






Use Inventory to narrow down your files before discovering them by eliminating irrelevant raw data from the discovery process through a variety of preliminary filters. With inventory you can exclude certain file types, file locations, file sizes, NIST files, date ranges, and sender domains. Doing this gives you a less-cluttered data set when you begin to discover your files.
(Click to expand)
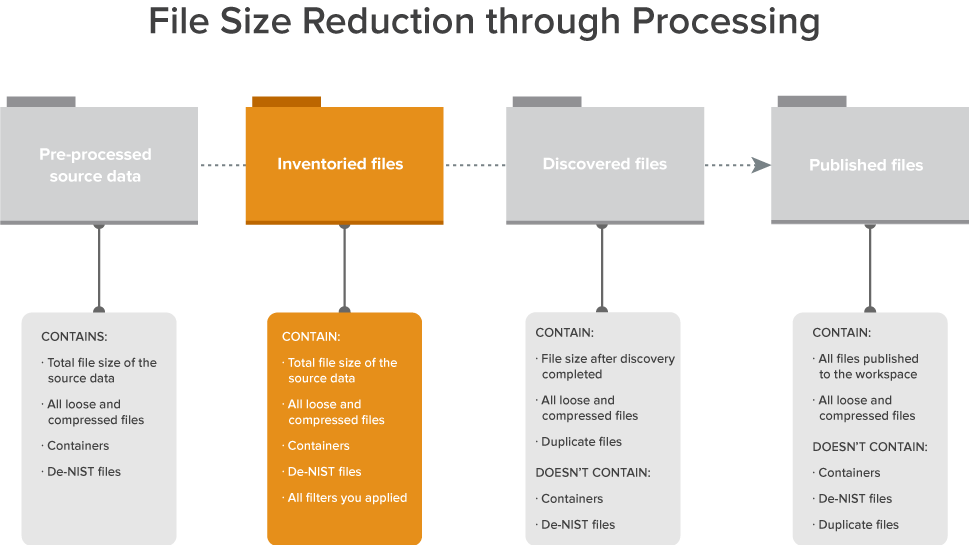
Inventory reads all levels of the data source, including any container files, to the lowest level. Inventory then only extracts data from first-level documents. For example, you have a .ZIP within a .ZIP that contains an email with an attached Word document, inventory only extracts data up to the email. Deeper level files are only extracted after you start Discovery. This includes the contents of a .ZIP file attached to an email and the complete set of document metadata.
You aren't required to inventory files before you start file discovery. Note, however, that once you start file discovery, you can’t run inventory on that processing set, nor can you modify the settings of an inventory job that has already run on that set.
Note: Inventory isn't available in the Relativity Processing Console.
 The content on this site is based on the most recent monthly version of Relativity, which contains functionality that has been added since the release of the version on which Relativity's exams are based. As a result, some of the content on this site may differ significantly from questions you encounter in a practice quiz and on the exam itself. If you encounter any content on this site that contradicts your study materials, please refer to the What's New and/or the Release Notes for details on all new functionality.
The content on this site is based on the most recent monthly version of Relativity, which contains functionality that has been added since the release of the version on which Relativity's exams are based. As a result, some of the content on this site may differ significantly from questions you encounter in a practice quiz and on the exam itself. If you encounter any content on this site that contradicts your study materials, please refer to the What's New and/or the Release Notes for details on all new functionality.The following is a typical workflow that incorporates inventory:
- Create a processing set or select an existing set.
- Add data sources to the processing set.
- Inventory the files in that processing set to extract top-level metadata.
- Apply filters to the inventoried data.
- Run discovery on the refined data.
- Publish the discovered files to the workspace.
Note: You can't use Inventory (in Processing) on IE 8. You can only use Inventory on IE 9 and 10.
Using Inventory and file filters
You're a project manager, and your firm requests that you create a processing set that includes a purposefully large data set from a custodian, with loose files and multiple email PST files. They then want you to eliminate all emails from a repository created in 2012, because those pre-date the case and are not admissible.
To do this, you inventory your data sources, click Filter Files on the processing set console, load the inventoried set in the filtering files, and apply a Location filter to exclude the location of the “2012 Backup.PST” container.
You can then move on to discover the remaining files in the set.
Running inventory
To inventory the files found in a processing set's data source(s), click Inventory Files on the processing set console. This option is only available if you've added at least one data source to the processing set.
