






Document ingestion
The PI Detect application accomplishes two main tasks when transferring data from a RelativityOne instance to a PI Detect server:
- The application transfers the data to PI Detect.
- When the transfer is complete, the application automatically starts the Document Ingestion pipeline, and preps new documents on the server to be run through the Incorporate Feedback pipeline.
Permissions
Document Ingestion is only available for users assigned the role of Lead.
Navigating to document ingestion
Navigate to the Document Ingestion tab on the left-side dashboard. Only Project Leads can use Document Ingestion to ingest documents into PI Detect.

Overview tab
When Document Ingestion is running, the Overview tab shows information about in progress stages of ingestion.
When Document Ingestion is not running, it displays information about the last run. Information about earlier runs of Document Ingestion can be viewed by using the Select Round to View drop down.
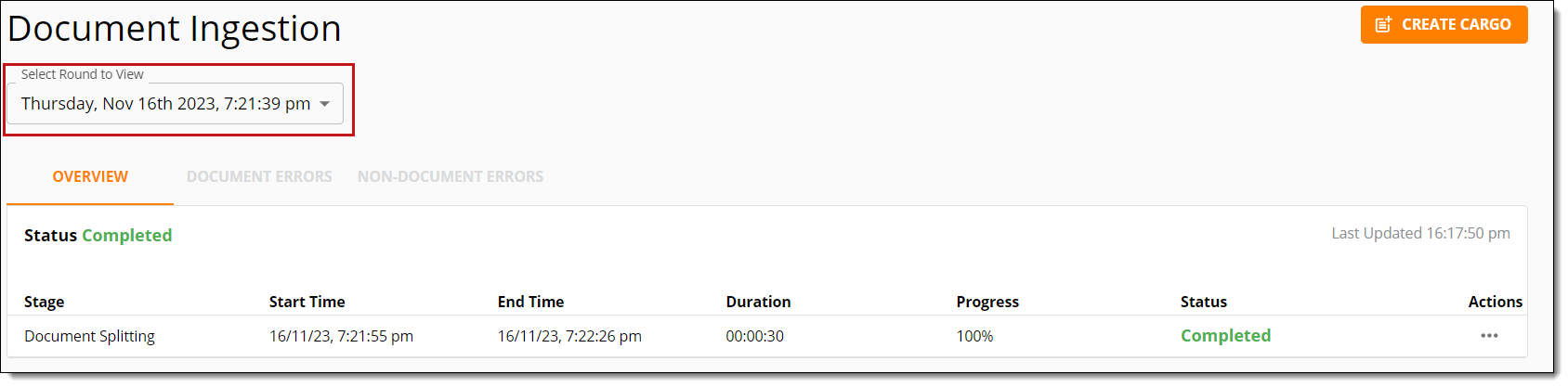
The Overview tab contains the following information:
- Status—the progress of Document Ingestion as a whole. The status can be:
- In Progress—document Ingestion is running.
- Completed—document Ingestion completed successfully.
- Completed with Failures—document Ingestion completed with errors.
- Stage—the name of the Document Ingestion stage.
- Start Time—the time a stage started running.
- End Time—the time a stage stopped running.
- Duration—the run time of a stage.
- Progress—an indicator of stage progress when Document Ingestion is running.
- Status—the status of a stage. Statuses can be:
- Not Started—the stage has not begun.
- Still Running—the stage is in the middle of processing.
- Completed—the stage has finished processing successfully.
- Completed with Failures—the stage has finished processing and some items encountered failures during processing.
- Failed—the stage has finished processing and many items encountered failures during processing, so the stage as a whole has failed.
- Skipped—the stage was not run.
- Interrupted—the stage stopped in the middle of processing.
- Actions—utsed to select more actions for the document ingestion process.
Document errors and non-document errors
The Document Errors tab shows documents that encountered errors while Incorporate Feedback was running, and what those errors are. For a detailed description of possible errors and flags and their resolutions, see Errors and flags. The following information appears on this tab:
- Document ID—the ID of the impacted document.
- Document Flags—the error flag applied to the document during Incorporate Feedback.
- Error Message—the error message.
- Detection Stage—the stage that the document encountered the error.
The Non-Document Errors tab will show errors that occurred during non-document-based processes. For a detailed description of possible errors and flags and their resolutions, see Errors and flags. The following information is displayed on this tab:
- Error Type—the type of error that occurred.
- Error Message—the error message.
- Errored Item Name—the item that caused the error.
Ingesting documents
The Document Ingestion pipeline will automatically start when running an ingestion job via the PI Detect application. For instructions on how to run an ingestion job, see Ingesting documents.
When document ingestion is running, stages can have one of several statuses:
| Status | Description |
|---|---|
| Not Started | The stage has not begun. |
| Still Running | The stage is in the middle of processing items. |
| Completed | The stage has finished processing all items successfully. |
| Completed with Failures | The stage has finished processing all items and some items encountered failures during processing. |
| Failed | The stage has finished processing all items and many items encountered failures during processing, so the stage as a whole has failed. |
| Skipped | The stage was not run. |
| Interrupted | The stage stopped in the middle of processing. |
Troubleshooting
Following are troubleshooting options for common document ingestion issues:
Failed start ingestion pipeline batch in the PI Detect application
If the Start Ingestion Pipeline batch has failed or appears stuck in the PI Detect application, take the following actions:
Delete the cargo
- Navigate to the PI Detect instance.
- Open the Settings tab and select the Cargo Management tab.
- From the table, delete the cargo that was ingested with the failed ingestion job.
- In RelativityOne, navigate to the ingestion job.
- Select the Start Ingestion Pipeline batch and select Retry.
If the Start Ingestion Pipeline batch fails or appears stuck again, repeat steps 1-3, then run document ingestion manually.
Run document ingestion manually
To start the Document Ingestion pipeline manually, the first step is to enter information about the location of the data.
- From the Cargo Management tab, select the Run Document Ingestion button.
- In a new tab, navigate to the Data Breach and Personal Information Application ingestion job in your RelativityOne instance that you used to send data to PI Detect.
- From the Job Details screen, copy, and paste the Natives and Text Files and DAT File paths into the Natives and Text Files and DAT File fields in PI Detect.
- Click Submit.Note: Do not exit out of this modal after clicking submit on the Select Batch screen, as this may result in issues ingesting the documents. If you close the modal while on the Header Mapping or Start Document Ingestion screens before the ingestion job begins, follow the instructions in Delete the cargo.
- To map the DAT file header values to the equivalent PI Detect headers, select a value in the TIQ Headers column and select the equivalent header from the DAT Headers in the right column. Headers highlighted in blue are required to be mapped, while grey headers are optional. The headers are now mapped.
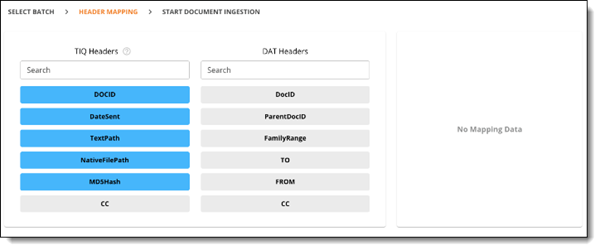
- Repeat for the remaining headers and click Submit.
- Select Run Document Ingestion.

To start the Incorporate Feedback pipeline immediately after Document Ingestion completes, select Run Incorporate Feedback on Completion.
Failed document ingestion pipeline stage
If a stage has failed or completed with failures, navigate to the Document Errors and Non-Document Error tabs to view a list of the errors encountered during ingestion. For the list of errors and suggested next steps, see Errors and Flags.