






Feedback
Analytics indexes
Unlike traditional searching methods like dtSearch, Analytics is an entirely mathematical approach to indexing documents. It doesn’t use any outside word lists, such as dictionaries or thesauri, and it isn’t limited to a specific set of languages. Unlike textual indexing, word order is not a factor.
The basis of conceptual analytics and Active Learning is an Analytics index. There are two types of indexes:
- Conceptual - uses Latent Semantic Indexing (LSI) to discover concepts between documents. This indexing process is based solely on term co-occurrence. The language, concepts, and relationships are defined entirely by the contents of your documents and learned by the index. For more information, see Analytics and Latent Semantic Indexing (LSI).
- Classification - uses coded examples to build a Support Vector Machine (SVM) to predict a document's relevance. This index is used solely by the Active Learning application. Classification indexes learn how terms are related to categories based on the contents of your documents and coding decisions made within the Active Learning project. For more information, see Analytics and Support Vector Machine learning (SVM).
The searchable set and training set used for Analytics index creation are now referred to as the data source and training data source. See Creating an Analytics index.
You can run the following Analytics operations on documents indexed by a conceptual index:
Analytics and Latent Semantic Indexing (LSI)
LSI is a wholly mathematical approach to indexing documents. Instead of using any outside word lists, such as a dictionary or thesaurus, LSI leverages sophisticated mathematics to discover term correlations and conceptuality within documents. LSI is language-agnostic, meaning that you can index any language and it learns that language. LSI enables Relativity Analytics to learn the language and, ultimately, the conceptuality of each document by first processing a set of data called a training data source. The training data source may be the same as the set of documents that you want to index or categorize. Alternatively, it may be a subset of these documents, or it could be a completely different set of documents. This training data source is used to build a concept space in the Analytics index.
Using LSI, Analytics inspects all the meaningful terms within a document and uses this holistic inspection to give the document a position within a spatial index. The benefits of this approach include the following:
- Analytics learns term correlations (interrelationships) and conceptuality based on the documents being indexed. Therefore, it always is up-to-date in its linguistic understanding.
- Analytics indexes are always in memory when being worked with, so response time is very fast.
- Analytics is inherently language agnostic. It can index most languages and accommodate searches in those same languages without additional training. We recommend creating separate indexes for large populations of different language documents.
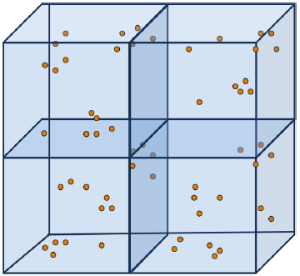
Concept space
When you create an Analytics index, Relativity uses the training data source to build a mathematical model called a concept space. The documents you are indexing or categorizing can be mapped into this concept space. While this mathematical concept space is many-dimensional, you can think of it in terms of a three-dimensional space. The training data source enables the system to size the concept space and create the algorithm to map searchable documents into the concept space. In the concept space, documents that are closer together are more conceptually similar than documents that are further from each other.
Concept rank
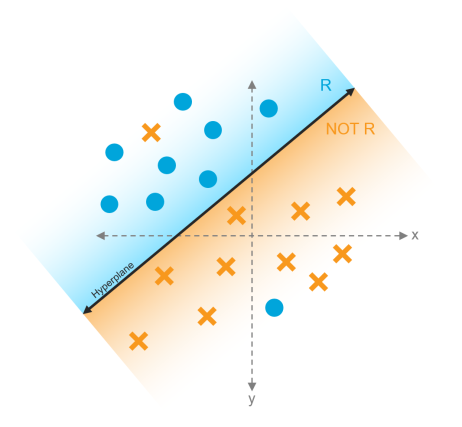
Throughout Analytics, item similarity is measured using a rank value. Depending on the feature, the rank may be referred to as a coherence score, rank, or threshold. In each scenario, the number represents the same thing.
Because the Analytics engine builds a spatial index, every document has a spatial relationship to every other document. Additionally, every term has a spatial relationship to every other term.
The concept rank is an indication of distance between two items. In the Categorization feature, it indicates the distance between the example document and the resulting document. In Keyword Expansion, it indicates the distance between the two words. The rank does not indicate a percentage of relevance.
For example, when running a concept search, the document that is closest to the query is returned with the highest conceptual score. A higher score means the document is more conceptually related to the query. Remember that this number is not a confidence score or a percentage of shared terms, it is a measurement of distance.