(click to expand)
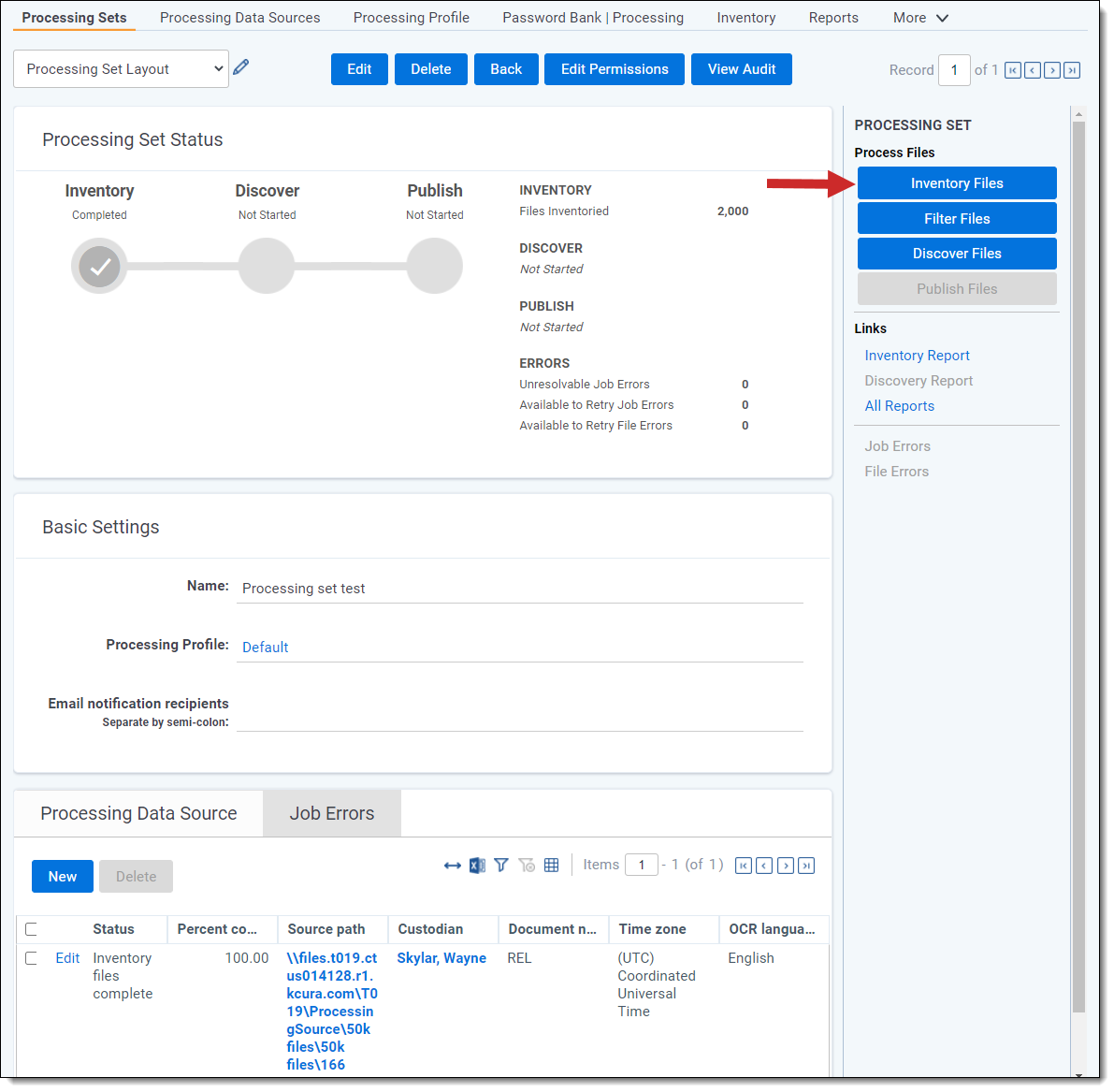
Note: The default priority for all inventory jobs is determined by the current value of the ProcessingInventoryJobPriorityDefault entry in the Instance setting table.
The Inventory Files button on the console is disabled in the following situations:
- There are no data sources associated with the processing set
- The processing set is canceled
- The processing set has already been discovered or published
- A discovery, retry discovery, publish, republish, or retry publish job is in the queue for the processing set
When you start inventory, the Inventory Files button changes to Cancel. You can use this to cancel the processing set. For more information, see Canceling inventory.
Note: The processing set manager agent sends the password bank to the processing engine when you start inventory. If a custodian is associated with a Lotus Notes password bank, that custodian's information is sent with the inventory job.
You can re-inventory files any time after the previous inventory job is complete. For more information, see Re-inventory.
Inventory process
The following graphic and corresponding steps depict what happens behind the scenes when you start inventory. This information is meant for reference purposes only.
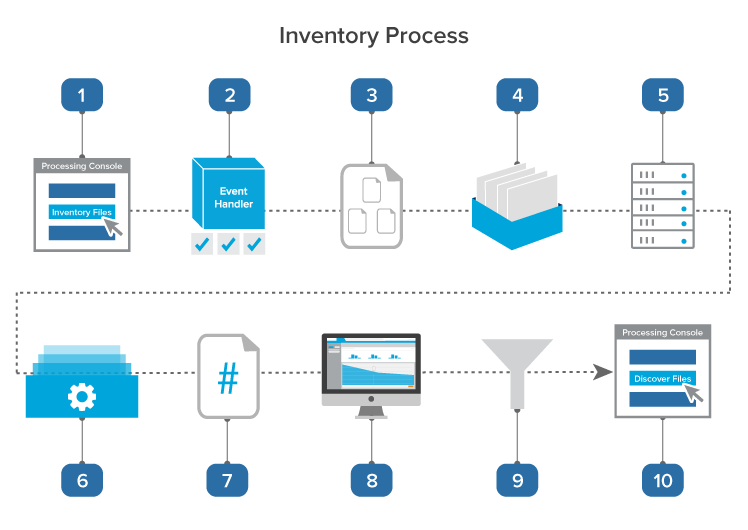
- You click Inventory Files on the processing console.
- A console event handler checks to make sure the processing set is valid and ready to proceed.
- The event handler inserts the data sources to the processing queue.
- The data sources wait in the queue to be picked up by an agent, during which time you can change their priority.
- The processing set manager agent picks up each data source based on its order, all password bank entries in the workspace are synced, and the agent inserts each data source as an individual job into the processing engine. The agent provides updates on the status of each job to Relativity, which then displays this information on the processing set layout.
- The processing engine inventories each data source by identifying top-level files and their metadata and merges the results of all inventory jobs. Relativity updates the reports to include all applicable inventory data. You can generate these reports to see how much inventory has narrowed down your data set.
- The processing engine sends a count of all inventoried files to Relativity.
- You load the processing set containing the inventoried files in the Inventory tab, which includes a list of available filters that you can apply to the files.
- You apply the desired filters to your inventoried files to further narrow down the data set.
- Once you’ve applied all desired filters, you move on to discovery.
Monitoring inventory status
You can monitor the progress of the inventory job through the information provided in the Processing Set Status display on the set layout.
