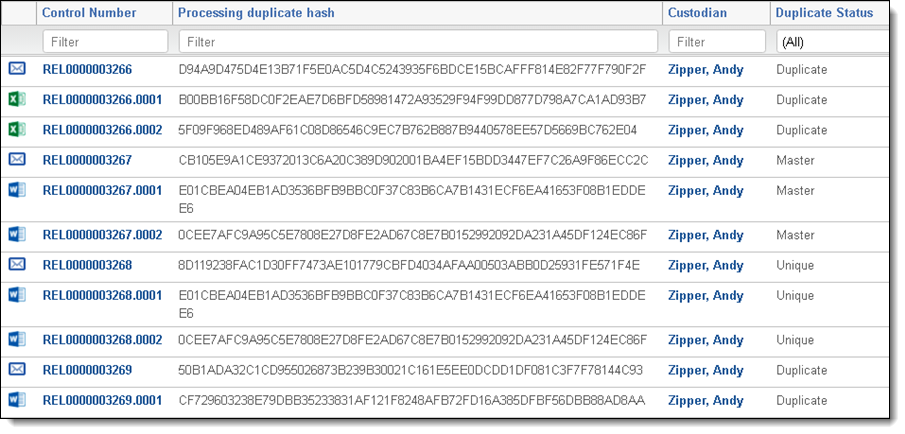
The Processing Duplication Workflow is a Relativity application that identifies primary and duplicate documents, all custodians, and all source files for documents. It also provides capabilities to identify unique, primary and duplicate files based on a relational field.
Before you begin
Supported versions
Note: Some versions of this application may not be eligible for support by Customer Support. For more information, see the Version support policy.
Click the following link to access the solution files.
| Solution version | Supported Relativity version |
|---|---|
| 2022.1.7 | All supported versions of Relativity. |
Note: You must have valid Relativity Community credentials in order to download any Community file linked to the documentation site. You'll need to enter those credentials on the Community login screen if you're not already logged in. If you're already logged in to the Community at the time you click a link, the file is automatically downloaded in the bottom left corner of your screen. If you get an error message stating "URL No Longer Exists" after clicking a Community link, it may be due to a single sign-on error related to the SAML Assertion Validator, and you should contact your IT department.
Components
This custom solution consists of the following components:
- Relativity application
- Relativity scripts that run at the workspace level within a script group
Considerations
- This script should only be run by a system admin. If you are not a system admin, we recommend you do not run this script.
- The solution may require you to create fields in your environment.
- The All Source Locations and All Custodians scripts require a new field to store the output of running those scripts.
- Please see Update Duplicate Status script for detailed information about corresponding fields that need to be created.
- You have the option of tagging a document as Responsive and then propagating that value to the document’s family members. For more information, see Applying propagation to documents.
Deploying and configuring the solution
To deploy and configure the solution, add it to the Application Library as a Relativity application by following these steps:
- Log in to Relativity.
- Navigate to the kCura Admin tab, and then click the Application Library sub-tab.
- Click on the Upload Application button.
- Next to Application File, click Select File.
- Navigate to and select the Processing Duplication Workflow.rap file included in the solution, and then click Open.
- Click the Save button.
Preparing the workspace
After you add the solution to the Application Library, you're ready to install and configure it to a workspace by following these steps:
- Navigate to the kCura Admin tab, and then click the Application Library sub-tab.
- Click the name of the Processing Duplication Workflow application.
- Next to Workspaces Installed, click Select.
- Select the check box next to the workspace that you want to install the solution in. To install the solution in more than one workspace, select the check box next to each additional workspace that you want. Move the selected workspaces to the column on the right.
- Click Apply.
- The Workspaces Installed category displays the progress of the installation.
Note: The Processing Scripts tab will be put under Other tabs.
Running the solution
After you install and configure the solution to a workspace, the Processing Item Level Scripts and Processing Family Scripts sub-tabs become available under the Processing Duplication Workflow tab and contain three Relativity scripts within a script group:
- All Custodians script (Item Level)
- All Source Locations script (Item Level)
- Update Duplicate Status script (Item Level)
- All Custodians script (Family Level)
- All Source Locations script (Family Level)
- Update Duplicate Status script (Family Level)
When choosing which script to run, keep in mind the group of documents you wish to run your script on. For example, to find which families of documents are duplicates, execute the Update Duplicate Status script (Family Level) script. To find any duplicate in your dataset regardless of family, execute the All Custodians script (Item Level).
