






After running language identification, you can review the operation report to get an overview of the results. See Viewing the Language Identification Summary.
We then recommend using language identification results to organize your workflow. See Using language identification results to drive workflow.
Viewing the Language Identification Summary
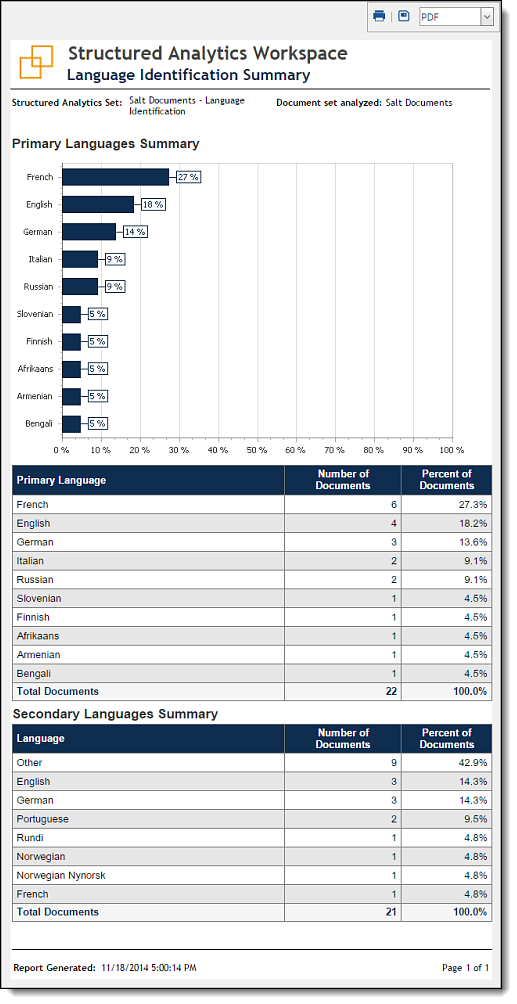
You can use the Language Identification Summary to quickly assess the results of the language identification operation. On the Structured Analytics Set console, click the View Language Identification Summary link to open the report.
The report contains the following sections:
- Primary Languages Summary - displays a breakdown of languages identified by percentage in a bar chart.
- Primary Language - table lists the total number of documents and percentage of documents identified for each primary language.
- Secondary Languages Summary - table lists the total number of documents and percentage of documents identified for each secondary language. Secondary languages may have more or fewer total documents than the primary language list. This is because the operation may identify no secondary languages or up to two secondary languages for a given document.
Your report may also include the following designations:
- Other - indicates documents containing some text that can't be identified, such as numeric data or unknown languages. This designation is also used when there are more than three languages identified in the document.
- Unable to identify language - indicates documents containing no extracted text.
Using language identification results to drive workflow
To review your language identification results, we recommend creating a Languages view on the Documents tab. For more information on creating views,
- (Optional) Doc ID Beg or Control Number - the document identifier. Select the field used as the document identifier in your workspace. The view defaults to an ascending sort on Artifact ID.
- Primary Language - the primary language identified in each record. The primary language is the language found with the highest percentage of use in a document.
- Docs_Languages - the primary and secondary (if any) languages represented in the document's text along with their percentages. This multi-object field contains the language alongside its corresponding percentage value, and it is useful for displaying in views.
Note: You may want to review secondary language information before batching documents for review.
- Docs_Languages::Language - this fixed-length field contains the languages identified in a document's extracted text. This field can be used for searching for a certain language along with a percentage value using the Docs_Languages::Percentage field.
- Docs_Languages::Percentage - this whole number field contains the percentage values for each language identified in a document's extracted text. The total percentage for a given document equals 100%. This field can be used to search for a percentage along with a certain language using the Docs_Languages::Language field.
You can Relativity's Pivot tool to assess the distribution of primary languages identified across the document set. To pivot on primary language:
- On the Documents tab, click Add Widget, and then select Pivot to add a new Pivot widget to your dashboard.
- Set Group By... to Email From, and set Pivot On... to Primary Language.
- Select Line Chart for the Default Display Type.
- Select Email From for the Sort On field.
- Select DESC for the Sort Order.
- Click Add Pivot.
- Click the
 icon in the top right corner of the Pivot widget to select options for adjusting the display or click Save to name and save the Pivot Profile so that you can easily view it later..
icon in the top right corner of the Pivot widget to select options for adjusting the display or click Save to name and save the Pivot Profile so that you can easily view it later.. 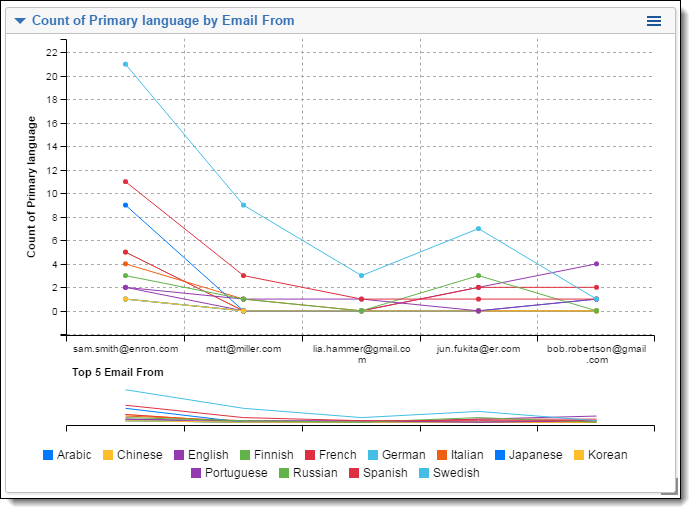
Based on the relative distribution of primary languages identified, create saved searches for each set that you want to group for batching.
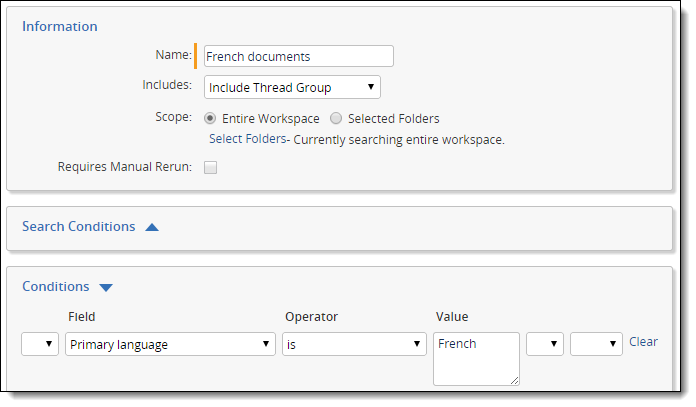
Using these saved searches, create batches of the document sets for review.