






Project Validation statistics
Please note: For the initial Server 2022 release, the only available project validation type was Elusion Only. The Elusion with Recall validation type, which provides richness, recall, and precision statistics, is now available as part of the Server 2022 installation files.
-
To install the Elusion with Recall feature, visit the Community site for the Relativity Server 2022 GA installation files and follow the instructions for Relativity Precision, Richness, and Recall in Active Learning.
-
For instructions specific to the Elusion Only workflow, see Elusion Test on the Server 2021 documentation site.
Active Learning's Project Validation feature provides four metrics for evaluating your review coverage. Together, these metrics can help you determine the state of your Active Learning project. Once you have insight into the accuracy and completeness of your relevant document set, you can make an educated decision about whether to stop the Active Learning workflow or continue review.
For instructions on how to run Project Validation, see Project Validation and Elusion Testing.
See these related pages:
Project Validation Strategies in Active Learning webinar
Defining elusion, richness, recall, and precision
Project Validation centers around four statistics, which are defined as follows:
- Elusion rate - the percentage of documents coded relevant in the uncoded, low-ranking portion of the sample. The elusion rate results are displayed as a range that applies the margin of error to the sample elusion rate, which is an estimate of the discard pile elusion rate. The rate is rounded to the nearest hundredth of a percent.
- Richness - the percentage of relevant documents across the whole sample. This is calculated by dividing the number of positive-coded documents in the sample by the total number of documents in the sample. This allows us to predict a richness range for the whole project.
- Recall - the percentage of truly positive documents which were found by the Active Learning process. A document has been "found" if it was previously coded positive, or if it is uncoded with a rank at or above the cutoff. Documents that were predicted negative but coded positive during validation will count against recall.
- Precision - the percentage of found documents which are truly positive. A document has been “found” if it was previously coded positive, or if it is uncoded with a rank at or above the cutoff. Documents that were predicted positive but coded negative during validation will count against precision.
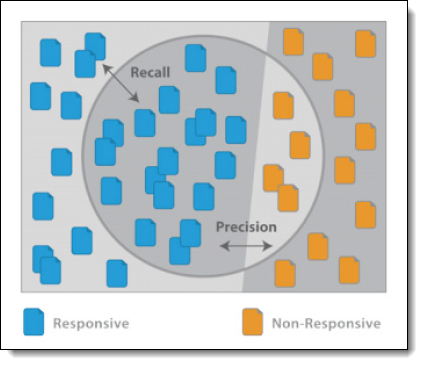
Project Validation arrives at these values through its determination of true and false positives, as well as false negatives:
- True Positive - predicted relevant by the system and confirmed relevant during validation
- False Positive - predicted relevant by the system but coded not relevant during validation
- False Negative - predicted not relevant by the system but coded relevant during validation
For each of these metrics, Project Validation assumes that you will trust the human coding decisions over machine predictions, and that the prior coding decisions are correct. It does not second-guess human decisions.
Note: Project Validation does not check for human error. We recommend that you conduct your own quality checks to make sure reviewers are coding consistently. For more information, see Quality checks and checking for conflicts.
How Project Validation metrics are calculated
The Project Validation metrics center around two types of information:
-
Errors (false negatives and false positives) - these are measured by elusion, recall, and precision.
-
Percentage of relevant documents - this is measured by richness.
Each metric frames its information somewhat differently, depending on the numerator and denominator. In order to understand these differences, we can visualize them using the document groups defined below.
Document groups used for calculations
All documents in an Active Learning project can be categorized into the following four groups:

-
Documents which are coded not relevant
-
Documents which are coded relevant
-
Documents which are not coded, and predicted not relevant
-
Documents which are not coded, and predicted relevant
For the purposes of this explanation, we will refer to these groups as buckets.
A Project Validation sample contains documents from each bucket, and the proportions of the sample will roughly match the proportions of the population. For example, if 50% of your population falls into bucket 3, then the sample will also have roughly 50% of its documents drawn from bucket 3. In rare cases where the sample size is extremely small, such as 10 documents, or if almost no documents have been coded, then not all buckets may be represented.
Note: These buckets are determined by a document's status at the start of Project Validation. For the purpose of these calculations, documents do not "switch buckets" during the course of validation.
Calculating the metrics based on document group
Using samples of the "buckets" of documents defined above, each of the Project Validation metrics can be calculated as follows:
-
Elusion: Samples bucket 3
-
Richness: Samples buckets 1, 2, 3, and 4
-
Recall: Samples buckets 2, 3, and 4
-
Precision: Samples buckets 2 and 4
Elusion rate

