






Feedback
Last date modified: 2026-Apr-14
Textual near duplicate identification results
After running a textual near duplicate identification operation, we recommend reviewing the results using the following:
- Setting up a Textual Near Duplicates view for a structured analytics set
- Assessing similarities and differences with Document Compare
- Viewing the Textual Near Duplicates Summary
- Viewing Near Dup Groups in the related items pane
See Using near duplicate analysis in review for more details on near duplicates.
Setting up a Textual Near Duplicates view for a structured analytics set
To view the results of a specific Textual Near Duplicate Identification structured analytics set, we recommend creating a Textual Near Duplicates view for the structured analytics set on the Documents tab. For more information on creating views,
The blue line between rows separates each textual near duplicate group.
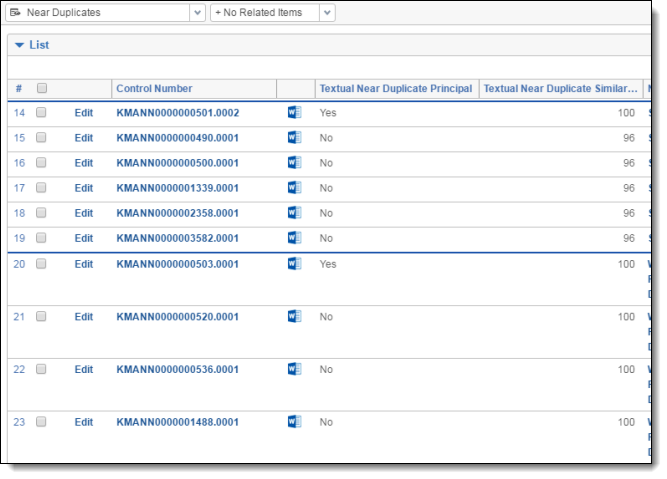
Textual Near Duplicates view advanced settings
Select the following options when creating the Textual Near Duplicates view:
- Group Definition - the relational field that is selected for the Destination Textual Near Duplicate Group field on the structured analytics set layout (such as Textual Near Duplicate Group).
Textual Near Duplicates view fields
Add the following output fields to your Textual Near Duplicates view:
- <Structured Analytics Set prefix>::Textual Near Duplicate Principal - identifies the principal document with a "Yes" value. The principal is the document in the duplicate group with the most words. It acts as an anchor document to which all other documents in the near duplicate group are compared. If the document does not match with any other document in the data set, this field is set to No.
- <Structured Analytics Set prefix>::Textual Near Duplicate Similarity - the percent value of similarity between the near duplicate document and its principal document. If the document does not match with any other document in the data set, this field is set to 0.
- <Structured Analytics Set prefix>::Textual Near Duplicate Group - this is the field that acts as the identifier for a given group of textual near duplicate documents. If the document contains text but does not match with any other document in the data set, this field is empty. Documents that only contain numbers or that do not contain text will have the <Structured Analytics Set prefix>::Textual Near Duplicate Group field set to Numbers Only or Empty, respectively.
Textual Near Duplicates view conditions
To only return documents included in textual near duplicate groups for a specific structured analytics set, set the following condition:
- <Structured Analytics Set prefix>::Textual Near Duplicate Group : is set
Optionally, you can exclude the documents that were in the Structured Analytics set but were excluded for not containing text or only containing numbers. You may add either or both of the following additional conditions using the AND operator to exclude these documents as well.