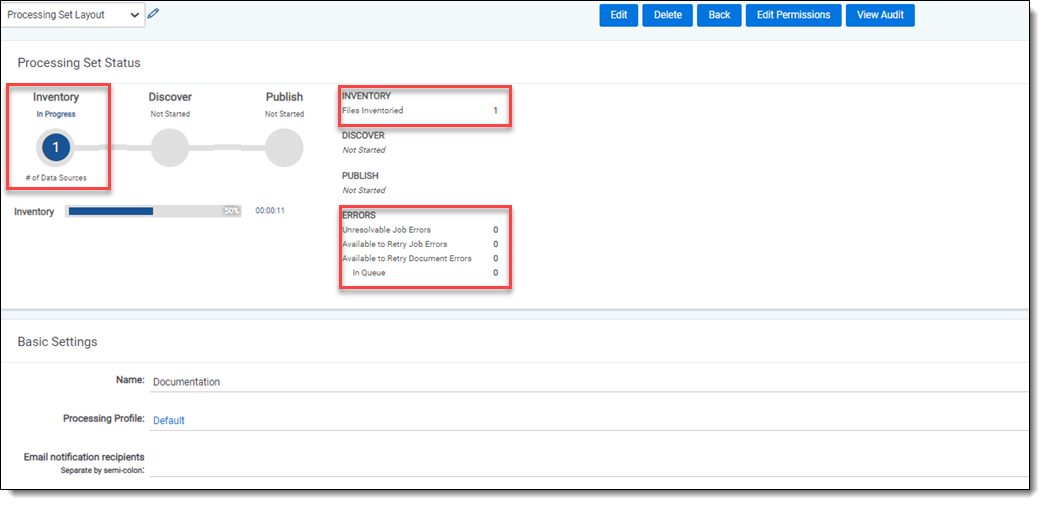
Through this display, you can monitor the following:
- # of Data Sources - the number of data sources currently in the processing queue.
- Inventory | Files Inventoried - the number of files across all data sources submitted that the processing engine has inventoried.
- Errors - the number of errors that have occurred across all data sources submitted, which fall into the following categories:
- Unresolvable - errors that you can't retry.
- Available to Retry - errors that are available for retry.
- In Queue - errors that you have submitted for retry and are currently in the processing queue.
See Processing error workflow for details.
If you skip inventory, the status section displays a Skipped status throughout the life of the processing set.

Once inventory is complete, the status section displays a Complete status, indicating that you can move on to either filtering or discovering your files.

Canceling inventory
If the need arises, you can cancel inventory before the job encounters its first error or before it is complete.
To cancel discovery, click Cancel.
Consider the following regarding canceling inventory:
- If you click Cancel while the status is still Waiting, you can re-submit the inventory job.
- If you click Cancel after the job has already been sent to the processing engine, the entire processing set is canceled, meaning all options are disabled and it is unusable. Deduplication isn’t run against documents in canceled processing sets.
- Once the agent picks up the cancel inventory job, no more errors are created for the processing set.
- Errors that result from a job that is canceled are given a canceled status and can't be retried.
Filtering files
When inventory is complete you have the option of filtering your files in the Inventory tab before moving to discovery.
Note that Relativity only filters on the files that you've inventoried. Everything else that cascades down from the files that were discovered is not subject to the inventory filters that you set.
To do this, click Filter Files on the console.
When you click this, you're redirected to the Inventory tab, which loads your processing set.
When you click the Inventory tab for the first time from anywhere else in Relativity, no processing set is loaded by default, and you're presented with a list of sets that are eligible for filtering.
Click on a set and click Select to load the set on the Inventory layout.
A processing set is not eligible for use in the Inventory tab if:
- You canceled the set.
- You already discovered or published the set.
- You haven't yet run inventory on the set.
- A discovery, retry discovery, publish, republish, or retry publish job is in the queue for the set.
If no processing sets are eligible for use in the Inventory tab, you'll be directed to the Processing Sets tab to create a new set or check on the progress of an existing set.
The following considerations apply to all processing sets in Inventory:
- If you need to load a different processing set, click Change Set to display a list of other available sets.
- You can click the processing set name link in the top right to return to that set's layout.
Note: If you leave the Inventory tab after having loaded a processing set, that set and any filters applied to it are preserved for you when you return to the Inventory tab.
You can add filters to the inventoried data and see how those filters affect the data in your processing set. You can't add filters if inventory is not complete or if the processing set has already been discovered.
There are six different filters you can apply to a processing set. You can apply these filters in any order; however, you can only apply one filter of each type. This section describes how to apply file location, file size, file type, and sender domain filters.
To add a new filter, click Add Filter.
Note: Filters affect the data set only at the time at which you apply them. This means that if you apply a filter to exclude a certain file type from your data but someone from your organization adds more files to the set, including instances of the excluded type, then the recently added files aren't actually removed when you start discovery. In order to exclude the added file types, you must first re-inventory the files in the updated data set. You can then run discovery and expect to see all instances of that file type excluded.
Clicking Add Filter displays a list of the following available filters:
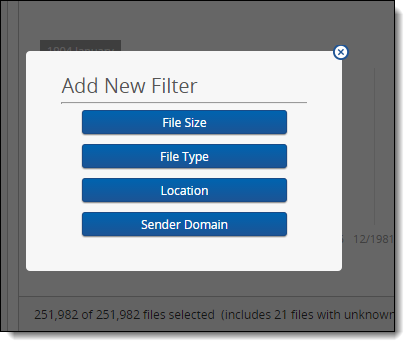
- File Size- exclude files that are smaller and/or larger than the size range you specify. This filter uses a range graph, in which you click and drag range selectors to exclude files.
- File Type - include or exclude certain files based on their type. For example, you may want to remove all .exe or .dll files since they typically have no relevance in the review process. This filter uses a two list display, in which you choose which files to exclude by moving them from the Included list to the Excluded.
Note: Renaming a file extension has little effect on how Relativity identifies the file type. When processing a file type, Relativity looks at the actual file properties, such as digital signature, regardless of the named extension. Relativity only uses the named extension as a tie-breaker if the actual file properties indicate multiple extensions.
- Location- include or exclude files based on their folder location. This filter uses a two list display, in which you choose which files to exclude by moving them from the Included list to the Excluded.
