






To run a structured analytics set within your workspace, you must first use the Structured Analytics Set console to create a new set and select which operations will be included. After the set has been completed and run, you’ll be able to view summary reports for each of the operation types you chose.
Setting up permissions for structured analytics
Before you begin working with structured analytics sets, make sure that your user group has the following permissions:
| Object Security | Tab Visibility | Other Settings |
|---|---|---|
|
|
|
For more information about setting permissions, see Workspace security.
Creating a structured analytics set
To create a new structured analytics set:
- From the Indexing & Analytics tab, select Structured Analytics Set.
- Click New Structured Analytics Set.
- Complete or edit the Structured Analytics Set Information fields on the layout. See Structured Analytics Fields.
- For each selected operation, fill in the additional required fields and adjust the settings as necessary.
- Click Save.
The console appears, and you can now run your structured analytics set. See Structured Analytics Set console.
Note: When creating a new structured analytics set in a large workspace, the document table may become locked while the results fields are being created. We recommend creating new sets off-hours to prevent any disruption to review.
Structured Analytics Fields
The Structured Analytics Set layout contains the following fields:
Structured Analytics Set Information
- Structured analytics set name - name of structured analytics set.
- Set prefix - enter the prefix that will be attached to all structured analytics fields and objects for the set you are running (e.g., Set01).
You can enter whatever you like (up to 10 characters) as long as you don't use the same name as an existing set. The default prefix is SAS01 and automatically iterates the number to prevent the overwriting of an existing set. - Select document set to analyze - saved search containing documents to analyze. All documents with more than 30 MB of extracted text are automatically excluded from the set (there is a small buffer of 200 bytes +/- exactly 30 MB).
- Select operations - available structured analytics operations. See Structured analytics operations.
Note: You can change the structured analytics set operations after you’ve run a set. Once you successfully run an operation and want to run another, return to your set and deselect the operation you previously ran and select the new operation. Then, save and run your structured analytics set.
- Enter email addresses - semicolon delimited list of email addresses to which structured analytics job status notification emails are sent.
For best results, avoid nested saved search conditions and exclude relational fields. Use a field tag where possible, and do not apply a sort order. The fields returned in the search do not matter.
Note: You can access documents that are automatically removed from the set in the Field Tree. Each completed Structured Analytics set contains an ‘Included’ and ‘Excluded’ tag within the Field Tree. You can find documents excluded from the set under the ‘Excluded’ tag for that set. For more information, see Running structured data analytics.
Advanced Settings
- Analytics server - drop-down menu from which you select a specific Analytics server. The drop-down menu lists all Analytics resource servers in the workspace's resource pool flagged with the Structured Data Analytics operation type. You can only change the server if there isn't any data from running jobs for the current structured analytics set on the selected server.
- Regular expression filter - repeated content filter used to clean up extracted text before analysis. If your email threading results appear to have errors, applying a regular expression filter to remove text such as dates or URLs can improve results. See Creating a repeated content filter for steps to create a regular expression type filter.
This field supports linking one repeated content filter. The filter type must be Regular Expression.
The filter only applies to the field being analyzed.
We recommend not using this field when running operations for the first time.
See the following considerations for each operation.
Email threading fields
To run the email threading operation, you must select values for the following fields:
Structured Analytics Set Information
- Select document set to analyze - saved search containing documents to analyze. For an email threading structured analytics set, this should include the parent emails and their attachments. All documents with more than 30 MB of extracted text are automatically excluded from the set.
Note: You can access documents that are automatically removed from the set in the Field Tree. Each completed Structured Analytics set contains an ‘Included’ and ‘Excluded’ tag within the Field Tree. You can find documents excluded from the set under the ‘Excluded’ tag for that set. For more information, see Running structured data analytics.
Note: Refer to the Analytics Email Threading - Handling Excluded Large Attachments knowledgebase article for more information on handling any excluded large attachments.
Email Headers
- Select profile for field mappings - select an Analytics profile with mapped email threading fields. See Email threading.
