






Ingest documents
Note: Billing for Data Breach Response will begin when documents are ingested using the steps below.
After the PI Detect and Data Breach Response application is installed into your workspace, documents will need to be ingested before reviewing results. To ingest documents you will need to create a saved search containing all documents to send to Data Breach Response and create an ingestion job.
Caution: PI Detect and Data Breach Response projects cannot be run in the same workspace. Attempting to run separate Data Breach - Ingestion and Personal Information - Ingestion jobs will cause the application to error.
Prerequisites
Before ingesting documents, the following prerequisites must be met:
- Ingestion requires a saved search as input. For each ingestion job, a different saved search must be used. We recommend creating a list in Relativity containing the documents and generating a saved search from the list. For more information, see Saved search and Lists.
- We recommend adding the PI_Exception field when creating your saved search. This field will help identify any documents that encountered exceptions during the ingestion job.
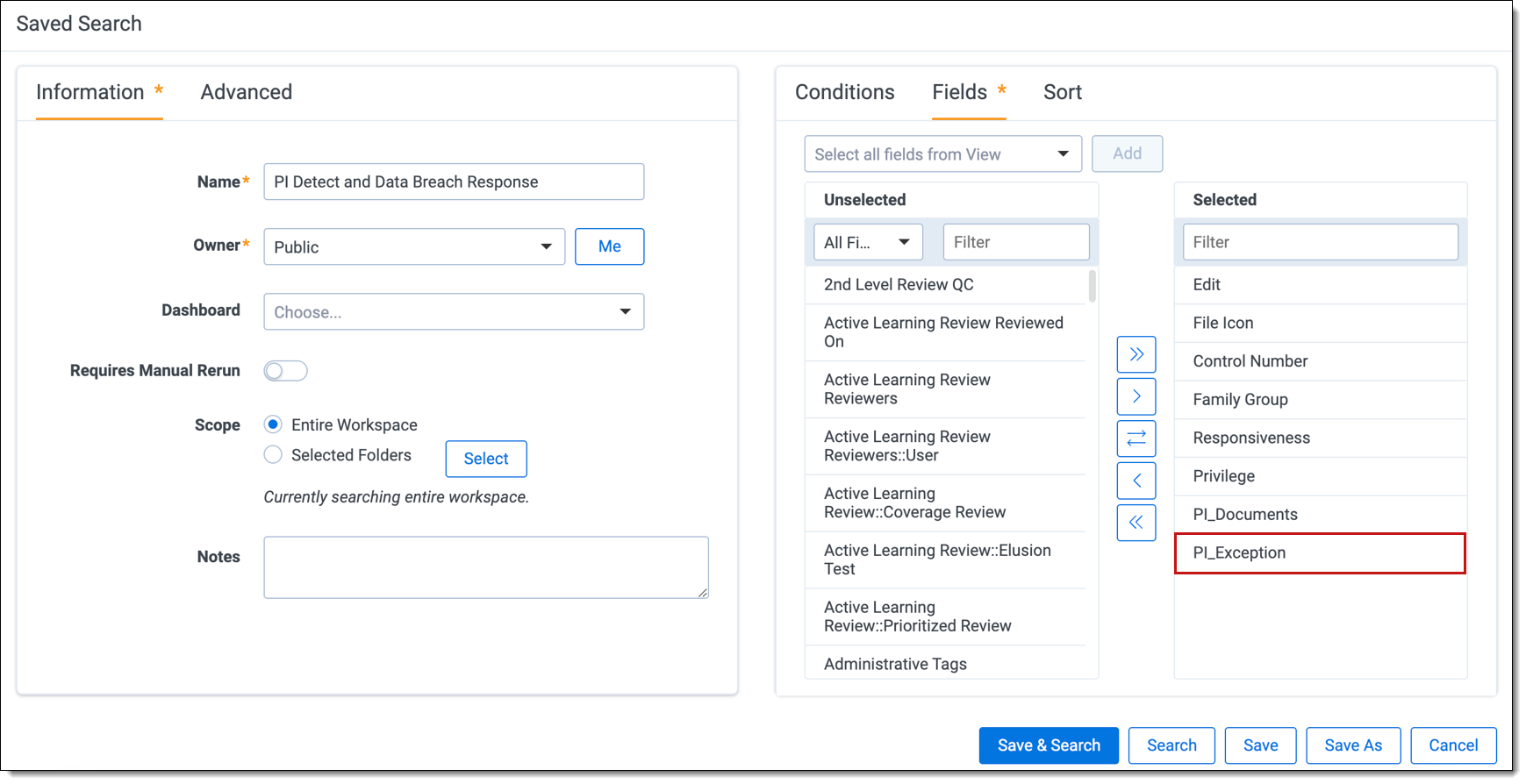
- We recommend adding the PI_Exception field when creating your saved search. This field will help identify any documents that encountered exceptions during the ingestion job.
Considerations
The Privacy Workflow tab will not load until you run an ingestion job for the first time.
Creating a new ingestion job
To create a new ingestion job:
- Navigate to the Data Breach Response and Personal Information Application.
- Click Jobs.

-
Click New PI Jobs.