- Sender Domain- include or exclude email files sent from certain domains. For example, you may want to rid your data set of all obvious spam or commercial email before those files get into your workspace. This filter uses a two list display, in which you choose which files to exclude by moving them from the Included list to the Excluded.
The following considerations apply to all filter types:
- If the applied filter conditions have excluded all files from the set, then there are no results for you to interact with and you can't add or apply more filters.
- If a filter is already applied to the data, the corresponding button is disabled.
- The Inventory Progress graph displays the effect each filter has on your overall file count. The points on the graph indicate which filters you applied and the number of remaining files in your processing set.
- When you change the parameters of the filter, the number of documents automatically updates to reflect the change.
- Filters operate progressively, with each additional filter further narrowing down the total data set. For example, if you choose to include a certain file type and later filter out all file locations that contain those types of files, the discoverable data set does not ultimately include files of that type.
- To cancel a filter before you apply it, click Cancel. If you cancel, you lose all unsaved changes.
- You can't save and reuse filters from one inventory set to another.
Applying a Date range filter
When the selected processing set loads, no filters are applied to the files by default; however, a graph displays the date range for all files in the processing set.
Note: The deNIST filter is applied by default if your processing profile has deNIST field set to Yes.
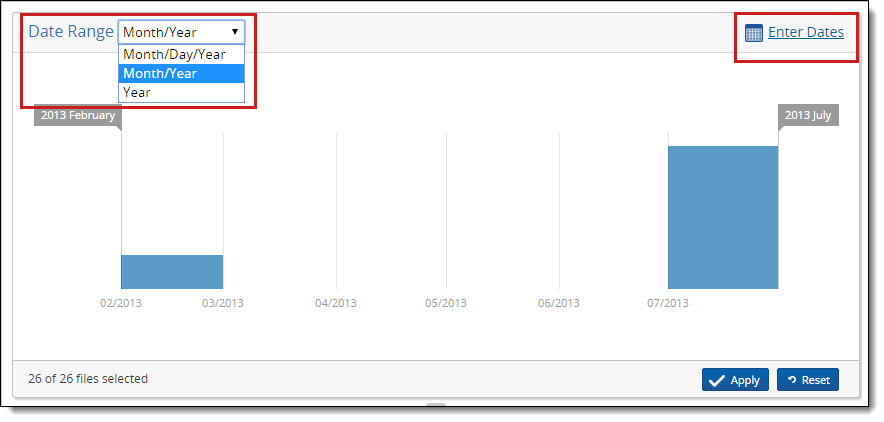
Note: When you filter for dates, you're filtering specifically on the Sort Date/Time field, which is taken from the file's Sent Date, Received Date, and Last Modified Date fields in that order of precedence. This happens on email messages repeated for the parent document and all child items to allow for date sorting.
You have the following options for applying a date range filter:
- Use the Date Range menu in the top left to select from Month/Day/Year, Month/Year, and Year. When you move the range selectors to a particular point on the graph, they will snap to the nearest whole number. Change the units of measurement to smaller denominations for more precise filter settings.
Note: When processing documents without an actual date, Relativity provides a null value for the following fields: Created Date, Created Date/Time, Created Time, Last Accessed Date, Last Accessed Date/Time, Last Accessed Time, Last Modified Date, Last Modified Date/Time, Last Modified Time, and Primary Date/Time. The null value is excluded and not represented in the filtered list.
- The Enter Dates link in the top right, when clicked, displays a window in which you can select a Start and End date from the two calendars. Click Apply after specifying the new dates.
- Drag the right and left limits of the graph until you have a visualization of the desired range. When you do this, the areas that you have designated to exclude are light blue. Click Apply after dragging these limits to their appropriate spots.
- To reset the parameters of a filter after you apply it, click Reset.
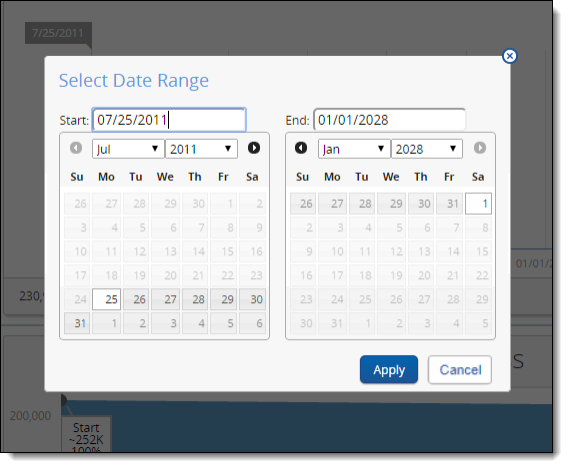
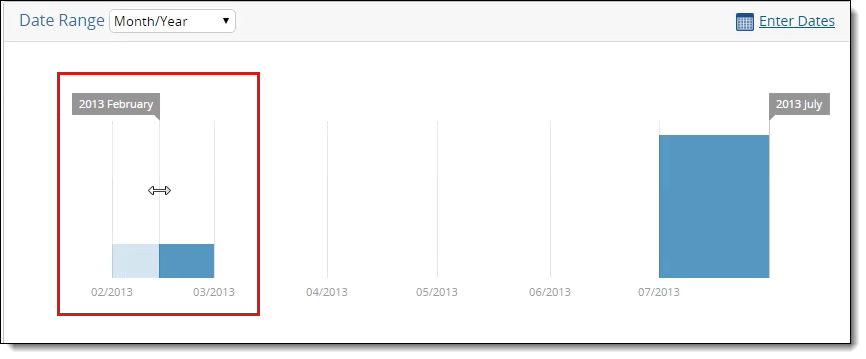
Note: If you run a re-inventory job on a processing set to which you've already added the date range filter, the date range display doesn't update automatically when you return to the Inventory tab from the processing set layout. You have to re-click the date range filter to update the range.
Applying a File Size filter
To filter your processing set files by size:
- Click Add Filter.
- Select File Size from the filter list.
