






Feedback
Last date modified: 2026-Mar-23
Factors that affect processing throughput
This topic explains several factors that may affect processing throughput, or performance for processing discover and publish jobs. If you consistently experience lower-than-usual throughput, check to see if any of the following factors are impacting job performance.
Calculating processing discover throughput
Processing discover throughput is defined as the amount of concurrent processing work performed on a customer’s RelativityOne instance in a given time period. Processing discovery throughput is expressed in gigabytes per hour (GB/hr) and is calculated by adding the size of the data discovered from all of the processing jobs running on the instance, then dividing by the amount of time for the data to process, when at least one processing job was running.
For instance, in the image below, between 1 PM and 4 PM, there are three processing jobs running and 240 GB (80+120+40) of data is discovered in 2.5 hours (3 hours - 0.5 hours when no processing job was running). So, the processing throughput is 240/2.5 = 96 GB/hr.
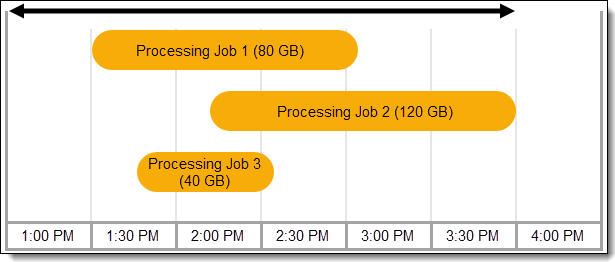
Discover job performance
The following content discusses common factors that may affect discover job throughput.
Factors related to the processing discover job
The discovered size of the dataset can be larger than the raw data size for compressed files.
Compressed files such as .pst, .zip, .mbox, Google Workspace, or Lotus Notes have a discovered dataset size that is larger than the raw dataset after processing discovery completes. In general, e-discovery practitioners use an estimated 1.5 - 2 times the rate for data expansion. So, a 50 GB .pst files which processed at a speed of 50 GB/hr could expand to 100 GB after discovery. Throughput speeds can vary accordingly.
The discovered dataset size depends on the compression type used during data collection and preparation. You can change the compression method for many of these file types, so discovered sizes will differ greatly. To see a a table of supported container types, see Supported container files types.
The data within the raw dataset can affect the discovered data size. Multimedia audio, video files, large text files, and large images will compress well and then expand later leading to higher than 2 times the discovered data size.
Customers can compress an already compressed container into a zip and have a multiple-level deep compressed file that is easier to upload (a single large file instead of many small files).
During discovery, multiple levels of a deep compressed file can reduce processing speed as processing resources are spent to get to the files, rather than discovering them. You should balance the need to zip files with processing speed, and only have one-level deep containers when possible, or decompress files as much as possible before discovering.
You should limit the number of passwords stored in the password bank to 100. Relativity attempts each password for every encrypted document, which ultimately reduces discovery speed. For example, it takes approximately 0.4 seconds per password per file to decrypt and with 4000 passwords, your processing time can increase by more than 26 minutes. It takes 10 times as long for Relativity to try 1000 passwords then for 100 passwords.
Additionally, the type of document in the dataset can also affect a processing job with too many stored passwords. For example, a large encrypted Excel file takes longer to process than encrypted Word files.
Relativity distributes processing compute resources equally across all of the jobs in a workspace and across all of the workspaces in an instance. Individual job throughput can be affected when multiple jobs are running.
You can manually change the priority of a processing job from the Imaging and Processing Queue tab. Processing resources shift to the priority job.
When running multiple processing jobs concurrently, changing the priority level to a lower number (higher priority) results in all available resources focusing solely on that task until its completion, potentially delaying the progress of other tasks. Additionally, job priority is at the instance level. A higher-priority job in one workspace can affect the completion of a lower-priority job in another workspace.
For example, if you have the following:
Processing Set A: Priority 10
Processing Set B: Priority 10
Processing Set C: Priority 20
Processing capacity is spread equally on jobs A and B. Job C waits on these sets to complete before starting.
Factors related to the files in the processing discover job
Large files over 10 GB process faster than smaller files less than 10 GB as there is more resource startup time involved with the processing of small files. If a dataset has a large number of files, the startup time on the files increases, making the dataset slower. You will see higher GB/hr throughput processing 10 files that are 10 GB each versus 10 files that are 10 KB each.
Generally speaking, a dataset with a low file count per GB of data is faster than a dataset with high file count per GB. For example, you will see higher GB/hr throughput processing 10 files that are 10 GB each versus 100 files than are 1 GB each. You can affect throughput of a processing job depending on how you bring in data within the dataset.
Certain file types such as large encrypted Excel files, deeply nested emails, or large 7-zips greater than 350 MB, .tar, .e01 and .l01 take longer to ingest data, compared to simpler file types such as email documents, thus affecting processing throughput. Similarly, text extraction is significantly slower with datasets containing large .pdf files needing OCR (when the system is performing OCR on them). Even 1-2 MB .pdf files, .png, .tiff, .jpeg, .cad, and other graphical image files can take several minutes to OCR if the embedded images have high resolution.
Processing profile settings that may impact discover job performance
- Text Extraction Method—the type of text extraction method used on the processing profile. Relativity internal performance testing has shown that Relativity text extraction method to be at least two times faster than the native method on Excel, Word, and PowerPoint file types. The method is also less error-prone than native.
- OCR Accuracy—the processing job performance is heavily impacted based on the OCR Accuracy setting chosen on the processing profile. A higher accuracy OCR can result in better text for scanned documents and images but at the cost of performance. Do not use the high OCR accuracy unless needed, as it impacts the performance of processing jobs. You can achieve good OCR results with low and medium accuracy levels.
Publishing job performance
The following content discusses common factors that may affect publish job throughput.
Factors related to the processing publish job
- Other publish processing job—a workspace can only have one publish job running deduplication and control number generation phases of publish at a time. If you have multiple publish jobs running on the workspace at the same time, the publish job in the queue waits for the running publish job to finish the deduplication process and control number generation phases before the publish job in the queue can start.
- Post-publish delete job—post-publish document deletion jobs have lower priority than other publish jobs in the workspaces and are deferred till all publish jobs finish. If a delete job is in progress and a publish job is submitted, the delete job will safely pause after a few moments for the publish job to start. The delete job resumes after the publish job completes.
Be aware of the number of mapped fields in your workspace. Having more than 100 fields mapped may affect the processing publish job performance.
Be sure that processing metadata fields are mapped to the right field type in Relativity. Mapping a metadata field such as Email Participants to a long text field or a choice field, when the field can have a large number of choices or values, will negatively impact publish performance.
Processing profile settings that may impact publish job performance
- Propagate deduplication data—setting this field to Yes applies the data from the mapped deduplication fields (such as the deduped custodians, deduped paths, all custodians, and all paths fields) from the parent to the children documents so that you can meet production specifications and perform searches on those fields without having to include family or manually overlay those fields. Setting this field to Yes is not recommended unless your use case needs it, as the feature reduces performance when turned on due to the time it takes to overlay the fields onto the children.
- Do you want to use source folder structure—setting this field to Yes keeps the folder structure of the source of the files you process when you bring the files into Relativity. This field slows job time if enabled as it reconstructs the folder and inbox structure in the documents tab.