Elusion = (Relevant documents in bucket 3) / (All documents in bucket 3)
Elusion measures the "error rate of the discard pile" — meaning, the relevant document rate in bucket 3. Documents which were coded relevant before starting project validation are not included in the calculation, regardless of their rank score.
Richness

Richness = (Bucket 2 + any relevant documents found in buckets 3 and 4) / (All buckets)
Richness measures the overall relevance rate of all documents in the project. As an Active Learning project progresses, these relevant documents will be found in different buckets, but the overall percentage of relevant documents remains the same.
Recall

Recall = (Bucket 2 + relevant documents in bucket 4) / (Bucket 2 + relevant documents in buckets 3 and 4)
Recall measures the percentage of truly positive documents which were found by the Active Learning process. It is one of the most widely used metrics, but it is also the most complicated of the four to calculate. Unlike the other three metrics, it does not use complete buckets in the denominator, which makes it harder to visualize.
Recall shares a numerator with the precision metric, but the denominators are different. In recall, the denominator is "what is truly relevant;" in precision, the denominator is "what we are producing."
Precision

Precision = (Bucket 2 + relevant documents in bucket 4) / (All documents in buckets 2 and 4)
Precision measures the accuracy of what you're planning to produce. Unlike recall, it does not consider the low-ranking documents from bucket 3 that would be left out of a production.
Because bucket 2 grows larger and bucket 4 grows smaller as documents are coded, the precision rate will grow higher throughout the life of the project. Whenever you use the precision metric, remember that it considers all coded documents to be coded correctly. It does not account for possible human error.
How the Project Validation queue works
Once you start Project Validation, the system puts all sampled documents from buckets 3 and 4 into the queue for reviewers to code. This is the key to measuring Active Learning's predictions against human decisions. Documents which are coded during project validation do not switch buckets during the validation process; documents which started in buckets 3 and 4 are still considered part of 3 and 4 until validation is complete. This allows the system to keep track of correct or incorrect predictions when calculating metrics, instead of lumping all coded documents in with those which were previously coded.
For an explanation of the document "buckets," see Document groups used for calculations.
How the Project Validation sample is selected
Because all four metrics have different denominators, they all have different confidence intervals. Instead of selecting every single confidence interval and margin of error for your sample, Active Learning offers two simplified options which center around the elusion metric.
For an explanation of the document "buckets," see Document groups used for calculations.
Option 1: Fixed
When you choose the fixed sample size, you enter the total number of documents you want drawn for the sample. The setup window will calculate what percentage of that is being drawn from bucket 3, then estimate your elusion margin of error based on that. This estimated margin of error may change slightly once the true sample elusion rate has been measured during validation.
Option 2: Statistical
When you choose the statistical sample size, you enter the confidence level and margin of error you want for the elusion metric. The setup window will calculate how many sample documents to draw from bucket 3 for the elusion metric. If you chose Elusion with Recall, it will then calculate how many additional documents are needed to keep the other sampled buckets in proportion with bucket 3.
How Project Validation handles skipped documents
We strongly recommend coding every document in the Project Validation queue. Skipping documents lowers the randomness of the random sampling, which introduces bias into the validation statistics. To counter this, Active Learning gives conservative estimates. Each validation statistic counts a skipped document as an unwanted result.
The following table shows how skipped documents negatively affect each statistic.
| Skipped Document | Effect on Elusion | Effect on Recall | Effect on Richness | Effect on Precision |
|---|---|---|---|---|
| Low-ranking |
Increases elusion rate (Counts as relevant) |
Lowers recall rate (Counts as non-relevant) |
Raises richness estimate (Counts as relevant) |
(No effect) |
| High-ranking |
(No effect) |
Lowers recall rate slightly (Counts as if it weren't present) |
Raises richness estimate (Counts as relevant) |
Lowers precision rate (Counts as non-relevant) |
Documents skipped during Prioritized or Coverage Review
If a document was skipped during Prioritized Review or Coverage Review and is then served and coded during Project Validation, it will be designated as a coded document rather than a skipped document in that queue's Review Statistics tab.