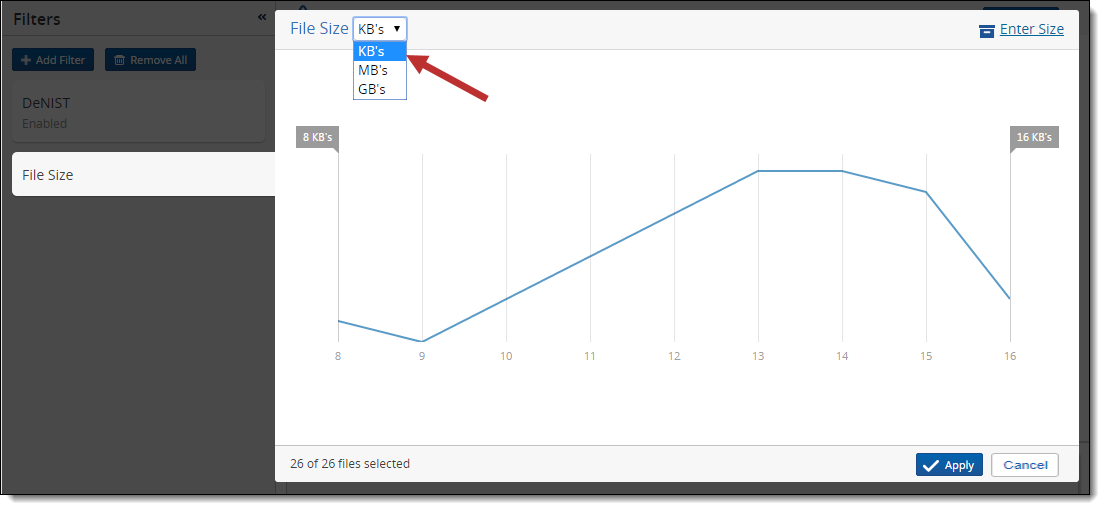
- Use the available options on the File Size range graph filter to specify how you want to apply the file size filter to your files.
- Use the File Size menu in the top left of the graph to select from KB's, MB's, and GB's. If all files in the current data set are from the same file size, for example 0 GB's, you can't get a visualization for that size. When you move the range selectors to a particular point on the graph, they will snap to the nearest unit of measurement selected. Change the units of measurement to smaller denominations for more precise filter settings.
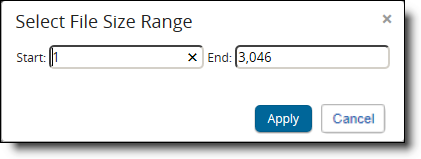
- Use the Enter Size link in top right of the graph to select Start and End values for the size range. By default, the lowest value in the data set appears in the Start field and the highest value appears in the End field.
- Click Apply once you've designated all the file sizes you want to exclude. The Inventory Progress pane reflects the addition of the file size filter, as well as the percentage and number of files that remain from the original data set.
Inventory reduces your processing set by the date parameters you defined. You can now apply additional filters to further reduce the data set, or you can discover the files.
Applying a deNIST filter
You can toggle the deNIST Filter on or off to exclude commonly known computer system files that are typically useless in e-discovery. You'll do this on the processing profile, and the selection you make there is reflected in the Inventory interface.
If the DeNIST field is set to No on the processing profile, the DeNIST filter doesn't appear by default in Inventory, and you don't have the option to add it. Likewise, if the DeNIST field is set to Yes on the profile, the corresponding filter is enabled in Inventory, and you can't disable it for that processing set.
Applying a Location filter
To filter your processing set files by location:
- Click Add Filter.
- Select Location from the filter list.
- Use the available options on the Location two-list filter to specify how you want to apply the location filter to your files.
- Click Apply once you've designated all the file locations you want to exclude. The Inventory Progress pane reflects the addition of the location filter, as well as the percentage and number of files that remain from the original data set.
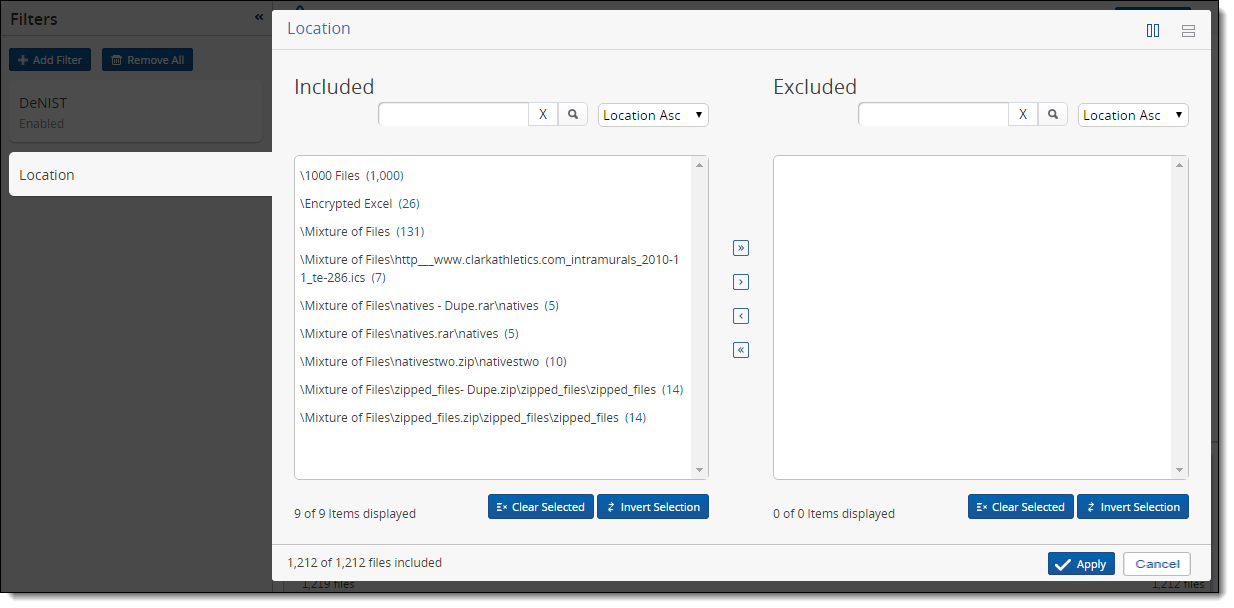
You can now apply an additional filter to further reduce the data set, or you can discover the files.