All Custodians (Item Level) script
The All Custodians (Item Level) script populates a field with the names of all custodians who own a document. To run the All Custodians (Item Level) script:
- Navigate to the Processing Item Level Scripts sub-tab.
- The Processing Item Level Scripts page appears. Select the radio button next to All Custodians (Item Level).
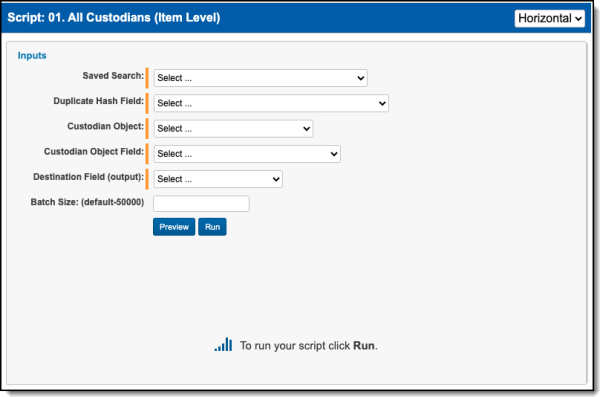
- Complete the following fields:
- Saved Search—Required. Select the saved search which will contain the group of documents the script will be executed against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another.
- Duplicate Hash Field—Required. Select the relational field which defines groups of duplicate documents. For example, MD5, SHA1, or Processing Duplication Hash.
- Custodian—Required. Select the Custodian object that contains your custodian information.
- Custodian Field—Required. Select the field that contains the custodian name.
- Destination (output)—Required. Select the long text field to store the semi-colon delimited list of custodians.
- Batch Size—this field is optional and is the number of files in a saved search batch. Leave this field blank to use the default value of 50,000 or enter a value below 50,000 to increase the script execution speed.
- Click Run.
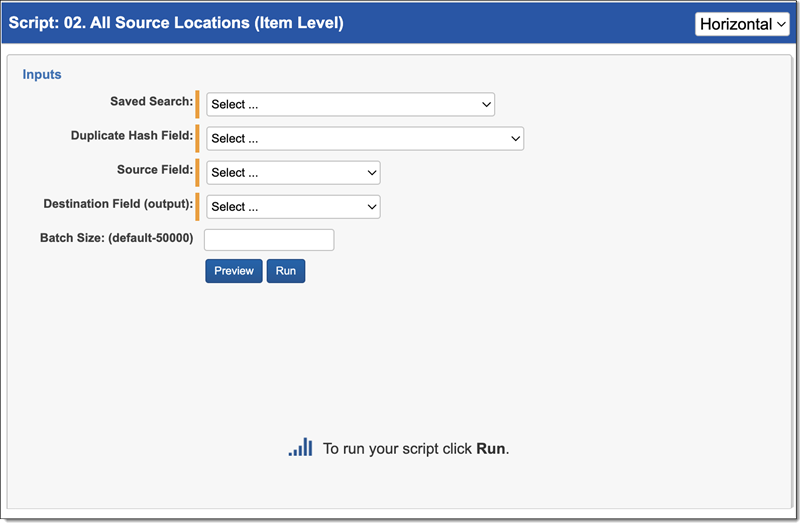
All Source Locations (Item Level) script
The All Source Locations (Item Level) script identifies all source locations for a duplicate document. To run the All Source Locations (Item Level) script:
- Navigate to the Processing scripts (Item Level) sub-tab.
- The Processing Item Level Scripts page appears. Select the radio button next to All Source Locations (Item Level).
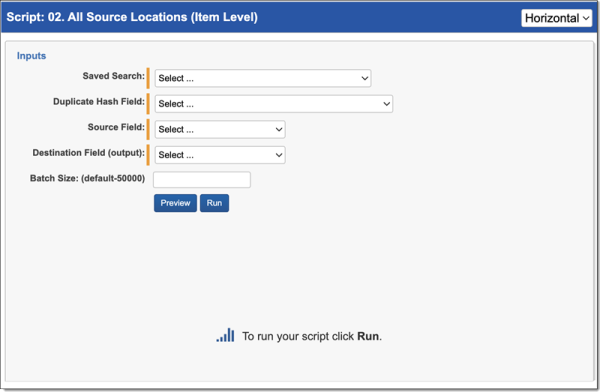
- Complete the following fields:
- Saved Search—Required. Select the saved search which will contain the group of documents the script will be executed against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another.