- Use email header fields - select Yes to include the email metadata fields when structured analytics sends data to Analytics. Email metadata fields include the following:
- Email from
- Email to
- Email cc
- Email bcc
- Email subject
- Email date sent
If you select Yes, you must ensure all email fields are properly mapped on the Analytics profile.
Select No if your document set doesn't include email metadata. When set to No, email threading relies on extracted text, and the Parent Document ID and Attachment Name fields.
- Notes:
- Email threading requires the Email From field value and at least one other email field value to be set, either in the extracted text or the metadata mapped to the Analytics profile.
- In order to properly thread and visualize attachments, you must map the Parent Document ID and Attachment Name fields in the selected Analytics profile.
- Email header languages - select the languages of the email headers you want to analyze in your document set. English is selected by default, and we recommend you do not remove this selection. The following languages are supported:
- English (default)
- Chinese
- Dutch
- French
- German
- Japanese
- Korean
- Portuguese
- Spanish
Note: Selecting extra languages may impact performance. Only select if you know you have non-English headers to analyze.
- Destination Email Thread Group - select the fixed length text field that maps to the Email Thread Group. This can be left as the previously selected field when creating an additional email threading set if you want to overwrite the existing relational field for the new email threading set or mapped to a new field to prevent overwriting of the previously selected field. However, if you do keep the same field when running an additional structured analytics set, the fielded data (including on any related relational views) are overwritten with the new results.
- Destination Email Duplicate ID - select the fixed length text field that maps to the Email Duplicate ID. This can be left as the previously selected field when creating an additional email threading set if you want to overwrite the previously mapped Email Duplicate ID field for the new email threading set or you can map this to a new field to prevent overwriting of the previously selected field. However, if you do keep the same field when running an additional structured analytics set, the fielded data (including on any related relational views) are overwritten with the new results.
Note: We recommend creating a new relational fixed length text field for every set to take advantage of grouping functionality for documents in an list view. Beginning
Note: We recommend creating a new relational fixed length text field for every set to take advantage of grouping functionality for documents in an list view. The length of this field must be greater than or equal to 10. Beginning
If your email threading results appear to have errors, applying a regular expression filter to remove text such as dates or URLs can improve results. See Creating a repeated content filter for steps to create a regular expression type filter.
Name normalization fields
To run the name normalization operation, you must select values for the following fields:
Structured Analytics Set Information
- Select document set to analyze saved search containing documents to analyze. Name normalization only analyzes emails. For the most complete results, we recommend running across all emails in your data set. All documents with more than 30 MB of extracted text are automatically excluded from the set.
Note: You can access documents that are automatically removed from the set in the Field Tree. Each completed Structured Analytics set contains an ‘Included’ and ‘Excluded’ tag within the Field Tree. You can find documents excluded from the set under the ‘Excluded’ tag for that set. For more information, see Running structured data analytics.
Email Headers
- Select profile for field mappings - select an Analytics profile with mapped email header and email metadata fields.
Note: Attachments are not included in name normalization. Aliases on an email that is an attachment are not parsed and added to the Alias table.
- Use email header fields - select Yes to include the email metadata fields when structured analytics sends data to Analytics. Email metadata fields include the following:
- Email from
- Email to
- Email cc
- Email bcc
- Email subject
- Email date sent
Select No if your document set doesn't include email metadata. When set to No, name normalization relies on extracted text, the Parent Document ID field, and the Attachment Name field.
- Email header languages - select the languages of the email headers you want to analyze in your document set. English is selected by default, and we recommend you do not remove this selection. The following languages are supported:
- English (default)
- Chinese
- Dutch
- French
- German
- Japanese
- Korean
- Portuguese
- Spanish
Note: Selecting extra languages may impact performance. Only select if you know you have non-English headers to analyze.
Textual near duplicate identification fields
To run the textual near duplicate identification operation, you must select values for the following fields:
- Minimum similarity percentage - enter a percentage value between 80 and 100 percent, or leave the default 90 percent.