Applying a File Type filter
To filter your processing set files by type:
- Click Add Filter.
- Select File Type from the filter list.
- Use the available options on the File Type two-list filter to specify how you want to apply the file type filter to your files.
- Click Apply once you've designated all the file types you want to exclude. The Inventory Progress pane reflects the addition of the file type filter, as well as the percentage and number of files that remain from the original data set.
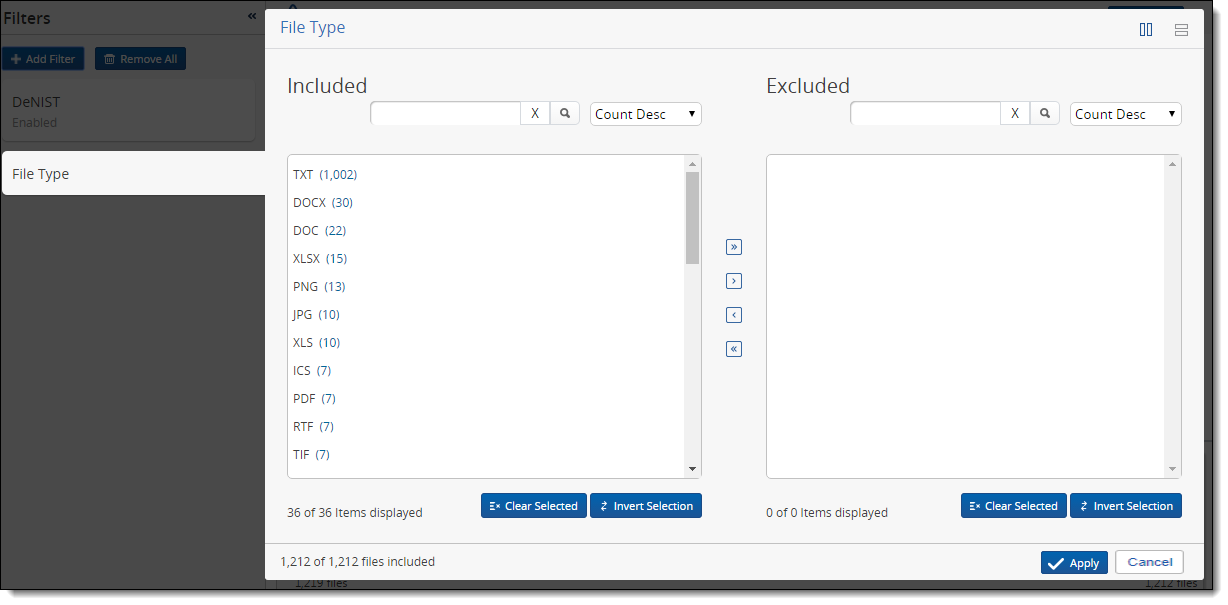
You can now apply an additional filter to further reduce the data set, or you can discover the files.
Applying a Sender Domain filter
To filter your processing set files by email sender domain:
- Click Add Filter.
- Select Sender Domain from the filter list.
- Use the available options on the Sender Domain two-list filter to specify how you want to apply the sender domain filter to your files.
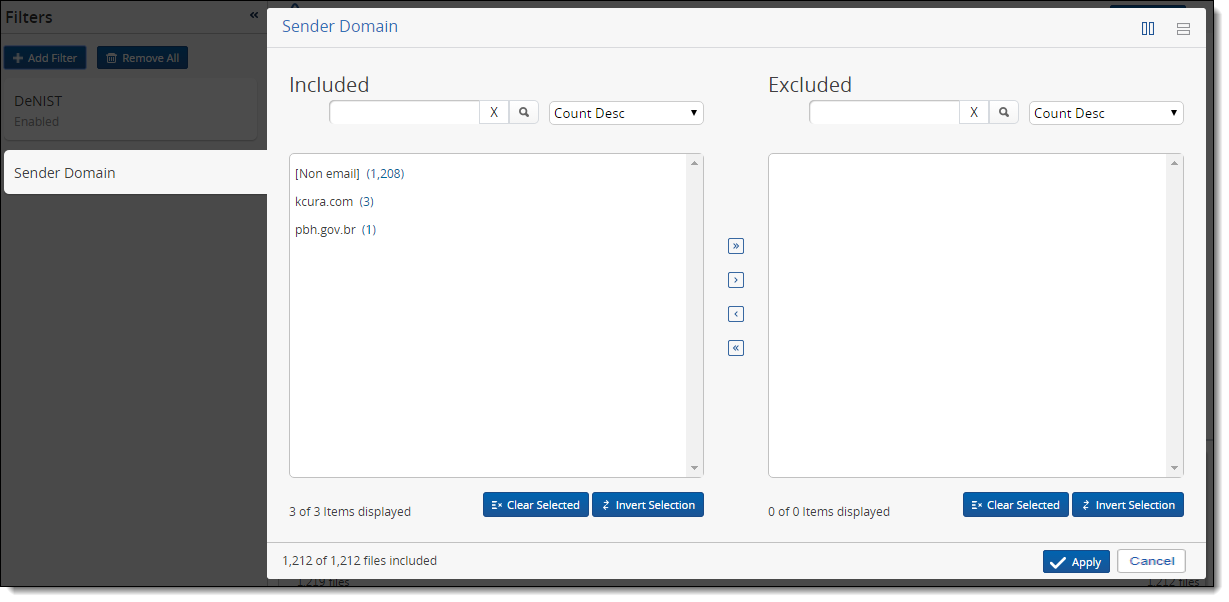
- Click Apply once you've designated all the email domains you want to exclude. The Inventory Progress pane reflects the addition of the sender domain filter, as well as the percentage and number of files that remain from the original data set.