- Duplicate Hash Field—Required. Select the relational field which defines groups of duplicate documents. For example, MD5, SHA1, or Processing Duplication Hash.
- Source Field—Required. Select the long text field that contains the source location for documents.
- Destination Field (output)—Required. Select the long text field to store the semi-colon delimited list of source locations.
- Batch Size—this field is optional and is the number of files in a saved search batch. Leave this field blank to use the default value of 50,000 or enter a value below 50,000 to increase the script execution speed.
- Click Run.
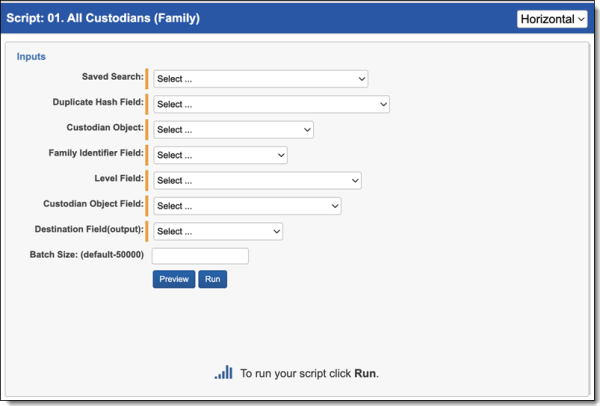
Update Duplicate Status (Item Level) script
Before running the Update Duplicate Status (Item Level) script, you need to create fields in your environment by doing the following:
- Navigate to the workspace in which you are running the solution
- Create a new single choice field on the Document object with three choices (names must be exact, but are not case-sensitive): Unique, Master, or Duplicate.
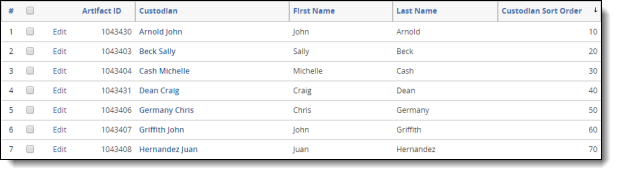
- (Optional) Make sure a whole number field is created for the Entity object if utilizing the order of the custodians associated with the documents.
- Make sure each custodian has a unique order number. Do not use numbers less than 1.
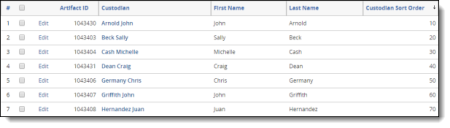
- Verify that a Custodian single-object field exists on the Document object. Create a Custodian field if one does not already exist.
- Set up a saved search that returns the group of documents the script will be executed against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another. The duplicate status field is set on all documents included in the search.
To run the Update Duplicate Status script:
- Navigate to the Processing Item Level Scripts sub-tab.
- The Processing Item Level Script page appears. Select the radio button next to Update Duplicate Status (Item Level).
- Complete the following fields:
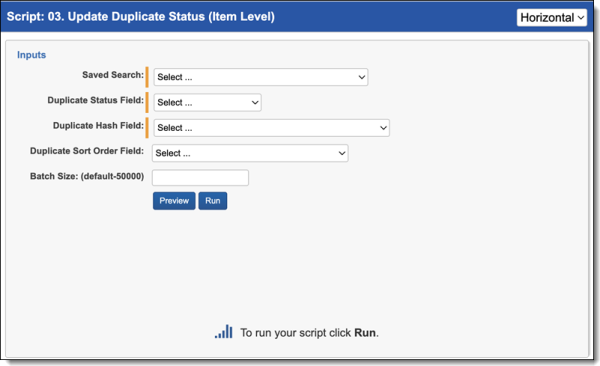
- Saved Search—use the saved search described above.
- Duplicate Status Field—use the duplicate status field created above.
- Duplicate Hash—select a file duplicate hash field. If using Relativity Processing to load data, the Processing duplicate hash field can be used.
- Duplicate Sort Order—this is a field located on the Entity object. Leave this blank unless you have set up a field on the Entity object to maintain a custom priority sort order by custodian. When this field is blank, the system sorts on document artifact ID from the Document object, so the first document loaded in the workspace becomes the Primary document when duplicates are identified. See Viewing the Results for more information on how this field operates.
