






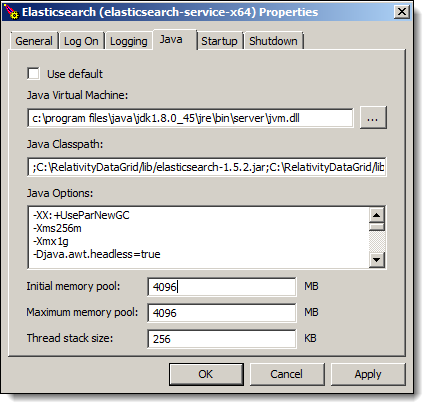
Setting the Java maximum memory pool
Once the Elasticsearch service has been installed on all of the Data Grid nodes, the maximum amount of machine memory that Java can use must be configured.
The Maximum memory pool should be half of the total RAM of the machine with a maximum setting of 30GB (30000 MB). It's recommended that you keep the Thread stacks size value at its default of 256.
Storage consideration
Consider the following factors when selecting storage types for Data Grid:
- Data Grid is a distributed system that you should run on storage local to each server. Regular disks are acceptable in tier 1 setups, but consider SSDs in tier 2 and tier 3 setups for their added performance benefits.
- Don't place the index on a remotely mounted file system (e.g., NFS or SMB/CIFS); use storage local to the machine instead.
- Use modern solid-state disks (SSDs) because they are far faster than even the fastest spinning disks. They have lower latency for random access, higher sequential IO, and are better at highly concurrent IO required for simultaneous indexing, merging, and searching.
- Stripe your index across multiple SSDs by setting multiple path.data directories or configuring a RAID 0 array. The two are similar, except instead of striping at the file block level, Elasticsearch "stripes" at the individual index files level. Either approach increases the risk of failure for a single shard in exchange for faster IO performance because the failure of any one SSD destroys the index. Optimize single shards for maximum performance and then add replicas across different nodes to create redundancy for any potential node failures. You can also create frequent snapshots of the index for further insurance. See the following site for more information: https://www.elastic.co/blog/performance-considerations-elasticsearch-indexing.
Network connectivity
Network connectivity can impact performance due to the distributed architecture of Data Grid (especially during peak activity). When a new data node is added to the cluster or a data node goes down, Data Grid will rebalance the data among the data nodes for the most optimal configuration. With this rebalancing of the shards, large amounts of data have the ability to move between data nodes. For Tier environments, consider starting off with a 4GB networking connections but once the environment is entering a Tier 3 environment, a 10GB connection should be considered for optimal performance.
Users with 10 GB networks have better performance during recovery times and snapshots consisting of large, bulk file movements.
Shard settings
A shard is a container for your data that's distributed across your server’s nodes. If you set your shard setting too high, it can create performance problems when writing and searching your data; however, if you set your shard setting too low, you can’t improve performance by adding new nodes to your cluster. The number of shards in a cluster should generally be equal to two times your total number of data nodes. That means you can double your data nodes before you stop seeing performance gains. Take that into consideration if you have plans to increase the number of nodes on your cluster.
|
|
Tier 1 |
Tier 2 |
Tier 3 |
|---|---|---|---|
|
Recommended shard settings* |
6 shards total with 2 shards per node 9 shards total with 3 shards per node | 6 to 12 shards total with 2 shards per node 9 to 18 shards total with 3 shards per node | 2 shards per node regardless of total number of shards. |
|
Limitations** |
Maximum index size: 300 GB to 450 GB (~600 GB to 900 GB SQL data) |
Maximum index size: 600GB to 900GB (~1200GB to 1800GB SQL data) |
Maximum index size: 600GB at 6 nodes 900GB at 9 nodes 1500GB at 15 nodes |
Note: We recommend a setting of two shards per node, and 30GB per shard. However, to store larger indexes and add more nodes easily in the future, three shards per node is an acceptable setting. Using three versus two could potentially decrease the performance.