






Feedback
Last date modified: 2026-Mar-10
General settings
General settings apply to all aiR for Privilege projects within the workspace and must be populated prior to starting any aiR for Privilege project.
You should only update the fields in the General Settings section between projects, as changes won’t apply to projects that have already completed the Prepare Project pipeline step.
To update general settings:
- Hover over the aiR for Privilege icon on the navigation bar.
- Hover over Setup (Priv).
- Select General Settings (Priv).

- Complete the General Settings form.
Categories and fields for each section are listed below.
- Click Save.
There are three sections in the General Settings section:
Reviewer Privilege Decision Mapping
Client Brain
Knowledge from past projects is stored in a Client Brain. The Client Brain can kick start a project and create consistency across multiple projects. Each client, as defined by the Client object linked to a workspace, will have its own segregated Client Brain.
Privilege projects can only use or update the Client Brain associated with the Client object linked to the workspace they exist in. Only accounts associated with a specific client domain can access Client Brains for that domain. They cannot view Client Brains belonging to other domains within the same instance.
Consider whether you currently align the Client Objects to a Law Firm or a Corporation to understand the implications when using the Client Brain.
Client Brain fields
| Field | Field type | Required field | Description | Notes |
|---|---|---|---|---|
|
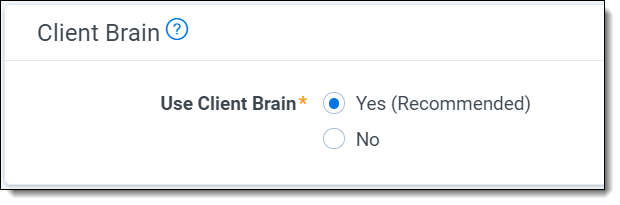
Use Client Brain |
Yes/No | Required | This setting determines whether you want to use knowledge stored in the Client Brain associated with the Client object linked to this workspace, and update the Client Brain with new learnings from any project you complete in this workspace. |
It is highly recommended that you use the Client Brain as it will reduce the annotation time for your project and create consistency across projects. Consider how you currently align the Client Object to understand the implications before electing to use the Client Brain. If this is your first project for a client, you should select Yes to make sure a Client Brain is created for the client and knowledge is retained. |
Reviewer Privilege Decision Mapping
These settings indicate the fields you use for privilege coding.
Provide the field and choices used by your team to code a document as privileged. All choices that indicate any type of privilege should be included as positive choices (Wholly Privileged, Partially Privileged, etc.)
| Field | Field type | Required field | Description | Notes |
|---|---|---|---|---|
| Reviewer Privilege Decision Field (Single Choice or Multiple Choice) | Single choice | Required |
Used to select the document field that indicates privilege decisions. |
|
| Reviewer Positive Privilege Decision Choice | Multiple choice | Required |
A dynamically populated selection of choices associated with the document field indicated in the Reviewer Privilege Decision Field setting. This field only appears after you make a selection on the Reviewer Privilege Decision Field. |
You can choose any word that indicates a positive response, which will mark the document as privileged. |
Document Field Mapping
These settings specify the document fields used in a project for analysis.
It is important that these fields are both mapped correctly, and that documents appropriately include values for these mapped fields. Incorrectly mapping or missing document values may cause poor results or failures. Double check these mappings and the documents before starting any project. We suggest creating a document view that includes your mapped fields so you can quality check (QC) the data completeness and quality before starting a project.
| Field | Field type | Required field | Description | Notes |
|---|---|---|---|---|
|
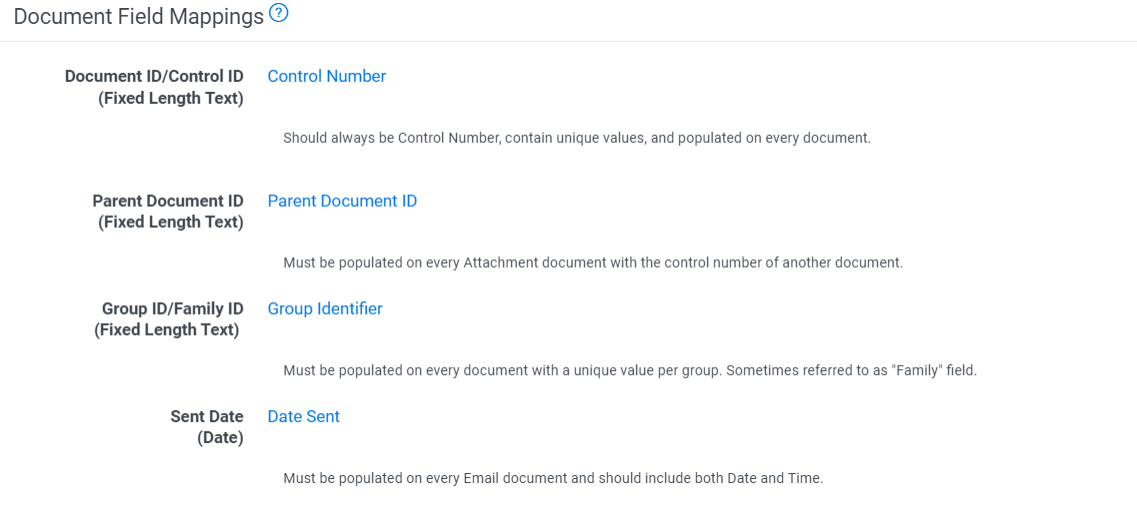
Document ID/Control ID (Fixed Length Text) |
Fixed-length text | Required | Used to identify the document. | The control number. Should always be unique, and should always exist on a document. |
|
Parent Document ID (Fixed Length Text) |
Fixed-length text | Required | Used to determine if a document is an attachment and what document is it an attachment of. |
Should contain the control number of another document. Must be populated for attachments. |
|
Group ID/Family ID (Fixed Length Text) |
Fixed-length text | Required | Used to determine all documents that are associated to one another by way of parent or attachment. | Populated for all documents, with a unique value per group. |
|
Sent Date (Date) |
Date | Required | Used to understand when an email document was sent. |