- Batch Size—this field is optional and is the number of files in a saved search batch. Leave this field blank to use the default value of 50,000 or enter a value below 50,000 to increase the script execution speed.
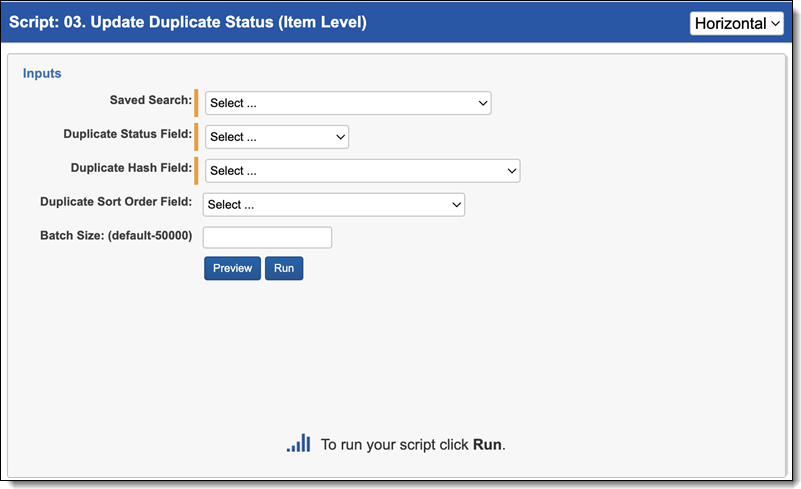
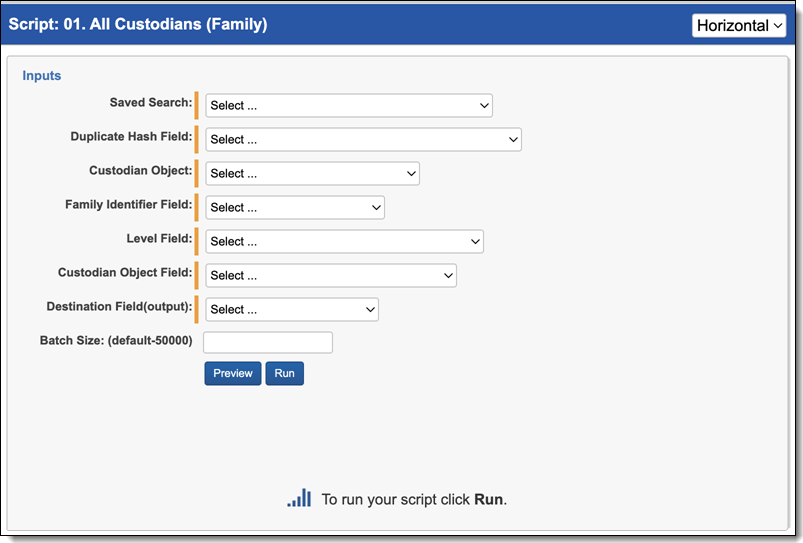
All Custodians (Family) script
The All Custodians (Family) script populates a field with the names of all custodians who own a document. To run the All Custodians (Family) script:
- Navigate to the Processing Family Scripts sub-tab.
- The Processing Family Scripts page appears. Select the radio button next to All Custodians (Family).
- Complete the following fields:
- Saved Search—Required. Select the saved search which contains the group of documents the script executes against. This should include all parent level documents, and their families. This is because the script will propagate the tagging from parents to the children level.
- Duplicate Hash Field—Required. Select the relational field which defines groups of duplicate documents. For example, MD5, SHA1, or Processing Duplication Hash.
- Custodian Object—Required. Select the Custodian object that contains your custodian information.
- Family Identifier—Required. Select the relational field which defines groups of family documents.
- Level Field—Required. Select the whole number field which defines a numeric value indicating how deeply nested the document is within the family. This is commonly called Level if the data was discovered and published through Relativity Processing.
- Custodian Object Field—Required. Select the field that contains the custodian name.
- Destination Field (output)—Required. Select the long text field to store the semi-colon delimited list of source locations.
- Batch Size—this field is optional and is the number of files in a saved search batch. Leave this field blank to use the default value of 50,000 or enter a value below 50,000 to increase the script execution speed.
