






Feedback
Last date modified: 2026-Jul-17
Review validation statistics
Review Center provides several metrics for evaluating your review coverage: elusion, richness, recall, and precision. Together, these metrics can help you determine the state of your Review Center project.
Once you have insight into the accuracy and completeness of your relevant document set, you can make an educated decision about whether to stop the Review Center workflow or continue review.
This page gives a practical overview of how validation statistics are calculated. For more detailed equations, see Review Center Validation Deep Dive on the Community site.
See these related pages:
- For instructions on how to run Project Validation, see Review validation.
- For aiR for Review Prompt Criteria validation statistics, see Prompt Criteria validation statistics.
Defining elusion, recall, richness, and precision
Validation centers on the following statistics. For all of these, it reports on confidence intervals:
- Elusion rate—the percentage of unreviewed documents that are predicted as non-relevant, but that are actually relevant. The rate is rounded to the nearest single digit (tenth of a percent).
- Recall—the percentage of truly positive documents that were found by the review.
- Richness—the percentage of relevant documents across the entire review.
- Precision—the percentage of found documents that were truly positive. This statistic is only calculated if you set a cutoff when creating the validation queue.
In everyday terms, you can think of these as:
- Elusion rate: "How much of what we’re leaving behind is relevant?"
- Recall: "How much of the relevant stuff did we find?”
- Richness: "How much of the overall document set is relevant?"
- Precision: "How much junk is mixed in with what we think is relevant?"
The calculations for elusion and recall change depending on whether the validation queue uses a cutoff. For more information, see How setting a cutoff affects validation statistics.
For each of these metrics, the validation queue assumes that you trust the human coding decisions over machine predictions, and that the prior coding decisions are correct. It does not second-guess human decisions.
Validation does not check for human error. We recommend that you conduct your own quality checks to make sure reviewers are coding consistently.
Groups used to calculate validation metrics
Validation divides the documents into groups based on two main distinctions:
- Whether or not the document has been coded.
- Whether or not the document is relevant.
Together, these distinctions yield four buckets:
- Coded, not relevant—documents that have been coded as not relevant.
- Coded, relevant—documents that have been coded as relevant.
- Uncoded, predicted not relevant—documents that have not been coded and are predicted not relevant.
- Uncoded, predicted relevant—documents that have not been coded and are predicted relevant.
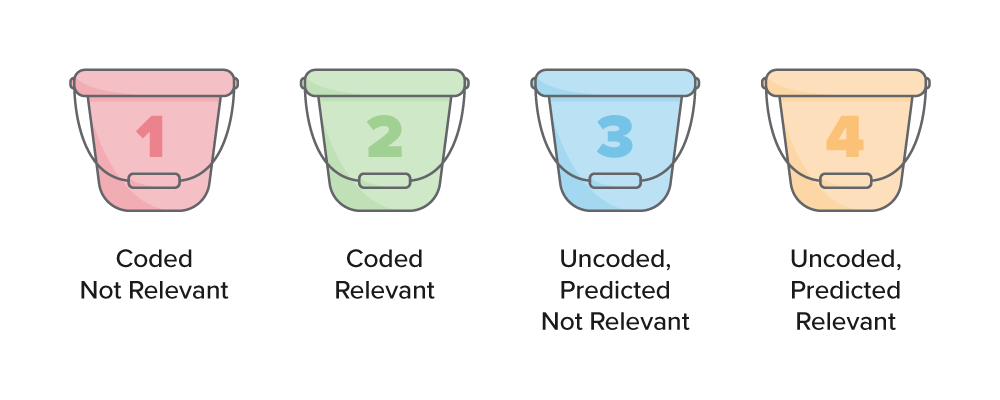
Coded and uncoded documents are separated as follows:
- Coded documents—have a positive or negative coding label.
- Uncoded documents—have not received a positive or negative coding label. This includes any documents that:
- have not been reviewed yet.
- are being reviewed at the moment the validation starts, but their coding has not been saved yet.
- were skipped.
- received a neutral coding label.
