






Note the following special considerations regarding deduplication:
-
Deduplication is applied only on Level 1 non-container parent files. If a child file (Level 2+) has the same processing duplicate hash as a parent file or another child file, then they will not be deduplicated, and they will be published to Relativity, regardless of whether the hash field has the same value. This is done to preserve family integrity. You can find out the level value for a file by mapping the Level metadata from the Field Catalog.
- In rare cases, it’s possible for child documents to have different hashes when the same files are processed into different workspaces. For example, if the children are pre-Office 2007 files, then the hashes could differ based on the way the children are stored inside the parent file. In such cases, the child documents aren’t identical (unlike in a ZIP container) inside the parent document. Instead, they’re embedded as part of the document’s structure and have to be created as separate files, and the act of separating the files generates a new file entirely. While the content of the new file and the separated file are the same, the hashes don’t match exactly because the OLE-structured file contains variations in the structure. This is not an issue during deduplication, since deduplication is applied only to the level-1 parent files, across which hashes are consistent throughout the workspace.
- When deduplication runs as part of publish, it doesn't occur inside the Relativity database or the Relativity SQL Server and thus has no effect on review. As a result, there is no database lockout tool available, and reviewers are able to access a workspace and perform document review inside it while publish and deduplication are in progress.
- At the time of publish, if two data sources have the same order, or if you don't specify an order, deduplication order is determined by Artifact ID.
-
If you change the deduplication method between publications of the same data, even if you're using different processing sets, you may encounter unintended behavior. For example, if you publish a processing set with None selected for the deduplication method on the profile and then make a new set with the same data and publish it with Global selected, Relativity won't publish any new documents because they will all be considered duplicates. In addition, the All Custodians field will display unexpected data. This is because the second publish operation assumed that all previous publications were completed with the same deduplication settings.
 The content on this site is based on the most recent monthly version of Relativity, which contains functionality that has been added since the release of the version on which Relativity's exams are based. As a result, some of the content on this site may differ significantly from questions you encounter in a practice quiz and on the exam itself. If you encounter any content on this site that contradicts your study materials, please refer to the What's New and/or the Release Notes for details on all new functionality.
The content on this site is based on the most recent monthly version of Relativity, which contains functionality that has been added since the release of the version on which Relativity's exams are based. As a result, some of the content on this site may differ significantly from questions you encounter in a practice quiz and on the exam itself. If you encounter any content on this site that contradicts your study materials, please refer to the What's New and/or the Release Notes for details on all new functionality.Global deduplication
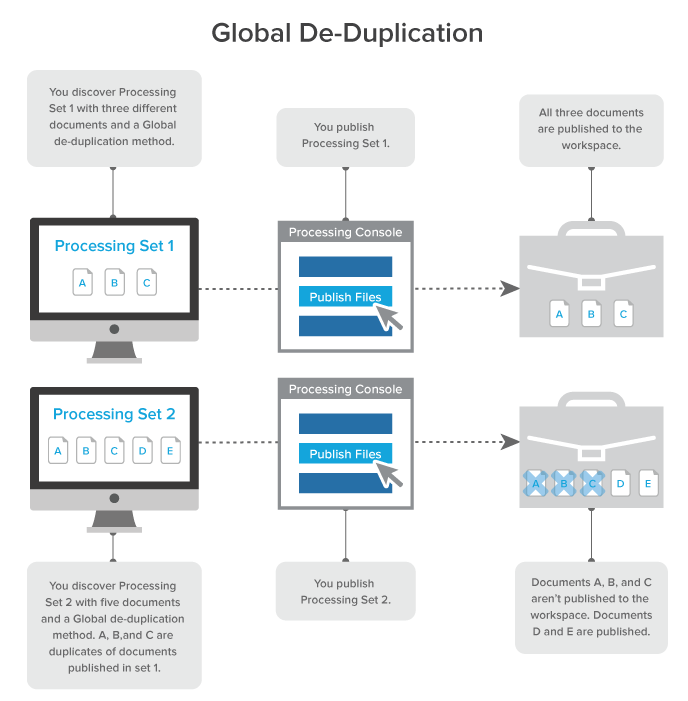
When you select Global as the deduplication method on the profile, documents that are duplicates of documents that were already published to the workspace in a previous processing set aren't published again.