You can now apply an additional filter to further reduce the data set, or you can discover the files.
Unspecified domains
Some of the domain entries in your filter window might not be displayed in a traditional domain format. For example, if there are files from an unspecified domain in your processing set, these files appear as a number in parentheses without a domain name next to it. Note the other instances in which Relativity returns unspecified domains and how it handles those items:
- [Non email] - the item was not handled by the Outlook handler.
- Blank - the Outlook handler processed the file, but couldn't find a sender domain.
- [Internal] - Relativity parsed an LDAP-formatted email address because there was no other valid domain available. When the system can't identify the domain, it attempts to extract the organization or company name from the address.
Applying a two-list filter
The two-list filter lets you filter processing set files by the following filter types:
- File Location
- File Type
- Sender Domain
When you add any of these filters, all instances of the variable being filtered for appear in the Included list to the left (or top). To exclude any instance, highlight it and click the single right arrow button to add it to the Excluded list on the right (or bottom).
Note: If you add items from the Included list to the Excluded or vice versa, and these additions affect the sort and search criteria of the modified list, you can refresh the list to re-apply the sort and search.
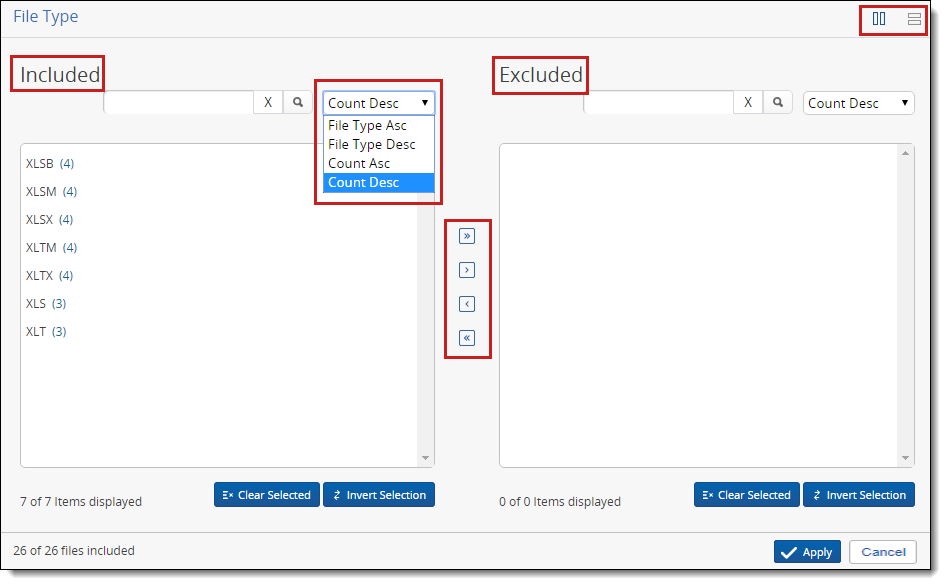
Note: Items removed from the data by edits to a previously applied filter are displayed in later filters with a value of (0) next to them. For example, if you apply the file type filter and then later narrow the date range to the extent that it filters out all files of the PDF type, then the next time you view the file type filter, PDFs are listed as having a count of (0).
You can use any of the following options in the two-list filter:
- Move over all items with double left and right arrows. Move over only the item(s) selected with the single left and right arrows.

- Toggle the two-list filter to display vertically or horizontally with the parallel line icons in the top right.

- The vertical lines display all files in the left column, and those designated for exclusion in the right column.
- The horizontal lines display all files in the top window, and those to be excluded in the bottom window.
- Double-click on any item to move it to the other list.
- Select multiple items in either list by clicking on the items, or select all items between two values in a list with the Shift key.
- Sort the Included and Excluded lists based on the following settings, depending on the filter type:

- Location Asc - sorts a list of file locations in alphabetical order.
- Location Desc - sorts a list of file locations in reverse alphabetical order.
- Sender Domain Asc - sorts a list of sender domains in alphabetical order.
- Sender Domain Desc - sorts a list of sender domains in reverse alphabetical order.
- File Type Asc - sorts a list of file types in alphabetical order.
- File Type Desc - sorts a list of file types in reverse alphabetical order.
- Count Asc - sorts a list of variables from the smallest count to the largest.
- Count Desc - sorts a list of variables from the largest count to the smallest.
- Clear Selected - marks the previously selected items in the Included or Excluded list as unselected.
- Invert Selection - marks the previously selected items in the Included or Excluded list as unselected while selecting the items that weren't selected before.
Removing filters
Clicking Remove All under Filter Controls removes all the filters from the menu on the left side of the menu.
You can also remove filters individually by clicking the X on a single filter in the menu. You can't delete a filter if you're currently working with it.
You will be redirected to the processing set page if any of the following occur:
- Inventory or re-inventory is in process for the set
- The set has been canceled
- Discovery has been run for the set
- A job is in the queue for the set
- The set is secured or no longer exists
Inventory progress
The graph in the Inventory Progress pane reflects all the filters you've applied to the processing set. This graph updates automatically as the inventory job progresses, and provides information on up to six different filters. The vertical axis contains the number of files. The horizontal axis contains the filters.
