






Using near duplicate analysis in review
Relativity can identify textually similar documents to assist in and speed up the review process. Near duplicate analysis is best suited for grouping documents which can then be batched for review based on the similarity, or used to create new document sets for further analysis. The goal is for reviewers to have the ability to see similar documents at the same time based on their textual similarity.
Near duplicate analysis overview
- After running a Near Duplicate analysis, system admins should view the Textual Near Duplicate Summary on the set’s Structured Analytics console, which breaks down the number of textual near duplicate groups that have been identified, along with averages of percentage of similarity and of the number of documents per near duplicate document group.
- Textual Near Duplicate Identification sorts the documents by size, from largest to smallest. This is the order in which they are processed. The most visible optimization and organizing notion is the principal document. The principal document is the largest document in a similar group and is the document that all others are compared to when determining whether they are near duplicates. If the current document is a close enough match to the principal document, as defined by the Minimum Similarity Percentage, it is placed in that group. If no current groups are matches, the current document becomes a new principal document. When the process is complete, only principal documents that have one or more near duplicates are shown in groups.
- When running the process, a Minimum Similarity Percentage is assigned. This parameter indicates how similar a document must be to a principal document to be placed into that principal's group.
Running near duplication analysis
System admins should create a Textual Near Duplicates (TND) view for the review team. This view will contain only documents that appear in TND groups, not documents which were submitted to the engine but found to be non-matches.
- In the Near Duplicate Identification view, add the following output fields (assuming the Structured Analytics Set was run with a prefix of “S1” and the S1::Textual Near Duplicate Group was mapped to a relational field called “Textual Near Duplicate Group”):
- S1::Textual Near Duplicate Principal - identifies the principal document with a "Yes" value. The principal is the largest document in the duplicate group. It acts as an anchor document to which all other documents in the near duplicate group are compared.
- S1::Textual Near Duplicate Similarity - the percent value of similarity between the near duplicate document and its principal document. If “ignore numbers” is set to “true”, this percentage considers only tokens (i.e. words) beginning with letters. Punctuation and whitespace are ignored, but word order is considered.
- Textual Near Duplicate Group - the identifier for a given group of textual near duplicate documents. This is a relational field which provides relational capabilities. However, you can map S1::Textual Near Duplicate Group to any relational field when you set up the Structured Analytics Set.
- Add a condition to only show documents where the Textual Near Duplicate Group field is set.
(Click to expand)
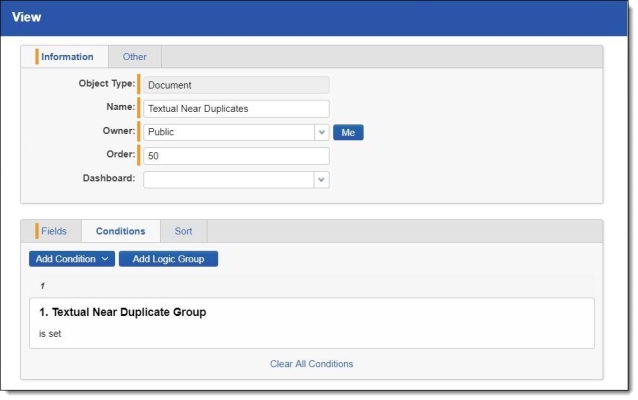
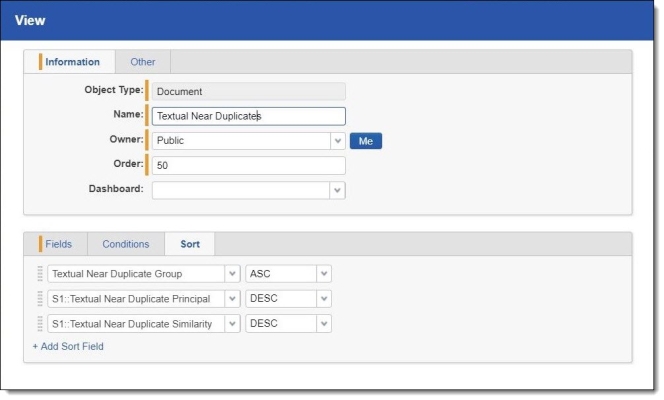
- Set the following sort orders on the Near Duplicate Identification view to list the textual near duplicate principals with the highest percentage of textual near duplicate similarity at the top:
- Textual Near Duplicate Group - Ascending
- S1::Textual Near Duplicate Principal - Descending
- S1::Textual Near Duplicate Similarity - Descending
(Click to expand)
- On the Other tab, set the Group Definition to Textual Near Duplicate Group. This ensures that bold blue bars will appear between each group.
All documents should be reviewed in this process. Use the grouping and similarity to speed up the review process. The Relativity Compare function can compare two documents to assess their similarities and differences.
Reviewers will be able to view documents that are extremely similar but not identical to each other. For example, the case team may need to ensure a series of very similar reports are coded the same way. Another possible use is to help locate additional privileged documents that might have been missed during first pass review. In situations like these, it is common to use a view that displays textual near duplicates. Note that exact word order is analyzed during this analysis, though punctuation and whitespace are not.
Example
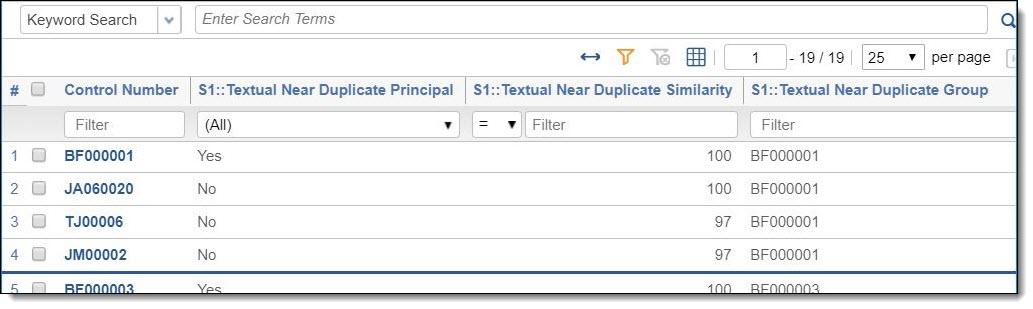
Consider the following example. The first document, BF000001, is the group’s principal, as indicated by the “Yes” value in the S1::Textual Near Duplicate Principal field. It has a score of 100 (as do all principals). Not all documents with a score of 100 are necessarily principals, however. The next three documents are part of BF000001’s relational group. The second document (JA060020) is identical to the principal. We know this because it is 100% similar, as shown in the S1::Textual Near Duplicate Similarity field. The last two documents (TJ000006 and JM00002) are very closely similar to the principal but are not exact duplicates; their scores indicate they are each 97% similar to the principal.
Workflow considerations
Textual near duplicate groups have a relational field that can be used to code several documents at once. Documents contained in the near duplicate group are textually similar, but similarity is usually not enough to treat near-duplicates as identical documents for the purposes of review. As such:
- It is not recommended to propagate coding on near duplicates, unless other analysis or evidence points to their similarity to justify such a step.
- It is not recommended to delete or otherwise shelve near duplicates. However, focusing just on the principal document of each group can make sense in certain early-stage workflows, such as clustering to understand conceptuality of a data set, training an Active Learning classifier, or other types of investigative work. We do advise that you proceed with caution, and ensure that you are not misrepresenting your data when you conduct such a workflow.