Custodial deduplication
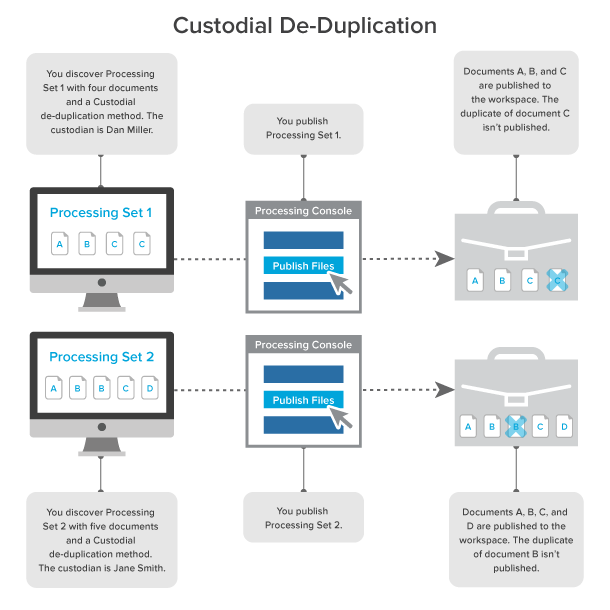
When you select Custodial as the deduplication method on the profile, documents that are duplicates of documents owned by the custodian specified on the data source aren't published to the workspace.
No deduplication
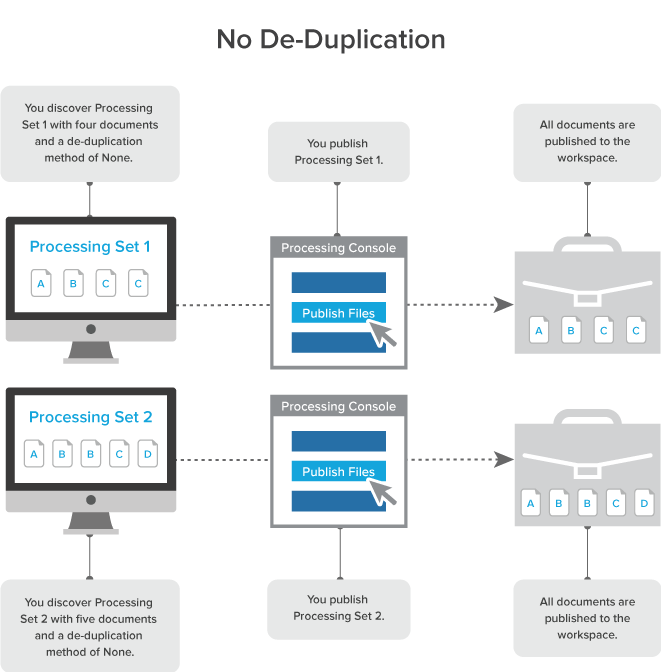
When you select None as the deduplication method on the profile, all documents and their duplicates are published to the workspace.
Global deduplication with attachments
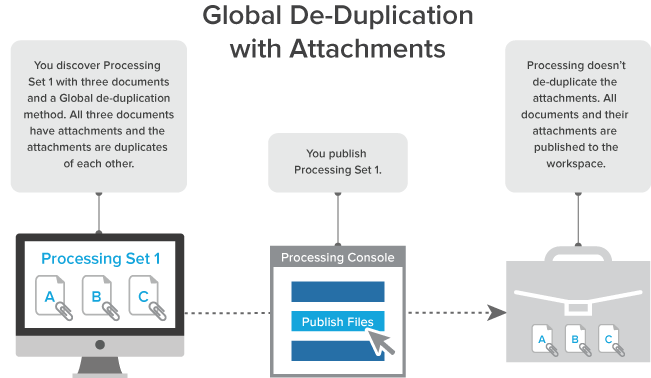
When you select Global as the deduplication method on the profile and you publish a processing set that includes documents with attachments, and those attachments are duplicates of each other, all documents and their attachments are published to the workspace.
Global deduplication with document-level errors
When you select Global as the deduplication method on the profile, and you publish a processing set that contains a password-protected document inside a zip file, you receive an error. When you unlock that document and republish the processing set, the document is published to the workspace. If you follow the same steps with a subsequent processing set, the unlocked document is de-duplicated and not published to the workspace.