- Ignore numbers - select Yes to ignore numeric values when running a Textual near duplicate identification operation. Select No to include numeric values when running the operation. For a string to be considered a "number," either the first character is a digit, or the first character is not a letter and the second character is a digit.
Note: Setting the value of this field to "No" causes the structured analytics set to take much longer to run and the "Numbers Only" Textual Near Duplicate Group will not be created since these documents will be considered.
See the following table for examples:
Example Ignored when Ignore numbers is set to Yes? 123 Yes 123Number Yes number123 No n123 No .123 Yes $12 Yes #12 Yes $%123 No
The Minimum similarity percentage defines which documents are identified as near duplicates based on the percentage of similarity between the documents.
- Destination Textual Near Duplicate Group - select the Fixed Length Text field that maps to the Textual Near Duplicate Group field (e.g., Textual Near Duplicate Group). This can be left as the previously selected field when creating an additional Textual Near Duplicate set if you want to overwrite the existing relational field values for the structured analytics set or it can be mapped to a new field to prevent overwriting of the previously selected field. However, if you do keep the same field when running an additional structured analytics set, the fielded data (including on any related relational views) are overwritten with the new results
Note: We recommend creating a new relational Fixed Length Text field for every set to take advantage of grouping functionality for documents in an list view. Beginning
Language identification fields
Note: No additional settings are needed to run the language identification operation.
Repeated content identification fields
The repeated content operation includes settings that allow you to adjust the granularity of analysis.
You must select values for the following fields:
Note: Each setting has an upper bound value. You can't save a structured analytics set with a value that exceeds a setting's upper bound value. This prevents you from using settings that may crash the server.
- Minimum number of occurrences - the minimum number of times that a phrase must appear to be considered repeated content. We recommend setting this to 0.4 percent of the total number of documents in the Document Set to Analyze saved search. For example, with 100,000 documents, set the Minimum number of occurrences to 400 (equal to 0.004 x 100,000). Setting this value higher returns fewer filters; setting it lower returns more. Set this value lower if your desire for a cleaner index justifies the work of reviewing additional filters. This value cannot exceed 1 million.
- Minimum number of words - the minimum number of words that a phrase must have in order to be brought back as a potential filter. We recommend setting this value to 6 or higher. This value cannot exceed 1,000.
- Maximum number of words - the maximum number of words that a phrase can have in order to be brought back as a potential filter. We recommend setting this value to 100. Increasing this value increases the time for the operation to complete
We recommend using the default values for these settings the first time you run the repeated content operation on a set of documents. If necessary, you can adjust these settings based on your initial results. For example, you may increase the minimum number of occurrences if you receive too many results or increase the maximum number of words if you’re only identifying partial repeated phrases.
If you’re still not satisfied with the results, advanced users may want to adjust these settings:
- Maximum number of lines to return - the maximum number of lines to include in one repeated content segment. We recommend setting this value to 4. This value cannot exceed 200. Poorly OCR-ed documents may include additional line breaks, so increasing this value may yield more accurate results.
- Number of tail lines to analyze - the number of non-blank lines to scan for repeated content, starting from the bottom of the document. We recommend setting this value to 16. Increasing this value increases the time for the operation to complete
Structured Analytics Set console
Build or update a structured analytics set with the available run commands on the Structured Analytics Set console. After saving a new structured analytics set, the console automatically loads. To access the console for an existing structured analytics set, click the set name listed on the Structured Analytics Set tab.
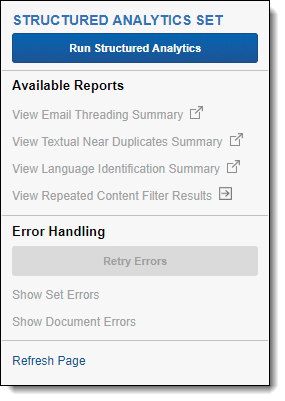
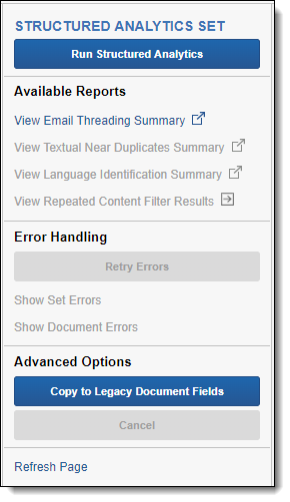
The Structured Analytics Set console contains the following options:
Run Structured Analytics
Note: When email threading and textual near duplication identification operations are run at the same time, email threading will process only email documents and their attachments while textual near duplicate identification will only process standalone documents and attachments (not emails).