- Click Run.
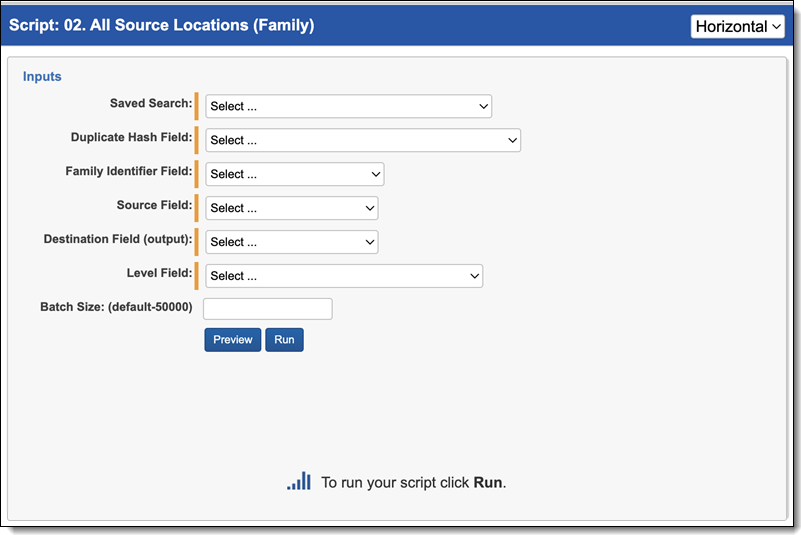
All Source Locations (Family) script
The All Source Locations (Family) script identifies all source locations for a duplicate document. To run the All Source Locations (Family) script:
- Navigate to the Processing Family Scripts sub-tab.
- The Processing Family Scripts page appears. Select the radio button next to All Source Locations (Family).
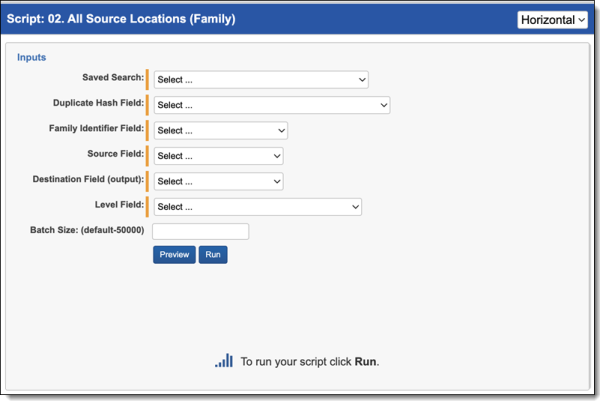
- Complete the following fields:
- Saved Search—Required. Select the saved search which will contain the group of documents the script will be executed against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another.
- Duplicate Hash Field—Required. Select the relational field which defines groups of duplicate documents. For example, MD5, SHA1, or Processing Duplication Hash.
- Family Identifier—Required. Select the relational field which defines groups of family documents.
- Source Field—Required. Select the long text field that contains the source location for documents.
- Destination Field (output)—Required. Select the long text field to store the semi-colon delimited list of source locations.
- Level Field—Required. Select the whole number field which defines a numeric value indicating how deeply nested the document is within the family.
- Batch Size—this field is optional and is the number of files in a saved search batch. Leave this field blank to use the default value of 50,000 or enter a value below 50,000 to increase the script execution speed.
- Click Run.
Update Duplicate Status (Family) script
Before running the Update Duplicate Status (Family) script, you need to create fields in your environment by doing the following:
- Navigate to the workspace in which you are running the solution.
- Create a new single choice field on the Document object with three choices (names must be exact, but are not case-sensitive): Unique, Master, or Duplicate.
- (Optional) Make sure a whole number field is created for the Entity object if utilizing the order of the custodians associated with the documents.
-
Make sure each custodian has a unique order number. Do not use numbers less than 1.
- Verify that a Custodian single-object field exists on the Document object. Create a Custodian field if one does not already exist.
- Set up a saved search that returns the group of documents the script will be executed against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another. The duplicate status field will be set on all documents included in the search.
To run the Update Duplicate Status script:
- Navigate to the Processing Family Scripts tab.
- The Processing Family Script page appears. Select the radio button next to Update Duplicate Status (Family).