- Enter a Name for the Job.
-
Select Data Breach – Ingestion or Data Breach- Report as the job type. Note: There are two types of Jobs for Data Breach and Personal Information: Ingestion and Report.
- Ingestion jobs will transfer files from RelativityOne to the dedicated Data Breach Response instance.
- Report jobs will pull the document report back to RelativityOne once the Data Breach Response pipeline has successfully completed.
- Select the Saved Search containing all documents to send to Data Breach Response.
- Select Data Settings.
- Click Save.

- Once the job has been saved, the ingestion job will be automatically started.
It can take several minutes to hours to complete depending on how large the data set is.



See Cost explorer for more details about the information that will be displayed. See Understanding cost in Relativity for information about how costs are calculated.
Once the job has transitioned its status to Completed, the document ingestion pipeline in Data Breach Response has been started successfully. At this time, you can navigate to the Privacy Workflow tab to see the in-progress document ingestion process, located in the Document Ingestion tab of the left-hand navigation panel. This screen details each step of the ingestion process and if any failures occurred.
Job-level states
Following is a list of job-level states and descriptions:
| Job status | Description |
|---|---|
| Queued | The agent has not picked up this job to process yet. |
| Running | An agent is currently processing this job. During this state, the job will be split into batches. |
| Waiting | The job is waiting for all the batches to get into a terminal state. A terminal state is defined by a batch being in Completed or Errored state. |
| Completed | All of the batches for this job are complete. |
Ingestion job states
Following is a list of ingestion job states and descriptions:
| Batch Status | Description |
|---|---|
| Preparing Application |
Prepares the application backend for a project. This batch only runs during the first ingestion job and will not run for subsequent jobs. Note: This batch may take up to 30 minutes to complete and may be retried if it fails.
|
|
Data-upload (pending) |
Initial State. |
| Data-upload (ready-to-send) | Notifies Data Breach Response that the records are Ready to Send. |
| Data-upload (ready-to-receive) | Preparing records in batch to transfer and send to Data Breach Response. |
| Completed | Ingestion job is complete, and documents have successfully transferred to Data Breach Response. |
Verify document ingestion
During the ingestion process, Data Breach Response sets the PI_Exception field on all documents to indicate if a document is supported or unsupported. After ingestion we recommend reviewing the PI_Exception column to verify all documents were ingested properly. The field will initially be blank, and if a document is successful, the value will be None.
Below is a list of all possible values and recommended next steps, if applicable.
| Value | Definition | Recommended next step |
|---|---|---|
| None | The file has successfully been ingested into Data Breach Response. | N/A |
| Missing File Data | The file size or extension was unable to be retrieved for the document. | This can be a result of an issue during processing or at the time of upload into the workspace. We recommend reuploading the document into the workspace before ingesting again. |
| Missing Text File | An extracted text file does not exist for the document. | Extracted file types should be provided for all document types. Ensure the document has an extracted text file before attempting to reingest it. This can be done via OCR in RelativityOne. |
| Text File Exceeds Size Limitation | The file exceeds the 75MB native size limitation for non-spreadsheets, or the 40MB limitation for spreadsheets. | The documents can be separated into multiple smaller documents below the file size limit or reviewed separately outside of Data Breach Response. |
| Unsupported Native File Extension | The file type is not supported by Data Breach Response. | Ensure all file types in the document set are supported by converting them to a supported file type, if possible. |
| Unsupported DAT Value |
The control number is missing, not assigned, or if it contains invalid text. For example, containing emojis. |
Verify the document has a valid control number. |
| Duplicate Document | The document has previously been ingested. | No action needed as this indicates that the prior ingestion was successful. |
| Other Error |
Report job states
Following is a list of report job states and descriptions:
| Batch Status | Description |
|---|---|
| Analysis (Working) | Data Breach Response pipeline is running; reports are not ready . |
| Analysis (ready-to-send) | Downloads reports published by Data Breach Response. |
| Completed | Data Breach Response results have successfully been published to RelativityOne. |
Error codes
Following is a list of error messages and corresponding codes:
| Message | Name |
|---|---|
| Unknown error occurred | Error Code 0 |
| Unrecognized step encountered | Error Code 1 |
| Unrecognized state encountered | Error Code 2 |
| Cannot transition to given step | Error Code 3 |
| Cannot transition to given state | Error Code 4 |
| BatchId already taken | Error Code 5 |
| Zip file could not be extracted | Error Code 6 |
| Zip file did not have the mandatory single file | Error Code 7 |
| Problem with file upload | Error Code 8 |
| An error occurred in file upload | Error Code 9 |
| Missing one or more required parameters | Error Code 10 |
| Unknown workspace ID | Error Code 11 |
| Unknown saved search ID | Error Code 12 |
| Unknown batch ID | Error Code 13 |
| Unexpected API call given the current state | Error Code 14 |
| Unknown exception importing to Relativity | Error Code 15 |
| Relativity import count mismatch | Error Code 16 |
| No More Report Rows | Error Code 17 |
| Privacy Ingestion Pipeline Failed to Start | Error Code 18 |
| Cargo Validation Failed | Error Code 19 |
| Header Mapping Validation Failed | Error Code 20 |
| Cargo Creation Failed | Error Code 21 |
| No Valid Documents | Error Code 22 |