Analytics and Support Vector Machine learning (SVM)
SVM is used solely by Active Learning. With SVM, you don't need to provide the Analytics index with any training text. The system learns from your reviewers and constantly updates the model. SVM predicts the relevance of uncoded documents based on their distance to the hyperplane. This differs from Latent Semantic Indexing (LSI) which is also composed of a multi-dimensional space, but uses a nearest-neighbor approach to predict documents.
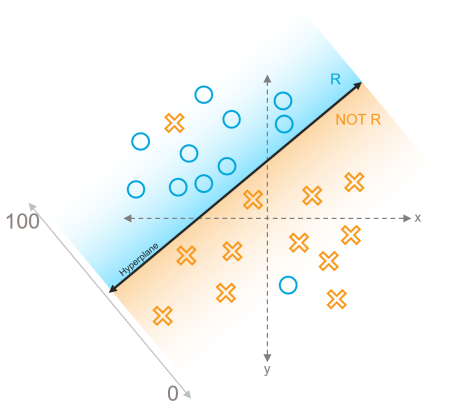
Hyperplane
When you create a Classification-type index, Relativity takes reviewer's coding decisions and pulls them into a high-dimensional model. The hyperplane helps differentiate between relevant and not relevant documents.
After the hyperplane is established, all documents without a coding decision are pulled into the model and mapped on either side of the hyperplane based on the model's current understanding of the difference between relevant and not relevant.
Rank
Rank measures the strength or confidence the model has in a document being relevant or not relevant. Rank is measured on a scale from 100 to 0. As documents move farther away from the hyperplane on either side, their score is pushed closer to 100 or 0.
Creating an Analytics index
Analytics uses only the documents you provide to make a search index. Because no outside word lists are used, you must create saved searches to dictate which documents are used to build the index. However, if you want to limit search results to certain document groups or have more than one language in the document set, multiple indexes might give you better results.
Permissions for the Search Index object must be kept in sync with permissions on the Analytics Index object.
Conceptual index
- Click the Indexing & Analytics tab and select Analytic Indexes.
- Click New Analytics Index. The Analytics Index Information form appears.
- Complete the fields on the Analytics Index Information form. See Index creation fields. Fields in orange are required.
- Click Save.
If no documents appear in the saved search, or if the search contains fields other than the extracted text field, a warning message appears upon clicking Save.
When you save the new index, the Analytics Index console becomes available. See Analytics index console operations.

Index creation fields
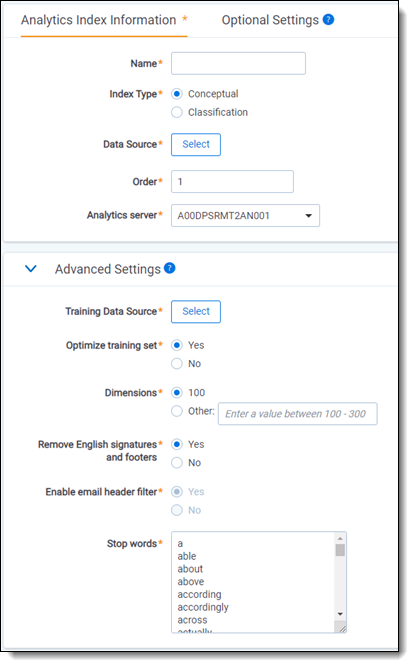
The Analytics Index Information form contains the following fields:
Index Information fields
- Name - the name of the index. This value appears in the search drop-down menu after you activate the index.
- Index type - select Conceptual.
- Data source - the document set searched when you use the Analytics index. This set should include all of the documents on which you want to perform any Analytics function. Only documents included in the data source are returned when you run clustering, categorization, or any other Analytics feature. See Data source considerations for more information on creating an optimized data source search.
- Cluster Documents - when checked, this automatically creates a cluster for all indexed documents after the index has been built. This option is set to Yes by default.
- Yes - creates a conceptual cluster for all documents included in the index. For more information, see Default settings for automatically created clusters.
- No - no cluster is created when the index builds, but you can still create a cluster manually at any time. For more information, see Clustering.
- Order - the number that represents the position of the index in the search drop-down menu. The lowest-numbered index is at the top. Items that share the same value are sorted in alphanumeric order.
- Analytics server - select the Analytics server that should be associated with the Analytics index.
- Email notification recipients (under Optional Settings) - send email notifications when your index successfully completes, fails, or when the index is disabled because it is not being used. Enter the email address(es) of the recipient(s). Separate entries with a semicolon. A message is sent for both automated and manual index building.