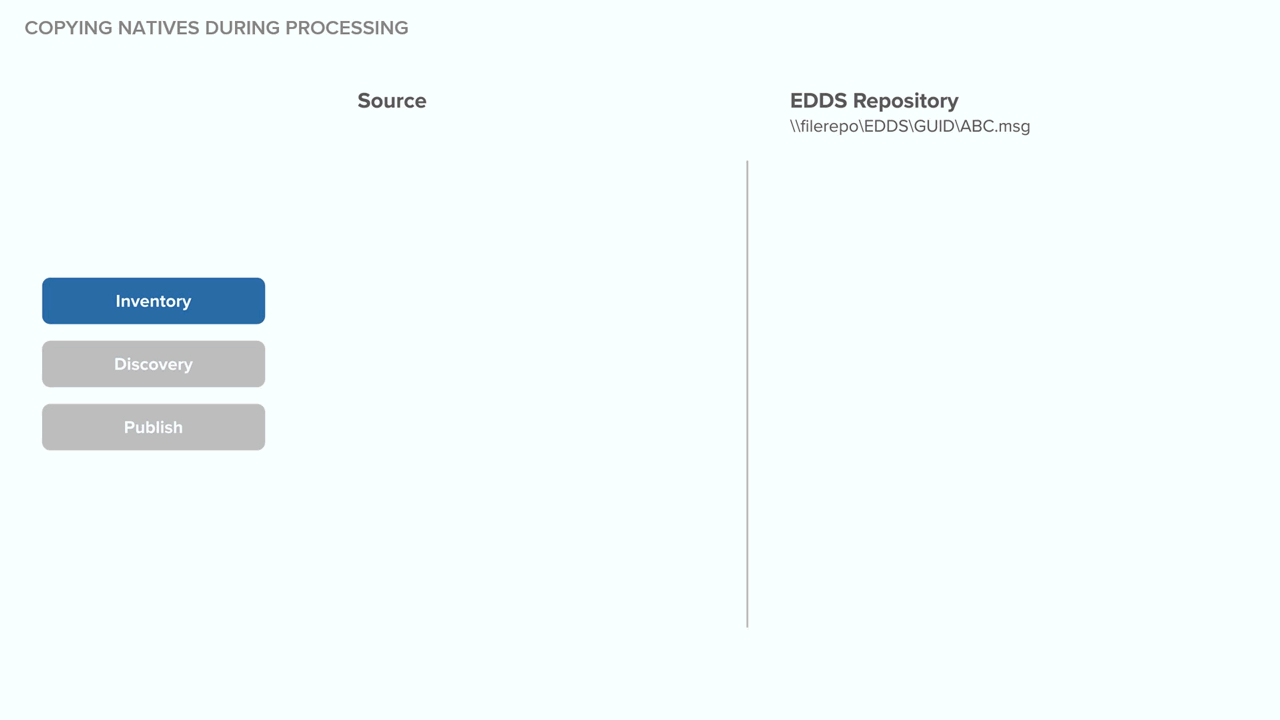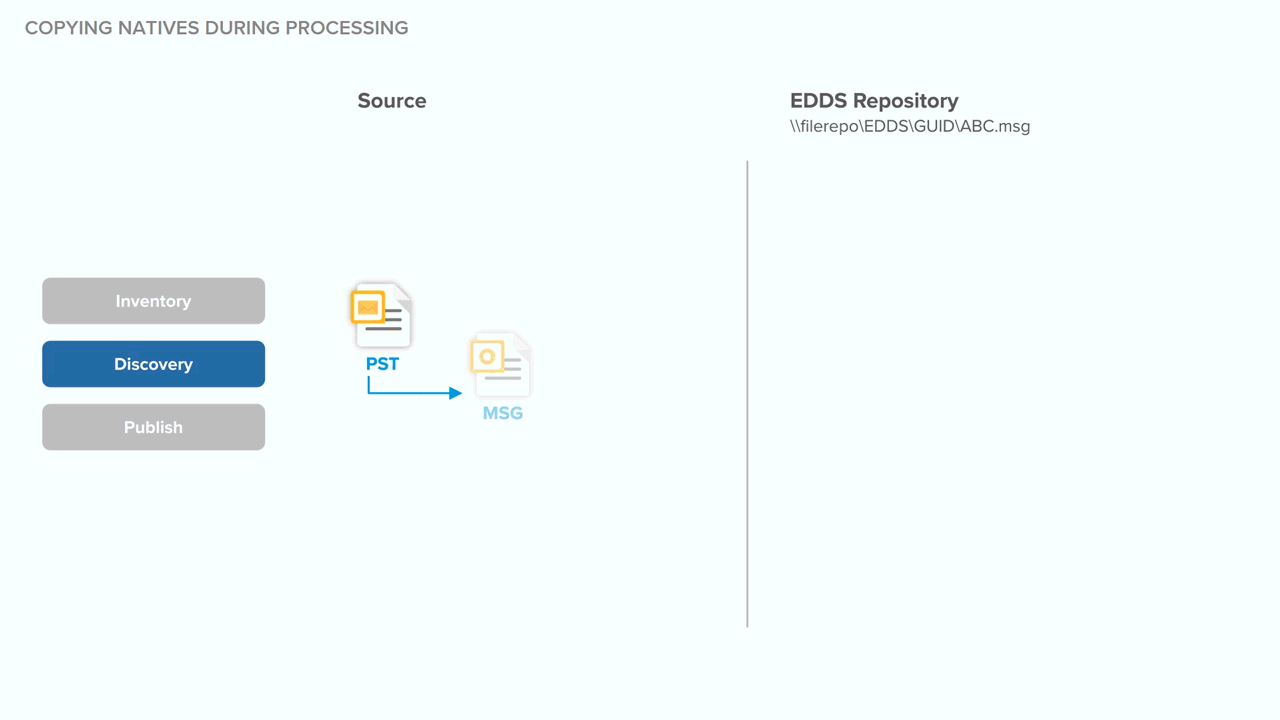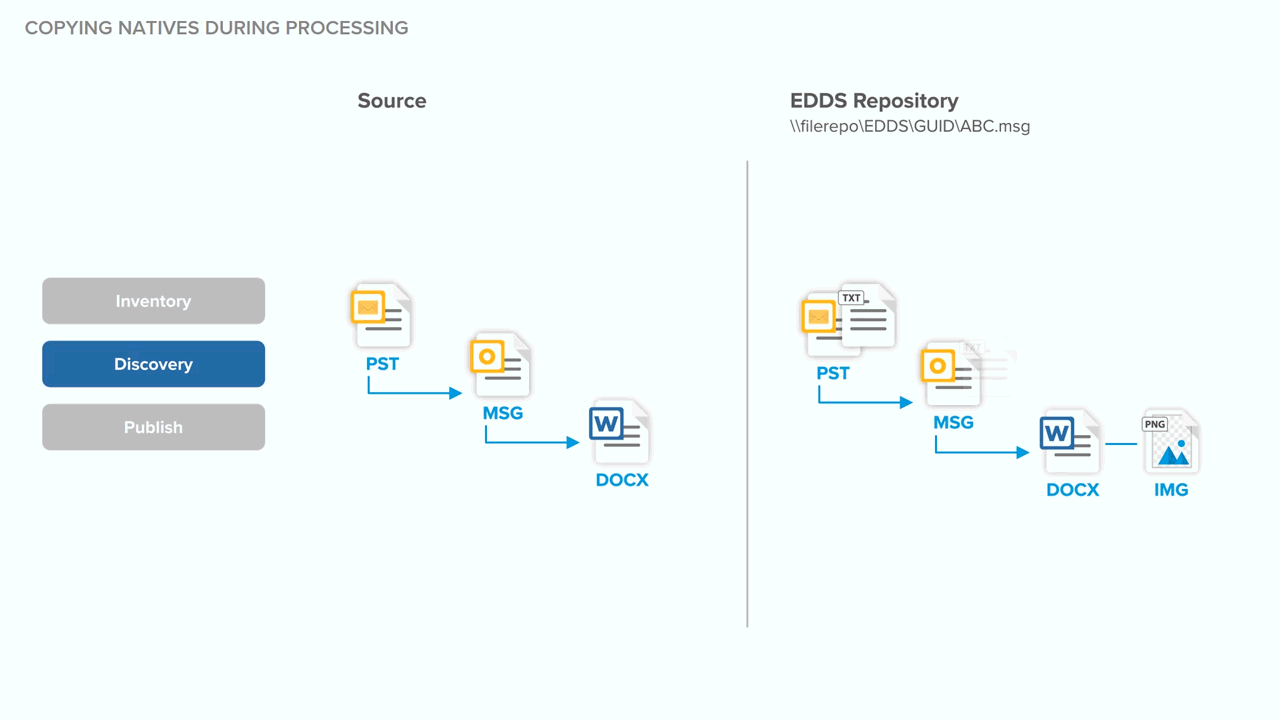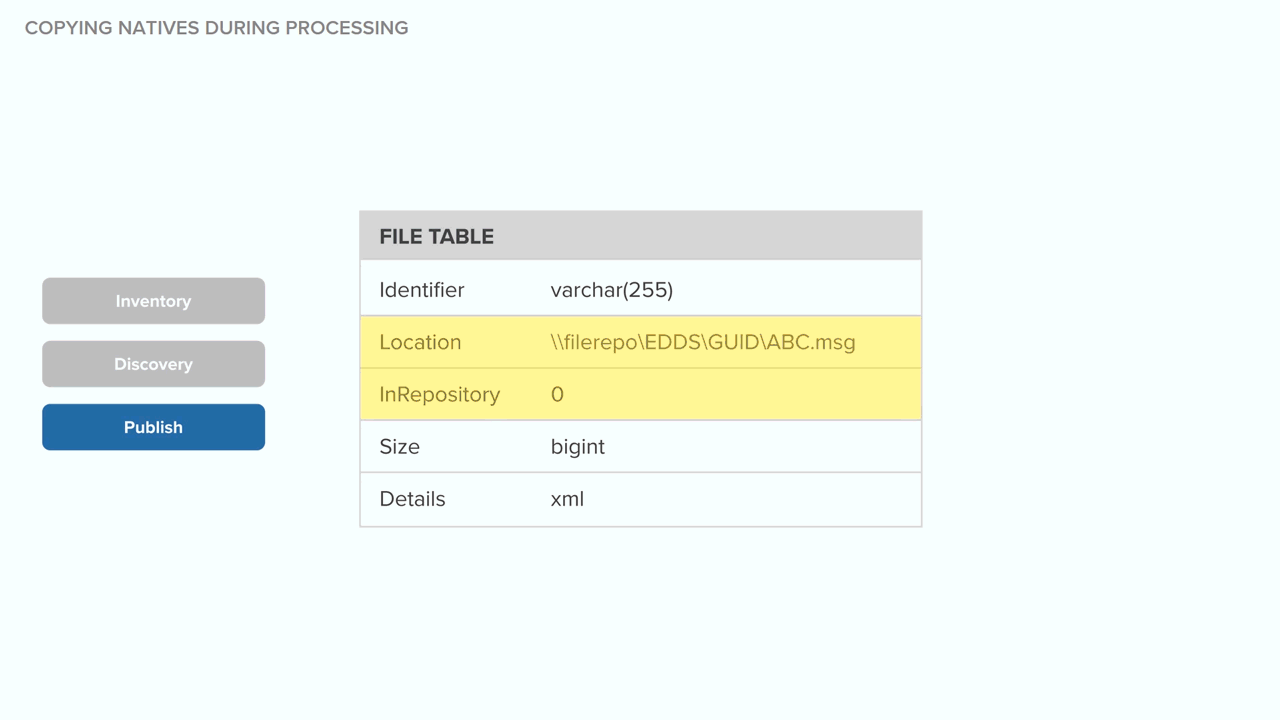
Technical notes for deduplication
The system uses the algorithms described below to calculate hashes when performing deduplication on both loose files (standalone files not attached to emails) and emails for processing jobs that include either a global or custodial deduplication.
The system calculates hashes in a standard way, specifically by calculating all the bits and bytes that make the content of the file, creating a hash, and comparing that hash to other files in order to identify duplicates.
The following hashes are involved in deduplication:
- MD5/SHA1/SHA256 hashes—provide a checksum of the physical native file.
- Deduplication hashes—the four email component hashes (body, header, recipient, and attachment) processing generates to de-duplicate emails.
- Processing duplicate hash—the hash used by processing in Relativity to de-duplicate files, which references a Unicode string of the header, body, attachment, and recipient hashes generated by processing. For loose files, the Processing Duplicate Hash is a hash of the file's SHA256 hash.