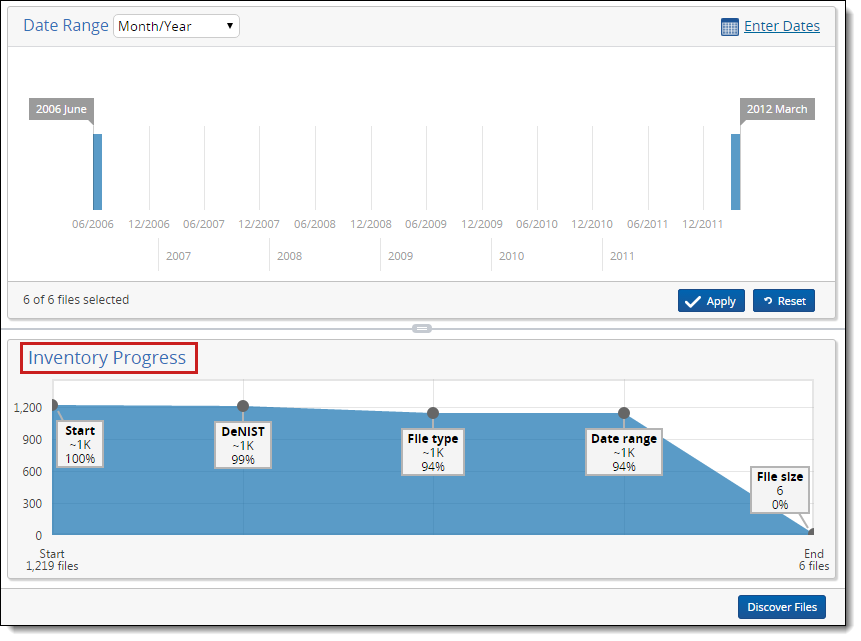
This graph provides the following information to help you gauge the progress of your filtering:
- Start # files - lists the number of files in the data set before you applied any filters to it. This value sits in the bottom left corner of the pane.
- End # files - lists the current number of files in the data set now that you've excluded documents by applying filters. This value sits in the bottom right corner of the pane.
- ~#K - lists the approximate number of files that remain in the data set under the filter type applied.
- #% - lists the percentage of files that remain from the data set under the filter type applied. If a filter excludes only a small number of files from the previous file count, this value may not change from the value of the preceding filter type.
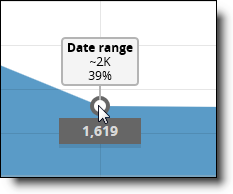
You can view the exact number of files that remain in the data set by hovering over the gray dot above or below the file type box.
At any time before you discover the files reflected in the Inventory Progress pane, you can reset or delete any filters you already applied.
Once you determine that the filters you've applied have reduced the data set appropriately, you can discover the remaining files.
Discovering files from Inventory
You can discover files from the Inventory tab using the Discover Files button in the bottom right corner of the layout.
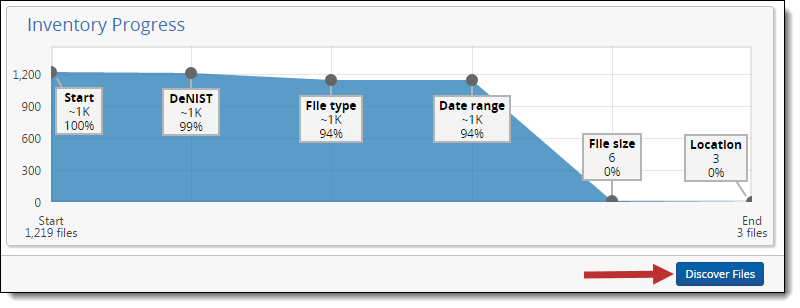
Clicking Discover Files puts the discovery job in the queue and directs you back to the processing set layout, where you can monitor the job's progress.
The same validations that apply when you start discovery from the processing set layout apply when discovering from the Inventory tab.
Inventory errors
If the processing set you select for inventory encountered any errors, the triangle icon appears in the upper left corner of the set. Hover over this icon to access a link to all applicable errors.

Clicking the link to view errors takes you to the Job Errors tab, which contains all errors for all processing sets in the workspace. By default, Relativity applies search conditions to this view to direct you to errors specific to your inventory data. Click any error message in the view to go to that error's details page, where you can view the stack trace and cause of the error.
All inventory errors are unresolvable. If you need to address an error that occurred during inventory, you must do so outside of Relativity and then re-run inventory on the processing set.
See Processing error workflow for details.
Inventory error scenarios
You receive an error when starting file inventory if any of the following scenarios occur:
- The processing license expires.
- You have an invalid processing license.
- The DeNIST table is empty and the DeNIST field on the profile is set to Yes.
- No processing webAPI path is specified in the Instance setting table.
- There is no worker manager server associated with the workspace in which you are performing file inventory.
- The queue manager service is disabled.
Re-inventory
You may be prompted to run inventory again in the status display on the processing set layout.
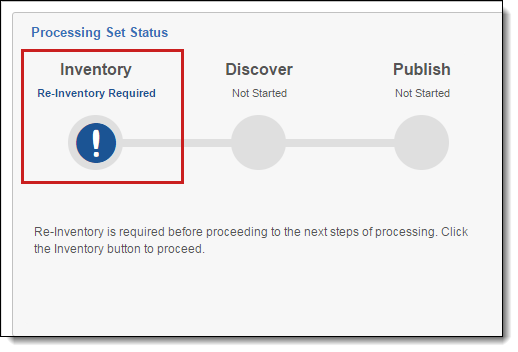
You must run inventory again on a processing set if:
- You've added a data source to processing set that has already been inventoried but not yet discovered.
- You've edited a data source that is associated with a processing set that already been inventoried but not yet discovered.
- You've deleted a data source from a processing set that has already been inventoried but not yet discovered.
You can also voluntarily re-inventory a processing set any time after the Inventory Files option is enabled after the previous inventory job is complete.
To re-inventory at any time, click Inventory Files.
When you click Inventory again, you're presented with a confirmation message containing information about the inventory job you're about to submit. Click Re-Inventory to proceed with inventory or Cancel to return to the processing set layout.
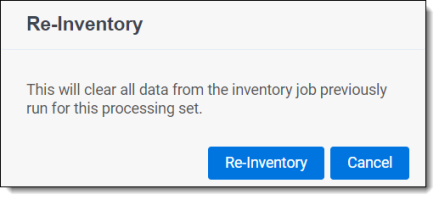
When you re-inventory files:
- Filters that you previously applied in the Inventory tab do not get cleared.
- Errors that you encountered in a previous Inventory job are cleared.