






Feedback
Last date modified: 2026-Apr-17
Calculate accuracy
Calculating accuracy, specifically precision and recall, is crucial to understanding the model’s performance. You can use precision and recall analysis to better understand how aiR for Privilege performs with any data set and help guide the prioritization of reviewing documents in future batches.
Key concepts
Following are key concepts to consider when calculating the accuracy of aiR for Privilege.
- Precision—measures the accuracy of the positive predictions made by the model or the percentage of documents in the predicted privileged document population that are truly privileged.
- Recall—measures the ability of the model to identify positive results or the percentage of truly privileged documents that were predicted to be privileged by the model.
Considerations
Following are considerations to keep in mind when calculating the accuracy of aiR for Privilege.
- aiR for Privilege analyzes documents within the four corners of each document. To calculate accuracy metrics, compare the aiR for Privilege prediction to privilege codings of documents on their own (vs. privilege due to a family relationship).
- Documents with the category of Errored should not be included when calculating accuracy. We recommend redirecting aiR for Privilege document errors (Priv::Category is “Errored”) to an exception workflow rather than treating them as a positive or negative prediction. These documents are excluded from the performance calculations.
Identifying input numbers
Calculating accuracy requires the following numbers from documents included in an aiR for Privilege project that also have a final privilege coding.
- True Positives—the number of documents that aiR for Privilege and the reviewer agree are privileged on their own.
- False Positives—the number of documents that aiR for Privilege predicted are privileged and the reviewer deemed are not privileged on their own.
- False Negatives—the number of documents that aiR for Privilege predicted are not privileged, and the reviewer identified as privileged on their own.
- True Negatives—the number of documents that aiR for Privilege and the reviewer agree are not privileged on their own.
In general, the documents that aiR for Privilege predicts are privileged are the ones where Priv::Prediction is Privileged and the Priv::Category is not Errored.
For a more granular analysis, use conditions to specify a Priv::Category.
The quickest way to identify these numbers is to create a widget to help tally the results. Group by the Privileged on Own field, and pivot on Priv::Prediction and Priv::Category.
This should produce a widget that looks like this:
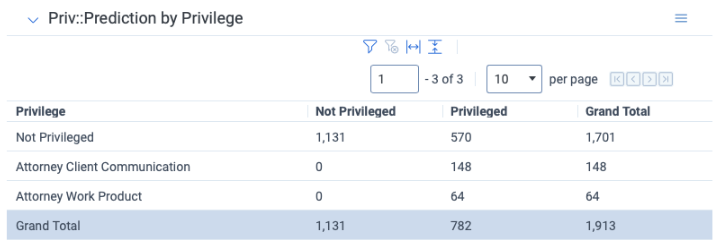
Compile the tallies by adding up the following totals:
- True Positives:
- Privilege is “Privileged on Own”
- Priv::Prediction is “Privileged”
- Priv::Category is NOT “Errored”
- False Positives:
- Privilege is “Not Privileged on Own”
- Priv::Prediction is “Privileged”
- Priv::Category is NOT “Errored”
- False Negatives:
- Privilege is “Privileged on Own”
- Priv::Prediction is “Not Privileged”
- Priv::Category is NOT “Errored”
- True Negatives:
- Privilege is “Not Privileged on Own”
- Priv::Prediction is “Not Privileged”
- Priv::Category is NOT “Errored”
Use the following formulas to calculate statistics:

For confidence intervals on these statistics, use the Confidence interval for a proportion calculator or similar.
For each statistic, enter the denominator (bottom) of the fraction for N (sample size) and the numerator (top) of the fraction for x. Note that the “effective” sample size entered into the calculator will differ from the size of sample created in Relativity. This is because some documents in the evaluation sample do not contribute to the estimation of that statistic.
Because each dataset may have different distributions of Precision and Recall. These accuracy metrics can help drive where to prioritize review time for future projects in this workspace.
Identify Underpredictions when Priv on Own codings are unavailable
If comparing the results of aiR for Privilege to a pre-coded dataset, discrepancies between the prediction and original codings may appear if the original codings were completed inclusive of family members. To best understand the accuracy of predictions, compare aiR for Privilege’s predictions to codings of documents that are Priv on Own.
If that field does not exist, the following steps will help identify documents that would have been considered underpredictions if aiR for Privilege’s prediction were propagated to family members.
- Create a new Saved Search identifying family inclusive
- Priv::Prediction = “Privileged”
- Related Items = “+Family”
- Use the results of the Saved Search to create a List called Predicted Privileged + Family.
- Create a new Saved Search identifying documents that were truly missed:
- Priv::Category = “Not Privileged”
- Privilege is NOT “Not Privileged”
- List is NOT these conditions: “Privileged + Family”
Review each document and evaluate if the Rationale/Considerations are correct.