Advanced Settings fields
- Repeated content filters to link - the number of repeated content filters to link to the index. When the index runs, it will automatically link the top filters found in the Repeated Content Filters tab, sorted in descending order by number of occurrences times word count. For more information, see Automatically linking repeated content filters.
- The default value is 200; the maximum value is 1000. If you also have manually linked filters, those count towards the maximum of 1,000.
- In order for this setting to take effect, you must have either a structured analytics set with repeated content identification, or manually created repeated content filters. For information on creating these, see Repeated content filters.
- Training data source - the document set from which the Analytics engine learns word relationships to create the concept index. By default, this is the same saved search as the data source. See Training data source considerations for more information including considerations when using Data Grid.
- Optimize training set - when checked, this specifies whether the Analytics engine automatically includes only conceptually valuable documents in the training data source while excluding conceptually irrelevant documents. Enabling this eliminates the need to manually remove bad training documents from the training data source.
- Yes - includes only quality training documents in the training data source. For more information, see Optimize training set.
- No - puts all documents from the saved search selected for the Training data source field into the training data source without excluding conceptually-irrelevant documents.
- Dimensions - determines the dimensions of the concept space into which documents are mapped when the index is built; more dimensions increase the conceptual values applied to documents and refine the relationships between documents. The default setting is 100 dimensions.
A larger number of dimensions can lead to more nuances due to more subtle correlations that the system detects between documents. However, h
- Remove English email signatures and footers—removes signatures and footers from emails containing English characters only. By default, this is set to Yes for new indexes and No for existing ones. Enabling this tells the Analytics engine to auto-detect and ignore email confidentiality footers and signatures. This helps the index focus on authored content.
- This process can slow down index population, but we strongly recommend leaving it set to Yes.
- Setting this to No makes it possible to turn off the Enable email header filter setting.
- Enable email header filter—removes common header fields, such as To, From, and Date, and reply-indicator lines. It does not remove content from the Subject line or the attachment header. This helps the index focus on authored content instead of making unhelpful correlations among standard words such as To or From.
- By default, this is set to Yes. We recommend keeping this filter set to Yes on all indexes.
- To set this option to No, you must set Remove English email signatures and footers to No.Relativity recognizes words as being part of the email header only when they are at the beginning of a new line and followed by a colon. The email filter also filters out subsequent lines, but only if the new line begins with white space. For example, if the email contains a BCC section that is multiple lines, each subsequent line would have to begin with a space, otherwise it is not filtered out.
- Stop words—determines the words you want the conceptual index to suppress. You can add or remove stop/noise words from the list. Separate each word with a hard return. If you modify this list after the index builds, you will need to re-build the index.
Stop/noise words are common terms that are filtered from the Analytics index in order to improve quality. By default, this field contains only English words. If you are indexing documents in another language, you can customize the list to include words in the language you want. For multiple languages, we recommend creating multiple indexes in the workspace template for each commonly indexed language. These indexes are copied over to any new workspace that uses that template.
To create a stop/noise word list in another language, there are several options:- Translating the English stop/noise words list to the desired language manually.
- Ranks NL (http://www.ranks.nl/stopwords) - 40 languages are available.
- Microsoft SQL Server Stop Lists
- 33 languages are available. Use the following query:Copy
SELECT LCID, Name FROM sys.syslanguages
SELECT * FROM sys.fulltext_system_stopwords WHERE language_id = ####
Classification index
Classification indexes are used only by Active Learning projects.
- Click the Indexing & Analytics tab and select Analytic Indexes.
- Click New Analytics Index. The Analytics Index Information form appears.
- Complete the fields on the Analytics Index Information form. See Index creation fields. Fields in orange are required.
- Click Save.
If no documents appear in the saved search, or if the search contains fields that would cause the index to error, a warning message appears upon clicking Save.
When you save the new index, the Analytics Index console becomes available. See Analytics index console operations.