Calculating MD5/SHA1/SHA256 hashes
To calculate a file hash for native files, the system:
- Opens the file.
- Reads 8k blocks from the file.
- Passes each block into an MD5/SHA1/SHA256 collator, which uses the corresponding standard algorithm to accumulate the values until the final block of the file is read. Envelope metadata (such as filename, create date, last modified date) is excluded from the hash value.
- Derives the final checksum and delivers it.
Note: Relativity can't calculate the MD5 hash value if you have FIPS (Federal Information Processing Standards cryptography) enabled for the worker manager server.
Calculating deduplication hashes for emails
MessageBodyHash
To calculate an email’s MessageBodyHash, the system:
- Captures the PR_BODY tag from the MSG (if it’s present) and converts it into a Unicode string.
- Gets the native body from the PR_RTF_COMPRESSED tag (if the PR_BODY tag isn’t present) and either converts the HTML or the RTF to a Unicode string.
- Removes all carriage returns, line feeds, spaces, and tabs from the body of the email to account for formatting variations. An example of this is when Outlook changes the formatting of an email and displays a message stating, “Extra Line breaks in this message were removed.”
Note: The removal of all the components mentioned above is necessary because if the system didn't do so, one email containing a carriage return and a line feed and another email only containing a line feed would not be deduplicated against each other since the first would have two spaces and the second would have only one space.
- Constructs a SHA256 hash from the Unicode string derived in step 2 or 3 above.
HeaderHash
To calculate an email’s HeaderHash, the system:
- Constructs a Unicode string containing Subject<crlf>SenderName<crlf>SenderEMail<crlf>ClientSubmitTime.
- Derives the SHA256 hash from the header string. The ClientSubmitTime is formatted with the following: m/d/yyyy hh:mm:ss AM/PM. The following is an example of a constructed string:
RE: Your last email
Robert Simpson
robert@relativity.com
10/4/2010 05:42:01 PM
RecipientHash
The system calculates an email’s RecipientHash through the following steps:
- Constructs a Unicode string by looping through each recipient in the email and inserting each recipient into the string. Note that BCC is included in the Recipients element of the hash.
- Derives the SHA256 hash from the recipient string RecipientName<crlf>RecipientEMail<crlf>. The following is an example of a constructed recipient string of two recipients:
Russell Scarcella
rscarcella@relativity.com
Kristen Vercellino
kvercellino@relativity.com
AttachmentHash
To calculate an email’s AttachmentHash, the system:
- Derives a SHA256 hash for each attachment.
- If the attachment is a not an email, the normal standard SHA256 file hash is computed for the attachment.
- If the attachment is an e-mail, we use the e-mail hashing algorithm described to Calculating deduplication hashes for emails to generate all four de-dupe hashes. Then, these hashes are combined, as described in Calculating the Relativity deduplication hash, to generate a single SHA256 attachment hash.
- Encodes the hash in a Unicode string as a string of hexadecimal numbers without <crlf> separators.
- Constructs a SHA256 hash from the bytes of the composed string in Unicode format. The following is an example of constructed string of two attachments: 80D03318867DB05E40E20CE10B7C8F511B1D0B9F336EF2C787CC3D51B9E26BC9974C9D2C0EEC0F515C770B8282C87C1E8F957FAF34654504520A7ADC2E0E23EA
Beginning in
Calculating the Relativity deduplication hash
To derive the Relativity deduplication hash, the system:
- Constructs a string that includes the SHA256 hashes of all four email components described above, as seen in the following example. For more information, see Calculating deduplication hashes for emails.
`6283cfb34e4831c97e363a9247f1f01beaaed01db3a65a47be310c27e3729a3ee05dce5acaec3696c681cd7eb646a221a8fc376478b655c81214dca7419aabee6283cfb34e4831c97e363a9247f1f01beaaed01db3a65a47be310c27e3729a3ee3843222f1805623930029bad6f32a7604e2a7acc10db9126e34d7be289cf86e`
- We convert the above string to a UTF-8 byte array.
- We then take that byte array and generate a SHA256 hash of it.
Note: If two emails have an identical body, attachment, recipient, and header hash, they are duplicates.
Note: For loose files, the Processing Duplicate Hash is a hash of the file's SHA256 hash.