:
- Sort the table to review all clusters with Primary Conflicts > 0.
- Sort the table to review all clusters with Secondary Conflicts > 0.
- Sort the table to review all clusters with Tertiary Conflicts > 0. This may not be necessary based on project requirements.
- If the conflict list contains too many clusters that do not require action, update the Identifier Types in Project Settings to reduce the number of generated conflicts.
-
After resolving all conflicts, sort clusters by size in descending order and review large clusters for entities with similar names that may need to be merged.
- This is best for large clusters.
- Unless time permits, it may not be beneficial to review all clusters with a size > 1.
For Cluster review:
- To merge two entities together, select the entities and select the Merge button.
- Entities left separate in the Cluster will remain as separate line items in the Entity List and Entity Export.
- Once cluster review is complete, rerun normalization so that the entity report is updated.
Conflicts fields
The following are definitions of fields found within the Conflicts subtab.
| Field | Description |
|---|---|
|
Conflict ID |
Unique identifier for that conflict |
|
Number of Entities |
Number of entities in the conflict cluster |
|
Total Docs |
Total documents containing records affected by this cluster |
|
Conflict Reason |
Reason there is a conflict for this group of entities |
|
Total Conflicts |
Number of conflicts |
|
Primary Conflicts |
Specific list of conflicting PI Types that are also primary PI types based on your Data Analysis categorization. |
|
Secondary Conflicts |
Specific list of conflicting PI Types that are also secondary PI types based on your Data Analysis categorization. |
|
Tertiary Conflicts |
Specific list of conflicting PI Types that are also tertiary PI types based on your Data Analysis categorization. |
|
Status |
Review status of the conflict cluster:
|
|
Resolved By |
The name of the user who reviewed or is reviewing the conflict cluster |
|
Resolved On |
Time stamp of when the user marked the conflict cluster as reviewed |
Example conflict logic
During normalization, aiR for Data Breach Response compares records based on three categories of identifiers:
- Primary identifiers — High-confidence PI types, such as Social Security Number (SSN), that are most likely to uniquely identify an individual.
- Secondary identifiers — Moderate-confidence PI types, such as date of birth (DOB), that support identification but may not be unique on their own.
- Tertiary identifiers — Lower-confidence PI types, such as email address, that may be shared or reused across individuals.
You configure which PI types are primary, secondary, or tertiary in your Data Analysis categorization settings.
The following table shows example scenarios where conflicts are generated and what each match result means.
| Scenario | Name | Primary | Secondary | Tertiary | Example Alias 1 | Example Alias 2 |
|---|---|---|---|---|---|---|
| Names match or are similar, but primary identifiers do not match. Tertiary identifiers match. | Match | No match | - | Match |
Name: John Smith SSN: 223-55-6788 Email: jsmith@gmail.com |
Name: John Smith SSN: 123-45-6789 Email: jsmith@gmail.com |
| Names match or are similar. There is not enough information on primary identifiers to compare. Secondary identifiers do not match. Tertiary identifiers match. | Match | Not enough info | No match | Match |
Name: John Smith Email: jsmith@gmail.com DOB: 01/20/1990 |
Name: John Smith Email: jsmith@gmail.com DOB: 12/10/1970 |
| Names match or are similar. There is not enough information on primary identifiers to compare. Secondary identifiers do not match. Tertiary identifiers match. | No match | Match | - | - |
Name: John Smith SSN: 123-45-6789 DOB: 01/20/1990 |
Name: David Johnson SSN: 123-45-6789 |
| Names are not similar and primary identifiers do not match. Tertiary matches. | No match | No match | - | Match |
Name: John Smith SSN: 123-45-6789 Email: jsmith@gmail.com |
Name: Adam Brown SSN: 623-65-6678 Email: jsmith@gmail.com |
| Names are not similar and there is not enough information on primary identifiers to compare. Tertiary matches. | No match | Not enough info | - | Match | Name: John Smith Email: jsmith@gmail.com | Name: David Johnson Email: jsmith@gmail.com |