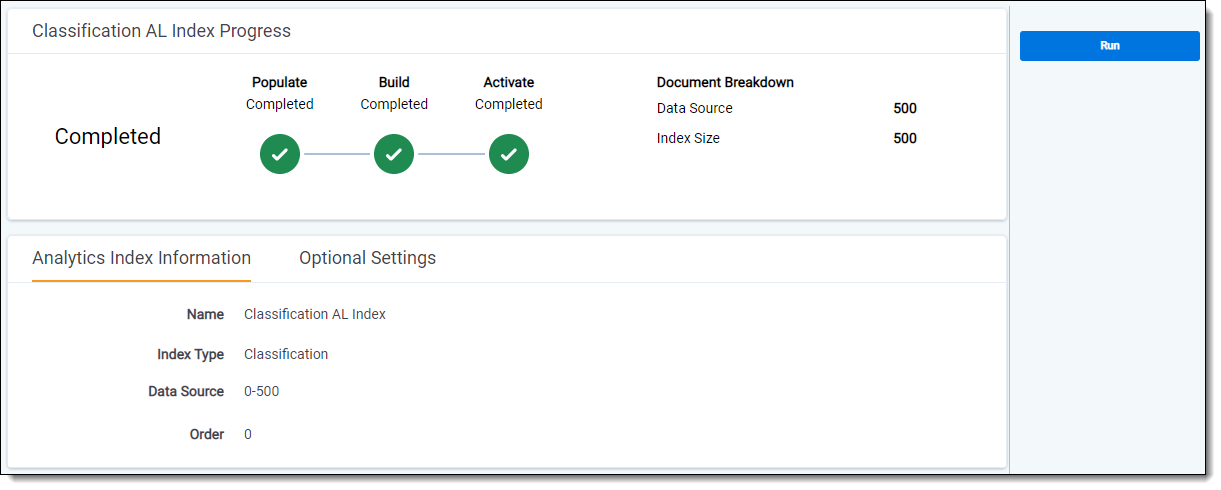
Index creation fields
The Analytics Index Information form contains the following fields:
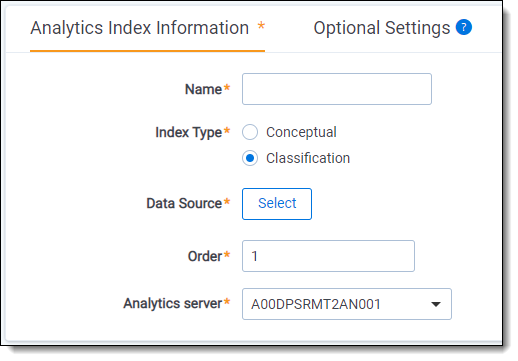
Index Information fields
- Name - the name of the index. This value appears in the search drop-down menu after you activate the index.
- Index type - select Classification.
- Data source - the document set searched when you use the Analytics index. This set should include all of the documents on which you want to perform any Analytics function. Only documents included in the data source are returned when you run clustering, categorization, or any other Analytics feature. See Data source considerations for more information on creating an optimized data source search.
- For best results, we recommend no more than 9 million documents in the data source.
- If you want to use family-based review in Active Learning, parent documents and their family must all be added to the data source.
- Order - the number that represents the position of the index in the search drop-down menu. The lowest-numbered index is at the top. Items that share the same value are sorted in alphanumeric order.
- Analytics server - select the Analytics server that should be associated with the Analytics index.
- Email notification recipients (under Optional Settings) - send email notifications when your index successfully completes, fails, or when the index is disabled because it is not being used. Enter the email address(es) of the recipient(s). Separate entries with a semicolon. A message is sent for both automated and manual index building.
Securing an Analytics index
If you want to apply item-level or workspace-level security to an Analytics index, you must secure both the Analytics Index object and the Search Index object for that particular index.
Restricting a group from viewing an Analytics Index does not restrict them from searching on the index unless access to the corresponding Search Index is also restricted.
If you’re applying item-level security from the Search Indexes tab, you may need to create a new view and add the security field to the view.
Data source and training data source considerations
Training data source considerations
Training data source considerations only apply to conceptual indexes.
A training data source is a set of documents that the system uses to learn the language, the correlation between terms, and the conceptual value of documents. This data source formulates the mapping scheme of all documents into the concept space. Because the system uses this data source to learn, include only the highest quality documents when creating the training data source. The system needs authored content with conceptually relevant text to learn the language and concepts.
Use the following settings when creating a saved search to use as a training data source:
- Only the authored content of the document should be indexed. Typically, the Extracted Text field is the only field returned as a column in a data source. If there is authored content in another long text field (i.e., OCR Text, Translation, etc.), then this field should be included as well. You should never train on any sort of metadata fields like Custodian or Email Author or system fields like Control Number. Including these fields skews your results when trying to find conceptually related documents.
Do not index single choice, multiple choice, multiple object, or any number fields, such as Extracted Text Size.
- Documents that don't contain authored content or conceptual data are useless for training the Analytics index. The following types of documents should be excluded from the training data source:
- Compressed files (like ZIP or RAR files)
- System files
- Excel files with mostly numbers
- Image files
- CAD drawings
- Maps
- Calendar items
- Documents with OCR errors, such as OCR not processed
- Documents with poor quality OCR, such as OCR on handwritten documents.