Once you click Run Structured Analytics, a modal opens with the following options:
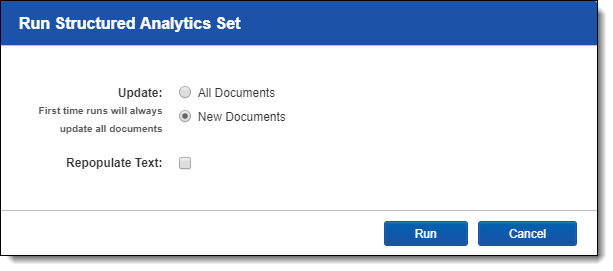
- Update - choose whether to update results for All Documents or only New Documents. When you run an operation for the first time, it will always update results for all documents for that operation, regardless of the settings used. Selecting New Documents is equivalent to previously performing an incremental analysis.
- Repopulate Text - select whether to reingest all text through the analytics engine. If you select this option, the Update field automatically selects All Documents. This option is equivalent to previously performing a full analysis.
If you choose to repopulate text, it loads and sends all documents in the defined set to the Analytics engine for analysis. Then, the selected operations run from start to finish and import results back to Relativity.Note: Select this option if document text in your data set has changed and needs to be updated within the Analytics engine; regular expression filters need to be applied, removed or updated; or if any fields on the Analytics profile have changed.
Note: To run a full analysis on your set without having to resubmit all of your documents to the Analytics engine, select All Documents but leave the Repopulate Text checkbox cleared.
Click Run to start the build operation.
Note: If a previously run operation remains selected on subsequent runs, that operation is skipped if no new documents have been added to the saved search and no changes were made to that operation's settings. To force a re-run of an operation in a scenario like this, select the Repopulate Text checkbox.
Once the build is running, click Cancel Analysis to cancel the operation. This stops the analysis process and prevents the structured analytics set from running. This action puts the structured analytics set in a state that allows for you to re-run the analysis.
Note: You can't take actions on a structured analytics set while agents are in the process of canceling a job for that set. You must wait for the cancel action to complete.
Update: New Documents behavior
The following descriptions explain the expected behavior for each structured analytics operation when you select Update: New Documents:
- Email threading - if the newly added documents match with existing groups, the documents are incorporated into existing Email Thread Groups from running Update: New Documents.
- Running Update: New Documents updates pre-existing results for the following fields: Email Duplicate ID, Email Duplicate Spare, Email Threading ID, Email Thread Group, and Indentation.
- This process may also update emails previously marked as Non-inclusive to Inclusive. However, it will never change an email from Inclusive to Non-inclusive.
- Name normalization - sends newly added documents and analyzes for new aliases. Aliases that exist in Relativity are never deleted, renamed, or adjusted in any way on subsequent runs.
- Textual near duplicate identification - if the newly added documents match with existing textual near duplicate groups, the new documents are incorporated into existing textual near duplicate groups from the full analysis. However, there are some additional considerations for running an incremental analysis. Consider the following scenarios:
Scenario 1: Newly added document matches with pre-existing textual near duplicate group, and the newly added document is larger than or equal to all of the documents currently in the textual near duplicate group.
Result: The pre-existing Principal will never change. The newly added document will not be added to a pre-existing group. It will become a singleton/orphan document.
Scenario 2: Newly added document matches with pre-existing document that was not in a textual near duplicate group. The pre-existing document is larger than the new document.
Result: The pre-existing document is marked Principal. It is updated to have a textual near duplicate group, along with the newly added document.