- Complete the following fields:
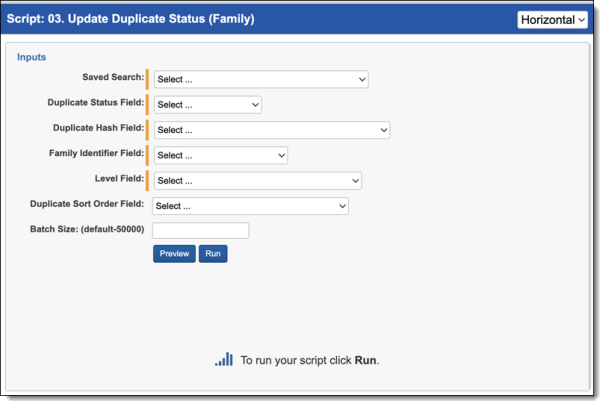
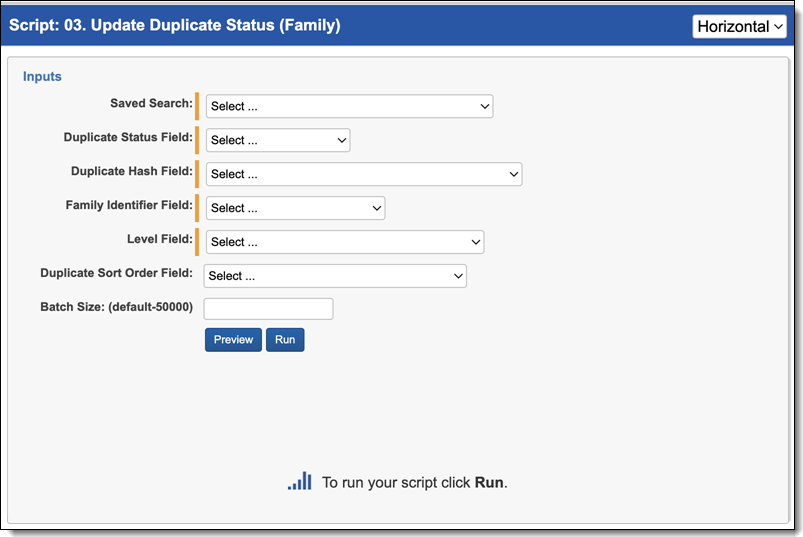
- Saved Search—Required. Select the saved search which will contain the group of documents the script will be executed against. This should include all files you wish to run the script against regardless of family relationships. This is because the script will run on each document independently of one another.
- Duplicate Status Field—use the duplicate status field created above.
- Duplicate Hash Field—select a file duplicate hash field. If using Relativity Processing to load data, the Processing duplicate hash field can be used.
- Family Identifier—Required. Select the relational field which defines groups of family documents.
- Level—Required. Select the whole number field which defines a numeric value indicating how deeply nested the document is within the family.
- Duplicate Sort Order—this is a field located on the Entity object. Leave this blank unless you have set up a field on the Entity object to maintain a custom priority sort order by custodian. When this field is blank, the system sorts on document artifact ID from the Document object, so the first document loaded in the workspace becomes the Primary document when duplicates are identified. See Viewing the Results for more information on how this field operates.
- Batch Size—this field is optional and is the number of files in a saved search batch. Leave this field blank to use the default value of 50,000 or enter a value below 50,000 to increase the script execution speed.
Viewing the results
The results of running depend on which script was executed.
All Custodians (Item Level) script
After you run the All Custodians (Item Level) script, the results appear as a report on the script page.
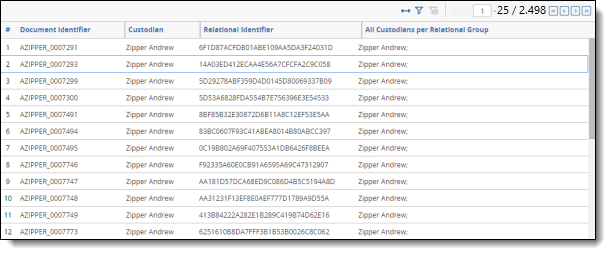
The following table lists and describes the columns in the report.
|
Column |
Description |
|---|---|
|
Document Identifier |
The value of the document identifier on the Document object. |
|
Custodian |
The value of the Custodian associated with the document. |
|
Relational Identifier |
The value of the relational field chosen to define groups of related documents. |
|
All Custodians per Relational Group |
The semi-colon delimited list of all custodians that are associated with the document in the relational group. |
All Source Locations (Item Level) script
After you run the All Source Locations (Item Level) script, the results appear as a report on the script page.