Should include both date and time normalized to UTC time. Must be populated on every email document. Should include both date and time normalized to UTC time. |
|
Sent Time (Fixed Length Text or Long Text) |
Fixed-length text | Optional | Used to determine the time an email document was sent if the time was not included in the sent date setting. | Should be in the following format in UTC time: {04:46:02 PM} |
|
Record Type (Single Choice or Fixed Length Text) |
Single choice | Required | Used to determine whether a document is an email or not. |
A value of Email or email is classified as an email, while all other values are considered a non-email. Must be populated on every document. |
|
File Name (Fixed Length Text of Long Text) |
Fixed-length text | Required | Used to determine the name of the file. | You can use Unified Title as an alternative to File Name during field mapping to determine the name of the file. We recommend using whichever is more complete. |
|
File Extension (Single Choice or Fixed Length Text) |
Fixed-length text | Required | Used to determine the type of file to drive file specific analysis. | |
|
Author (Single Choice or Fixed Length Text or Single Object) |
Fixed-length text | Required | Used to determine the individual who created the document. | Should be populated on non-email documents with the individual who created the file. |
|
Custodian (Single Choice or Fixed Length Text or Single Object) |
Single object | Required | Used to determine the individual who this document was collected from. |
Must be a single custodian value rather than a multiple custodian deduplicated value. Must be populated on every document. |
|
Email Subject |
Long text | Required | Used to determine the subject of an email. | |
|
Email From (Fixed Length Text or Long Text) |
Fixed-length text | Required | Used to determine the email address that sent the email. | Must be populated on every email document and include only a single email address. |
| Email To (Long Text) | Long text | Required | Used to determine the email addresses that the email was sent to. | Can include multiple semi-colon delimited email addresses. |
|
Email CC (Long Text) |
Long text | Required | Used to determine the email addresses that are carbon copied (cc) on the email. | Can include multiple semi-colon delimited email addresses. |
|
Email BCC (Long Text) |
Long text | Required | Used to determine the email addresses that are blind carbon copied (bcc) on the email. | Can include multiple semi-colon delimited email addresses. |
|
MD5 Hash (Fixed Length Text) |
Fixed-length text | Required | Used to determine the unique MD5 hash value for each document. | Must be populated for all documents. |
|
Extracted Text (Long Text) |
Long text | Required | Used to determine the Extracted Text field where the document text exists. | Most of the time this will be the Extracted Text field but could be an OCR Text field or Translated Text field. |
|
Extracted Text Size in KB (Decimal) |
Decimal | Required |
Used to determine what documents to exclude from text analysis because they are greater than our 170KB limit. See Considerations for more details. |
If you do not have this field populated, you can use the Set long text field size mass operation to populate this information. Must be populated for all documents. |
Validating document field mappings
To prevent downstream issues, we recommend manually validating document field mapping selections. This is very important as there are times when the validation we have implemented doesn’t catch a document, metadata, or extracted text. This can cause issues with our pipeline steps.
To validate document field mappings:
- Navigate to the General Settings (Priv) tab.
- Scroll to the Document Field Mappings section.
- Take note of the fields mapped for each setting.
- Navigate to the project in question.
- Take note of the saved search used for the project.
- Navigate to the Document tab.
- Create a new saved search.
- Add the search condition of Saved Search=[saved search linked to project].
- Add each field that was mapped in settings as Fields on the new saved search.
- Save and Search.
- Perform the following manual validation. If any fail, that field may be missing data or incorrectly mapped.
- Validate that each field has at least one document populated with a value on the field.
- Validate that your extracted text field has real data.
- Validate that you have a Record Type value of email on documents.
- Validate that email addresses are semicolon delimited in the email specific fields.
- Validate the Time on your Sent Date field to see if they are all 12:00AM, which is the default if time is provided.
- Validate that all documents have a value under Record Type.
- Validate that all documents have a value under Extracted Text in KB.