- These buckets are determined by a document's status at the start of Project Validation. For the purpose of these calculations, documents do not "switch buckets" during the course of validation.
- If you choose not to set a cutoff for your queue, buckets 3 and 4 are combined, and all uncoded documents are predicted not relevant. For more information, see How setting a cutoff affects validation statistics.
Variables used in the full calculations
When Review Center calculates the validation metrics, it also subdivides buckets 3 and 4 based on two extra distinctions:
- Whether documents were included in the sample.
- Whether the coding decisions on sample documents matched their predictions.
Together with the first two buckets, this creates a total of ten variables used in the equations:
| Variable | Full Name | Definition | Bucket Grouping |
|---|---|---|---|
| CN | Coded Negative (PRQ) | Documents coded non-responsive in the main prioritized review queue (PRQ) population | Bucket 1 |
| CP | Coded Positive (PRQ) | Documents coded responsive in the main PRQ population | Bucket 2 |
| FNs | False Negatives (Sample) | Documents predicted non-responsive but coded responsive in the sample | Sample documents coded responsive in bucket 3 |
| FPs | False Positives (Sample) | Documents predicted responsive but coded non-responsive in the sample | Sample documents coded non-responsive in bucket 4 |
| PN | Predicted Negative (PRQ) | Documents predicted non-responsive in the main PRQ population | Bucket 3 |
| PNs | Predicted Negative (Sample) | Documented predicted non-responsive in the sample (FNs + TNs) | Sample documents in bucket 3 |
| PP | Predicted Positive (PRQ) | Documents predicted responsive in the main PRQ population | Bucket 4 |
| PPs | Predicted Positive (Sample) | Documented predicted responsive in the sample (TPs + FPs) | Sample documents in bucket 4 |
| TNs | True Negatives (Sample) | Documents predicted non-responsive and coded non-responsive in the sample | Sample documents coded non-responsive in bucket 3 |
| TPs | True Positives (Sample) | Documents predicted responsive and coded responsive in the sample | Sample documents coded responsive in bucket 4 |
When you click on the metrics in the Validation Stats panel, you can see the equations using these variables, as well as a table of the variables' values for your queue.
Different regions and industries may use "relevant," "responsive," or "positive" to refer to documents that directly relate to a case or project. For the purposes of these calculations, the terms are used interchangeably.
Because this page is geared towards a general overview, the explanations here focus on the main four buckets. For a more granular breakdown using the full equations and variable set, see Review Center Validation Deep Dive on the Community site.
How setting a cutoff affects validation statistics
When you set up a validation queue, you have the choice of setting a cutoff. This cutoff rank is used as the dividing line between documents that are predicted positive or predicted negative. Setting a cutoff also enables the Precision statistic.
Depending on your choice, the calculations change as follows:
- If you set a cutoff, Review Center assumes that you still expect some of your uncoded documents to be positive. All statistics are calculated with the assumption that you plan to produce all positive-coded documents, plus all uncoded documents at or above the Positive Cutoff rank (buckets 2 and 4). These documents are considered "found."
- If you do not set a cutoff, Review Center assumes that you do not expect any uncoded documents to be positive. All statistics are calculated with the assumption that you plan to produce only the positive-coded documents (bucket 2). Only bucket 2 is considered "found." Without a cutoff, there is no bucket 4 - all uncoded documents are treated as bucket 3.
Whether or not you should use a cutoff depends on your review style. TAR1-style reviews, which focus on refining the model until it can be trusted to predict some of the positive documents, usually use a cutoff. TAR2-style reviews, which focus on having humans code all positive documents, usually do not use a cutoff.
High versus low cutoff
If you choose a high cutoff, this generally increases the precision, but lowers recall. If you choose a low cutoff, this generally increases the recall, but lowers precision.
In other words, choosing a high cutoff makes it likely that a high percentage of the documents you produce will be positive. However, it also increases the likelihood that some positive documents will be mistakenly left out. Conversely, if you choose a low cutoff, it's more likely that you may produce a few negative documents. However, you have better odds of finding ("recalling") all of the positive documents.