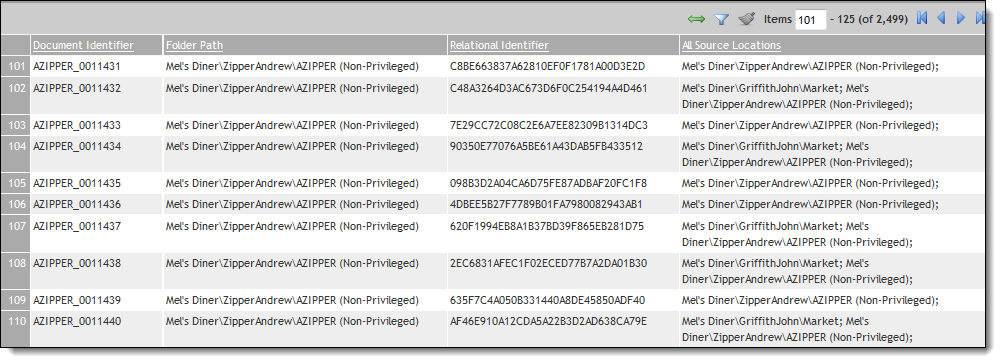
The following table lists and describes the columns in the report:
|
Column |
Description |
|---|---|
|
Document Identifier |
The value of the document identifier on the Document object. |
|
Folder Path |
The value of the source field file location associated with the document. |
|
Relational Identifier |
The value of the relational field chosen to define groups of related documents. |
|
All Source Locations |
The semi-colon delimited list of all source locations associated with the document. |
Update Duplicate Status (Item Level) script
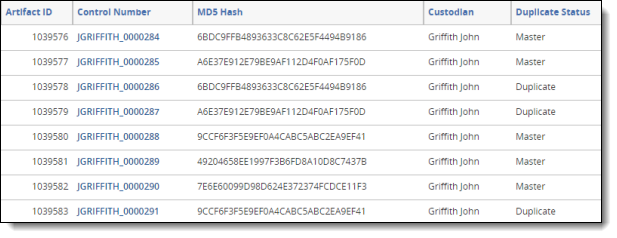
When the script is executed, the selected Duplicate Status Field is cleared for all documents in the workspace. Once the field is cleared, the Duplicate Status Field is populated with the following values for any documents included in the selected saved search:
- Unique – Documents where there is only one document in the saved search with the same relational identifier
- Master – If Duplicate Sort Order is selected, documents where there is more than one document in the saved search with the same relational identifier and the lowest order of the associated custodian. If multiple documents in the same group shared the same custodian, then the lowest document artifact ID. If Duplicate Sort Order is not selected, documents where there is more than one document in the saved search which have the lowest document artifact ID.
- Duplicate – If Duplicate Sort Order is selected, documents where there is more than one document in the saved search with the same relational identifier, which do not have the lowest ordered custodian in the relational group. If Duplicate Sort Order is not selected, documents where there is more than one document in the saved search with the same relational identifier which do not have the lowest artifact ID in the relational group.
- Not Set – Documents will remain "Not set" in the selected Duplicate Status Field if the selected Relational Identifier is not set.
Any documents not included in the selected saved search will be excluded from the logic to calculate duplicate status and will not be populated in the selected Duplicate Status Field.
When the script is complete, you will receive an "Update Complete" message on the script page. Documents in the saved search are updated.
All Custodians (Family) script
After you run the All Custodians (Family) script, the results appear as a report on the script page.
