Before you can run any full text search filters on the imported documents, you must first build an index from your import job’s extracted text. You can then use operators and other features provided by a dtSearch index to construct full text search filters.
The RPC breaks indexing jobs into 1000 document chunks, which are then run in parallel using multiple workers and threads to improve performance. The RPC merges the dtSearch indexes after these jobs complete.
During indexing, errors may occur from documents that don’t have any extractable text. The RPC continues building the index when an error occurs, but those documents without extractable text aren’t represented in the index. Using SQL Reporting Services, the RPC generates an error report that lists the documents and error details. For example, a document without extracted text or intermediate file is listed in this report.
Note: You can index data at any point after text extraction or image generation. If you choose to skip text extraction and proceed directly to image generation the indexing process will combine the page level text into a doc level text file that will be used in the index.
Running an indexing job
Before running an indexing job, you must first run text extraction or generate images on the job. See Extracting text or Generating images.
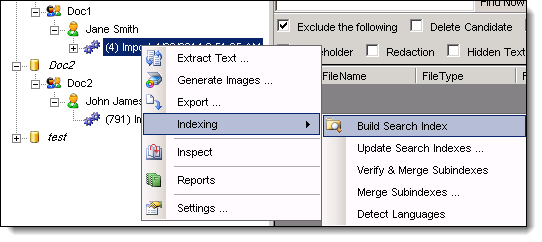
- From the Data Stores window, drill down to the import job that you used for the extract text job.
- Right-click the import job > Indexing > Build Search Index.
-
- After the job processes, right-click the indexing job in the Data Store window > Discovery > Error Report.
- Review the report to determine if the index needs to be rebuilt.
Note: You can also use the Matter Inspector tab to investigate an indexing error. To do this, obtain the storage ID from the error report. In the Data Store window, highlight the job, and select Inspect to open the Matter Inspector. Use the storage ID to locate the document. Determine if the document is an image, needs OCR, is password-protected, or has another issue.
Language detection
The RPC supports language detection by adding metadata to each document in an import job. Using the metadata, the RPC creates a language map of the document. It then maps out a range in the document for each language that it contains, and provides a score that identifies the dominant language.
Before you can perform language detections, you must first index the import job.
- In the Data Stores window, drill down to an import job.
- Right-click on the import job. Point to Indexing, and click Detect Languages.
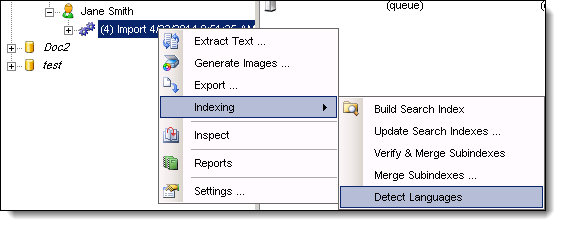
- Select the View menu, and click Properties window.
- Right-click on the import job, and click Inspect to open the Matter Inspector.
- To view the language map, highlight the document in the Matter Inspector, and click Properties.
- In the Properties window, expand Storage Metadata, and then expand Language Map to display a list of language ranges.
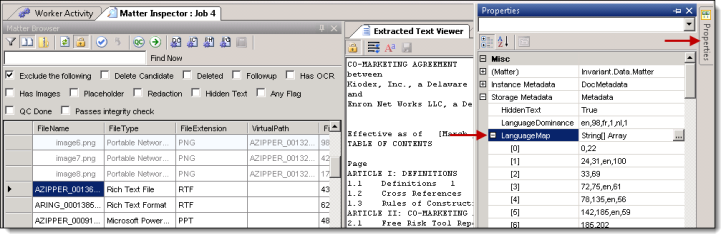
- The range for the language lists the starting character position, the character length, the language, and the percentage of the text in that language. For entry [3], the starting character position is 89, character length is 93, the language is zh (that is Chinese), and the text is 100% Chinese: [3] 89,93,zh,100. When the Language Dominance is below 50, this value usually indicates unreliable detection.
Note: For a complete list the two-digit codes that accompany each full language name, visit the ISO standards site.
Merging subindexes
The RPC performs parallel indexing by distributing jobs across multiple machines, which create subindexes. It then attempts to merge all the subindexes after the indexing completes. When a very large import job indexes, this process can over run dtSearch capabilities, which has a limit of about 4 billion words.
Errors can occur when the RPC automatically attempts to merge multiple subindexes into a single index. In this case, you can manually attempt to merge a few subindexes at a time, gradually building a large index.
Note: The RPC can search across multiple indexes. It automatically detects them and spans the search across them, but this process is slower than using a single index.
- In the Data Stores window, drill down to an import job.
Note: The option Verify and Merge Subindexes verifies that all expected documents are indexed, and then attempts to merge the subindexes.
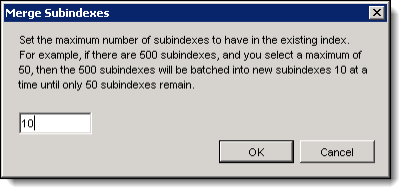
- Right-click on the import job. Point to Indexing, and click Merge Subindexes
.
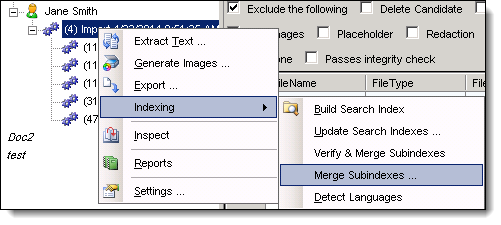
- Enter a value and click OK.