Validation metric calculations
Elusion rate
This is the percentage of uncoded, predicted non-relevant documents that are relevant.
The equation for elusion rate is:
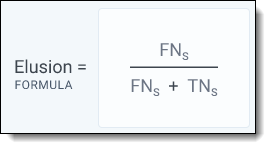
When breaking this down using the bucket method, it can be simplified as:

Elusion rate = (Relevant documents in bucket 3's sample) / (All documents in bucket 3's sample)
Elusion measures the "error rate of the discard pile" — meaning, the relevant document rate in bucket 3. Documents that were coded relevant before starting project validation are not included in the calculation, regardless of their rank score. Documents coded outside of the queue during validation count as "eluded" documents.
If you do not set a cutoff for your validation queue, this is calculated as the number of documents in the validation sample that were coded relevant, divided by the entire size of the sample.
For more details, see Review Center Validation Deep Dive on the Community site.
Elusion rate versus eluded documents
In the Review Center dashboard, a metric also appears for eluded documents. This is the number of uncoded, predicted non-relevant documents that are relevant.
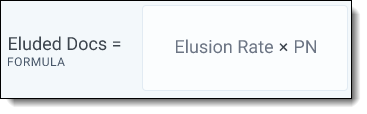
Eluded documents = Elusion rate * number of documents predicted negative
The elusion rate is a percentage, while the eluded documents statistic is an estimated document count.
Recall
Recall is the number of documents that were either previously coded or correctly predicted relevant, divided by the total number of documents coded relevant in any group.
The equation for recall is:

When breaking this down using the bucket method, it can be simplified as:
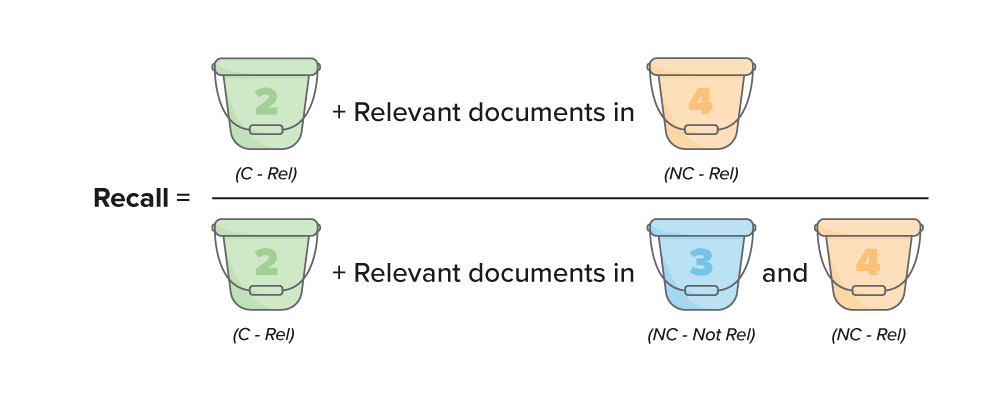
Recall = (Bucket 2 + relevant documents in bucket 4) / (Bucket 2 + relevant documents in buckets 3 and 4)
Recall measures the percentage of truly positive documents that were found by the review. Recall shares a numerator with the precision metric, but the denominators are different. In recall, the denominator is "what is truly relevant;" in precision, the denominator is "what we are producing." Documents coded outside of the queue during validation count against recall.
If you do not set a cutoff for your validation queue, this is calculated as the number of documents that were previously coded relevant, divided by the total number of documents coded relevant in any group.
For more details, see Review Center Validation Deep Dive on the Community site.
Richness
This is the percentage of relevant documents across the entire review.
The equation for richness is:

In the full equation, the numerator uses the sample to estimate the number of relevant documents in buckets 3 and 4. When breaking this down using the bucket method, it can be simplified as:

Richness = (Bucket 2 + any relevant documents found in buckets 3 and 4) / (All buckets)
Similar to recall, review validation estimates the number of relevant documents in bucket 4 by multiplying the estimated elusion rate by the number of uncoded documents. This is only done for the top half of the formula. For the bottom half, review validation only needs to know the size of the review.