Scenario 3: Newly added document matches with pre-existing document that was not in a textual near duplicate group. The new document is larger than the pre-existing document.
Result: The newly added document is marked Principal. It is updated to have a textual near duplicate group. The pre-existing document is not updated at all and is essentially orphaned.
Note: This is a current limitation in the software and is not an ideal situation. If this occurs, you will see a newly added document as a Principal in a group all by itself. You can check for this scenario by running a Mass Tally on the Textual Near Duplicate Group field. A group of one document should not normally exist – if it does, then this situation has occurred.
- Language identification - sends over newly added documents and analyzes all documents in the set for their languages.
- Repeated content identification - sends newly added documents and compares all documents like what occurs during a full analysis, which could result in duplicate repeated content filters being created. This is because repeated content identification analyzes across a collection of documents rather than document by document.
Available Reports
The following links to reports are available:
- Email Threading Summary - opens a report you can quickly assess the results and validity of the email threading operation. See Viewing the Email Threading Summary.
- View Textual Near Duplicates Summary - opens a report you can quickly assess the results of the textual near duplicates operation. See Viewing the Textual Near Duplicates Summary.
- View Language Identification Summary - opens a report you can quickly assess the results of the language identification operation. See Viewing the Language Identification Summary.
- View Repeated Content Filter Results - opens the Repeated Content Filters tab with a search condition applied to only view filters related to the structured analytics set. The search condition uses the Structured Analytics Set Name field with the value set to the name of the source structured analytics set. All repeated content filters created by the repeated content identification operation automatically have the Structured Analytics Set Name field set to the name of the source structured analytics set.
Note: Click the Toggle Conditions On/Off ![]() button followed by the Clear button to remove the search condition from the Repeated Content Filters tab.
button followed by the Clear button to remove the search condition from the Repeated Content Filters tab.
Errors
The Errors section contains the following options:
- Retry Errors - retries all of the errors encountered while running the current structured analytics set.
- Show Set Errors - displays a list of all errors encountered while running the current structured analytics set. To view the details of an individual error, click the error name. To return to the structured analytics set information, click Hide Set Errors.
- Show Document Errors - opens a Document Errors window listing errors per document that were encountered while running the structured analytics set including documents that were removed because they were over 30 MB.
Common document errors
The following section lists common errors and how to interpret them. Click the drop down to display the following information about each error:
- Operations - the structured analytics operations which can generate the error message.
- Document Status - indicates whether the document is included or excluded from the current import process as well as future runs.
- Removed from Set - a document-level error is reported and the document is excluded from the current run as well as any future runs. No results are imported.
- Data Warning - a document-level error is reported, but the document remains included in the Structured Analytics Set for future runs. All results are imported.
- Description - a description of what the error means.
- Next steps - next steps to resolve the error.
| Operations | Document status | Description | Next steps |
|---|---|---|---|
|
Data warning | The operation encountered errors during text extraction due to special characters, such as emojis, that the Analytics engine can't process. You can find more information in this article on the Community site. | Review the document for any special characters contained in the extracted text and review any results from the selected operation(s). |
| Operations | Document status | Description | Next steps |
|---|---|---|---|
|
Removed from set | Errors were encountered during text extraction due to no text, encrypted text or corrupted text | Review the extracted text of the document to verify it contains text and that the text is not corrupted or encrypted. |
| Operations | Document status | Description | Next steps |
|---|---|---|---|
|
Data warning | The metadata for the item exceeded 500 characters. | None for email threading and name normalization. You can still run this document through other structured analytics operations, like language identification and textual near duplicate identification. |
| Operations | Document status | Description | Next steps |
|---|---|---|---|
|
Data warning | Invalid Unicode characters were included in the metadata for the document. | None for email threading and name normalization. You can still run this document through other structured analytics operations, like language identification and textual near duplicate identification. |
| Operations | Document status | Description | Next steps |
|---|---|---|---|
|
Data warning | Invalid Unicode characters were found in the text of the document and replaced. | Review the document for any special characters contained in the extracted text and review any results from the selected operation(s). |
| Operations | Document status | Description | Next steps |
|---|---|---|---|
|
Data warning | Too many email segments preventing the Analytics engine from processing the item. The maximum number of segments an email can contain is 2000. | None for email threading and name normalization. You can still run this document through other structured analytics operations, like language identification and textual near duplicate identification. |
| Operations | Document status | Description | Next steps |
|---|---|---|---|
|
Data warning | The email parsing process takes too long resulting in a timeout. | For next steps, refer to the this article on the Community site. |
| Operations | Document status | Description | Next steps |
|---|---|---|---|
|
Removed from set | The document text for the requested document(s) could not be accessed or found in the DataGrid file share. | Review the extracted text to verify that it exists and is accessible by Relativity. |
| Operations | Document status | Description | Next steps |
|---|---|---|---|
|
Data warning | The number of characters in the recipient fields - To, CC, BCC - for a segment exceeds the maximum of 50,000. | Review the extracted text to identify the problematic segment and reach out to support to temporarily increase the character limit. |
Administration
Refresh page - updates the page to display its current status.