- <Structured Analytics Set prefix>::Textual Near Duplicate Group : is not - empty
- <Structured Analytics Set prefix>::Textual Near Duplicate Group : is not - numbers-only
Textual Near Duplicates view sorting
Configure ascending sorts on the following fields in your Textual Near Duplicates view to list the textual near duplicate principals with the highest percentage of textual near duplicate similarity for a specific structured analytics set at the top of the screen:
- <Structured Analytics Set prefix>::Textual Near Duplicate Group - Ascending
- <Structured Analytics Set prefix>::Textual Near Duplicate Principal - Descending
- <Structured Analytics Set prefix>::Textual Near Duplicate Similarity - Descending
Assessing similarities and differences with Document Compare
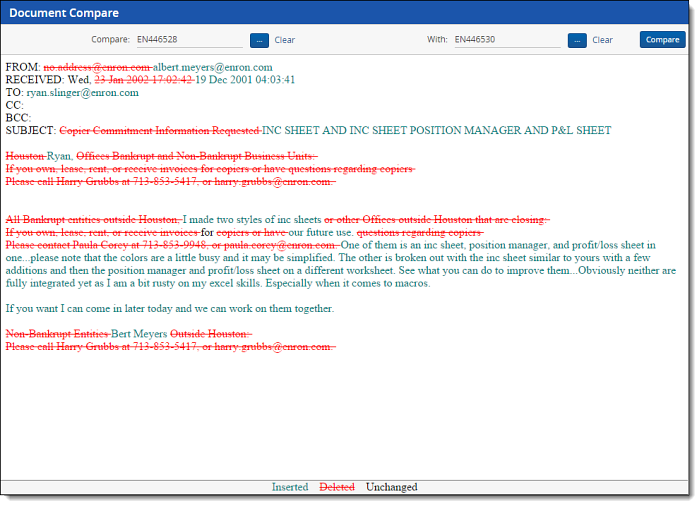
You can use the Document Compare function to compare two documents to assess their similarities and differences.
You may notice variations between the Document Compare Similarity and Near Duplicate Similarity scores. This difference occurs because Document Compare takes formatting and white spaces into account.
Viewing the Textual Near Duplicates Summary
You can also view the Textual Near Duplicates Summary to quickly assess how many textual near duplicates were identified in the document set. On the Structured Analytics Set console, click the Textual Near Duplicates Summary link to open the report.
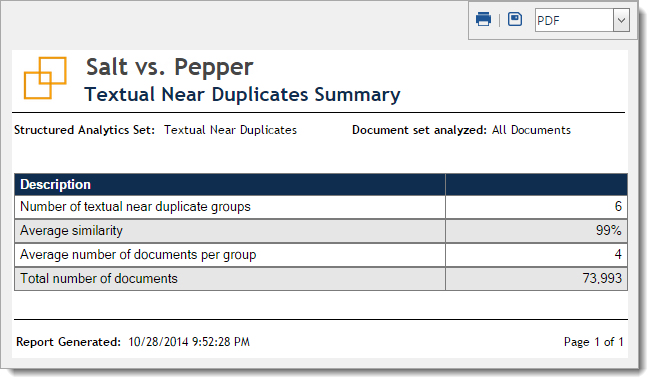
This report lists the following information:
- Number of textual near duplicate groups - the total number of groups identified.
- Average similarity - the sum of all of the similarity scores divided by the number of textual near duplicate groups.
- Average number of documents per group - the total number of documents divided by the number of textual near duplicate groups.
- Total number of documents - the total number of documents in the textual near duplicate groups.
If you run a second structured analytics set, it overwrites the reports from the first set. We recommend saving the reports as soon as you finish building the set.
Viewing Near Dup Groups in the related items pane
You can view structured data analytics results in the related items pane within the document Viewer.
In the lower right of the related items pane, a series of icons appear. These control what appears in the pane. The icons and their tooltip text can vary, depending on how you created the fields for the structured analytics set. However, some common ones include:
- Thread Group—displays all messages in the same thread group as the selected document.
- Email Duplicates—shows all messages identified as duplicates of the selected document.
- Near Dup Groups—shows all items that are textual near duplicates of the selected document.
After deploying the Analytics application, you can create fields that propagate coding choices to these structured analytics related groups.
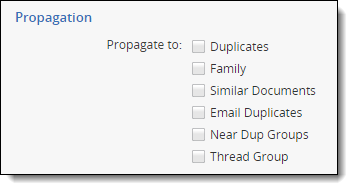
Be very careful when using propagation. We recommend against turning propagation on for your responsiveness fields. For example, if you mark an email within a group as not responsive, other potentially responsive emails within the group could be automatically coded as not responsive.