For more details, see Review Center Validation Deep Dive on the Community site.
Precision
Precision is the percentage of truly positive documents out of all documents that were expected to be positive. Documents that were predicted positive, but coded negative during validation, lower the precision percentage.
The equation for precision is:
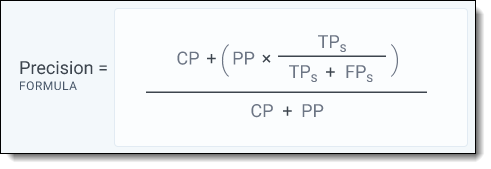
In the full equation, the numerator uses the sample to estimate the number of relevant documents in bucket 4. When breaking this down using the bucket method, it can be simplified as:
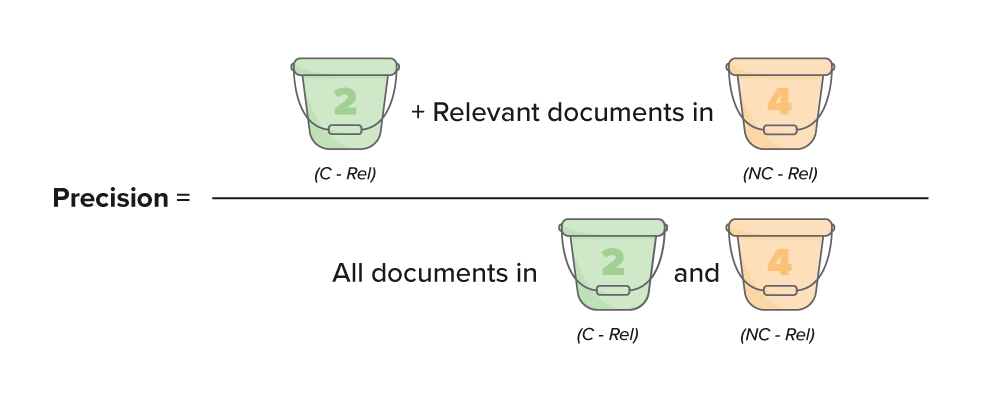
Precision = (Bucket 2 + relevant documents in bucket 4) / (All documents in buckets 2 and 4)
The precision statistic is only calculated if you set a cutoff when creating the validation queue. It assumes that you plan to produce all documents coded positive, plus all uncoded documents at or above the Positive Cutoff.
For more details, see Review Center Validation Deep Dive on the Community site.
How the validation queue works
When you start validation, the system puts all sampled documents from buckets 3 and 4 into the queue for reviewers to code.
Documents coded during project validation do not switch buckets during the validation process. Documents that started in buckets 3 and 4 are still considered part of 3 and 4 until validation is complete. This allows the system to keep track of correct or incorrect predictions when calculating metrics, instead of lumping all coded documents in with those which were previously coded.
Review Center reports statistics after all documents in the sample are reviewed. A document is considered reviewed if a reviewer has viewed the document in the Viewer and has clicked Save or Save and Next.
How validation handles skipped and neutral documents
We strongly recommend coding every document in the validation queue as relevant or non-relevant. Skipping documents or coding them neutral lowers the randomness of the random sampling, which introduces bias into the validation statistics. To counter this, Review Center gives conservative estimates. Each validation statistic counts a skipped or neutral document as an unwanted result.
The following table shows how skipped or neutral documents negatively affect each statistic.
| Skipped or Neutral Document | Effect on Elusion | Effect on Recall | Effect on Richness | Effect on Precision |
|---|---|---|---|---|
|
Increases elusion rate (Counts as relevant) |
Lowers recall rate (Counts as relevant) |
Raises richness estimate (Counts as relevant) |
(No effect) |
|
(No effect) |
Lowers recall rate slightly (Counts as if it weren't present) |
Raises richness estimate (Counts as relevant) |
Lowers precision rate (Counts as non-relevant) |