Delete button -
If an error occurs during a delete, it creates an error in the Errors tab. When an error occurs, you must manually clean up the Analytics server and the population tables on your server.
Note: When you delete a structured analytics set, the field values for Language Identification (Docs_Languages:Language, Docs_Languages, Docs_Languages::Percentage), and the Repeated Content Filter objects and fields (Name, Type, Configuration, Number of Occurrences, Word Count, Ready to Index), remain populated. There is no need to clear the fields as future runs will overwrite their values. However, if there is a need to clear them this must be done manually.
Status values
Structured analytics sets may have the following statuses before, during, and after running operations:
| Structured analytics set status | Appears when |
|---|---|
| Please run full analysis | The structured analytics set has been created, but no operations have run with it. |
| Setting up analysis | The structured analytics job is initializing. |
| Syncing document set | Update All Documents or Repopulate Text option has been selected. |
| Calculating file sizes | File sizes are being calculated for all documents in the saved search. |
| Exporting documents | Documents are being exported from Relativity to Analytics engine for analysis. |
| Completed exporting documents | Documents have been exported from Relativity to Analytics engine for analysis. |
| Running structured analytics operations | Analytics engine has started running the structured analytics operations. |
| Importing results into Relativity | Structured analytics results are being imported into Relativity from Analytics engine. |
| Importing entities and aliases into Relativity | Name Normalization results are being imported into Relativity from Analytics engine. |
| Completed structured analytics operations | Structured analytics results have been imported into Relativity from Analytics engine. |
| Error while running analysis | Structured analytics job failed with errors reported. |
| Attempting to retry errors | An error retry is in progress. |
| Canceling analysis | The Cancel Analysis button was just clicked. |
| Canceled analysis | The cancel action has completed. |
| Copying results to legacy document fields | Copy to Legacy Document Fields script is running. |
Identifying documents in your structured analytics set
When you first run your structured analytics set, the Structured Analytics Sets multiple choice field is created on the Document object and populated for the documents in the set with the name of the structured analytics set and whether the document was included or excluded from the named set. This field is populated every time the set is run (full or incremental). You can use this field as a condition in a saved search to return only documents included in the set. You can also view the documents which were excluded from the set (these could be empty documents, number only documents, or documents greater than 30 MB).
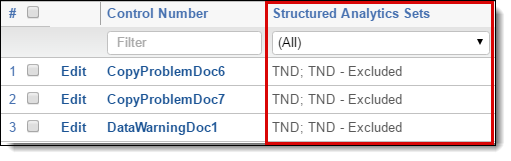
The Structured Analytics Set field also displays in the Field Tree browser to make it easy to view the documents that were included and excluded from the set. You can also view documents that are not included in a structured analytics set by clicking [Not Set].