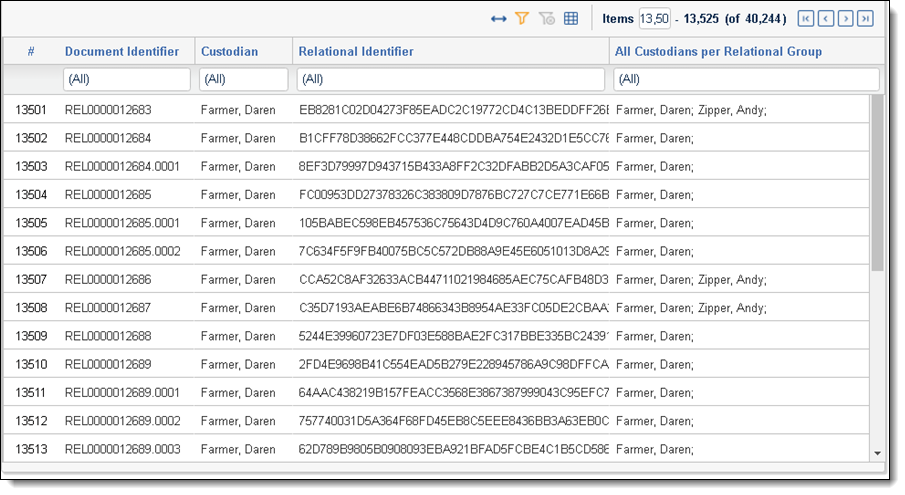
The following table lists and describes the columns in the report.
|
Column |
Description |
|---|---|
|
Document Identifier |
The value of the document identifier on the Document object. |
|
Custodian |
The value of the Custodian associated with the document. |
|
Relational Identifier |
The value of the relational field chosen to define groups of related documents. |
|
All Custodians per Relational Group |
The semi-colon delimited list of all custodians that are associated with the document in the relational group. |
All Source Locations (Family) script
After you run the All Source Locations (Family) script, the results appear as a report on the script page.
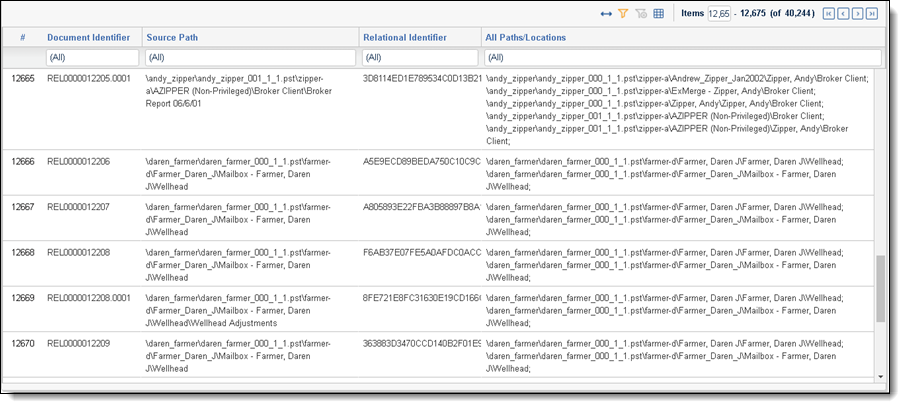
The following table lists and describes the columns in the report:
|
Column |
Description |
|---|---|
|
Document Identifier |
The value of the document ide The value of the source field file location associated with the document. ntifier on the Document object. |
|
Folder Path |
|
|
Relational Identifier |
The value of the relational field chosen to define groups of related documents. |
|
All Source Locations |
The semi-colon delimited list of all source locations associated with the document. |
Update Duplicate Status (Family) script
When the script is executed, the selected Duplicate Status Field is cleared for all documents in the workspace. Once the field is cleared, the Duplicate Status Field is populated with the following values for any documents included in the selected saved search:
- Unique – Documents where there is only one document in the saved search with the same relational identifier
- Master – If Duplicate Sort Order is selected, documents where there is more than one document in the saved search with the same relational identifier and the lowest order of the associated custodian. If multiple documents in the same group shared the same custodian, then the lowest document artifact ID. If Duplicate Sort Order is not selected, documents where there is more than one document in the saved search with the same relational identifier which have the lowest document artifact ID in the relational group.
- Duplicate – If Duplicate Sort Order is selected, documents where there is more than one document in the saved search with the same relational identifier, which do not have the lowest ordered custodian in the relational group. If Duplicate Sort Order is not selected, documents where there is more than one document in the saved search with the same relational identifier which do not have the lowest artifact ID in the relational group.
- Not Set – Documents will remain "Not set" in the selected Duplicate Status Field if the selected Relational Identifier is not set.
Any documents not included in the selected saved search will be excluded from the logic to calculate duplicate status and will not be populated in the selected Duplicate Status Field.
When the script is complete, you will receive an "Update Complete" message on the script page. Documents in the saved search are updated.