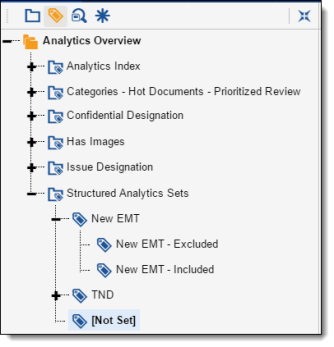
Analyzing your results
After running an analysis, you can review the results for each selected operation. For guidelines on assessing the validity of the results and making sense of the analysis, see the following
- Email threading results
- Name normalization results
- Textual near duplicate identification results
- Language identification results
- Evaluating repeated content identification results
Copy to Legacy Document Fields
Upon upgrade to Relativity 9.5.196.102 and above, email threading and textual near duplicate results are written to new results fields that are only created upon saving a Structured Analytics Set. The Copy to Legacy Document Fields button gives you the option of copying the contents of the newly created fields back to the existing document fields. This ensures that anything referencing the legacy fielded data, such as views and saved searches, continues to work with the new results.
Special considerations
Please note the following :
- This script updates the Document table and may impact performance. Only run during off-hours.
- The results of running this solution are permanent and cannot be undone.
- You can't run the selected structured analytics set until the script is finished running.
Running the Copy to Legacy Document Fields script
The Copy to Legacy Document Fields button is only available on the Structured Analytics Set console if the following conditions are met:
- The workspace contains all legacy structured Analytics fields.
- The Structured Analytics Set includes either the email threading or textual near duplicate identification operations.
Note: It's possible that this button may show up on multiple Structured Analytics sets. However, if you run the operation on multiple sets, you'll overwrite the field information.
To run, simply click the Copy to Legacy Document Fields button. The progress is displayed in the status section. You can cancel the operation while it is running, but you can't roll back the results and the job will be incomplete.
Upon completion, the audit tells you the total number of fields updated. If the operation fails, you are able to retry the operation.
Special considerations for structured analytics
- You can carry over a structured analytics set and any related views or dashboards in a template.
- You can only run structured analytics on the Extracted Text field. If your text is another field, such as OCR, perform a mass replace into the Extracted Text field in order to run structured analytics.
- Email threading requires the Email From field value and at least one other email field value to be set, either in the extracted text or the metadata mapped to the Analytics profile.
- A structured analytics set may have any combination of operations selected. We recommend running Email threading and Near Duplicate Identification in the same set. Note the following:
- We generally recommend that you run name normalization in its own structured analytics set for maximum flexibility. While it is faster to run multiple structured analytics operations together in one set, you may find that you’re ultimately constrained if you want to make modifications to the document set or the settings.
- The behavior of the Textual Near Duplicate Identification process differs based upon the operations selected on a given set. If both the Email Threading and Textual Near Duplicate Identification operations are selected on the same set, the Textual Near Duplicate Identification process only runs against the non-email documents. This includes all documents in the Documents to Analyze search. This is the recommended setup for structured analytics. Running textual near duplicate Identification against emails does not provide as useful results as email threading. Emails are better organized and reviewed by using the results of email threading, especially the information regarding email duplicate spares and inclusive emails.
If Textual Near Duplicate Identification is selected on a given set on its own (or with Language Identification and/or Repeated Content Identification), textual near duplicate identification is run against all documents in the Documents to Analyze search. This workflow might be used if emails cannot be identified in the dataset or if there is a specific need to Near Dupe the emails. - When email threading and textual near duplication identification operations are run at the same time, email threading will process only email documents and their attachments while textual near duplicate identification will only process standalone documents and attachments (not emails).
- When using email thread visualization with multiple structured analytics sets, verify that you have the correct structured analytics set name selected in the Display Options sub-tab inside the legend to ensure that you see the correct email thread information.
- If you rerun a Full Analysis on a structured analytics set, the old structured analytics data for the structured analytics set will automatically be purged. Any documents that were originally in the searchable set, but were removed after updating will have their results purged. The purge will only affect documents associated with the operation that was run. Repeated Content Filters are never purged and Incremental runs will not purge any results.
Note: Name normalization results are never purged. In order to completely re-run name normalization results, you must remove all previously identified entities and aliases from the workspace. For more information, see Deleting all data to re-run.