- Documents with little or no text (less than 0.2 KB)
- During population, words beginning with a number are not included in the index (ex. 4ward). Words ending in a number (mp3) or with numbers embedded (passw0rd) are indexed as written.
Optimize training set
When you select the Optimize training set feature on an Analytics index, you improve the quality of that index by excluding documents that could result in inaccurate term correlations due to their low conceptual value, such as:
- Very short documents
- Very long documents
- Lists containing a significant amount of numbers
- Spreadsheet-like documents
- System log files
- Text resulting from processing errors
To perform this automatic removal of bad documents from the training data source, the Analytics engine evaluates documents based on:
- Word count
- Uniqueness
- Number count
- Punctuation marks
- Words with many characters (50+)
If the optimization excludes a document, the following results are possible:
- If the document is designated to be populated as both a training and searchable document, Relativity populates it as a searchable document only. The document could be returned in a concept search, assuming it meets the minimum rank.
- If the document is designated to be populated only as a training document, Relativity doesn't populate it into the index at all.
- If the document is designated to be populated as a searchable document only, the Analytics engine doesn't examine it.
Data source considerations
For conceptual indexes, the data source is the collection of documents to be clustered, categorized, or returned in a concept query. The data source is typically larger than the training data source. There are fewer documents culled from the data source.
For classification indexes, the data source is the collection of documents to be ranked by the Active Learning model. The data source must contain example documents to train the model.
Use the following settings when creating a saved search to use as a data source:
- Index only the authored content of the document. We recommend returning as few fields as possible. Typically, the Extracted Text field is the only field returned as a column in a data source. If there is authored content in another long text field (i.e., OCR Text, Translation, etc.), include this field as well. Returning email header fields in your search may cause recipient names and email address components to appear in clusters.
Do not index single choice, multiple choice, multiple object, or any number fields, such as Extracted Text Size.
- Documents that don't contain any conceptual data cannot be returned by any conceptual analytics operations. Consider excluding the following types of documents from the data source:
- Compressed files (like ZIP or RAR files)
- System files
- Excel files with mostly numbers
- Image files
- CAD drawings
- Maps
- During population, words beginning with a number are not included in the index (ex. 4ward). Words ending in a number (mp3) or with numbers embedded (passw0rd) are indexed as written.
Analytics indexes automatically suppress documents larger than 30 MB before sending them to the Analytics engine, so removing these yourself is not required. However, because the suppression process takes time, removing them in advance can make an index build more quickly. Removing other large, non-conceptual files such as number-heavy Excel files gives the same benefit.
Identifying data source and training data source documents
When you populate the index, the Conceptual Index multi-choice field on the Document object lists whether a document is included in the data source, training data source, or both. This field is populated every time the index is populated with a full or incremental population. You can use this field as a condition in a saved search to return only training or data source documents.
You can also find data source and training data source documents in the field tree, as well as those which were excluded from training when you enabled the Optimize training set field on the index.
Index and document size limits
Index sizes are limited by default, and some large documents are excluded from indexing as follows.
Index size limits
By default, indexes are limited by the following parameters:
-
Indexes can include up to 12 million documents each.
-
Conceptual indexes can reach up to 60 GB in size.
These limits can be changed by the administrator. For help with adjusting index size limits, contact Relativity Support.
Document size limits
Analytics indexes automatically suppress documents larger than 30 MB before sending them to the Analytics engine. Suppressed large documents will appear in the Document Exceptions. You can also view suppressed documents from the Document list by using the Excluded from Training and Excluded from Searchable Set choices on the Analytics Index Document field.
Analytics index console operations
Once you save the Analytics index, the Analytics index console appears. From the Analytics index console, you can perform the following operations:
- Populating the index
- Monitoring population/build status
- Retrying exceptions
- Viewing conceptual index document exceptions
- Showing population statistics
- Showing index statistics
Population statistics and index statistics are only available for conceptual indexes.
Populating the index
To populate the Analytics index on the full set of documents, click Run on the Analytics Index console, then choose Full from the modal that appears. This adds all documents from the data source and training data source to the ready-to-index list. Document “preprocessing” also occurs to clean up text. This includes the following:
- Numbers and symbols are ignored.
- All words are made lowercase.
- Filters found under Advanced Settings are applied (for example, email header filter).
Once population is complete, the index builds.
If you have access to SQL, you can change the priority of any Analytics index-related job (index build, population, etc.) by changing the value on the Priority column in the ContentAnalystIndexJob database table for that index. This column is null by default, null being the lowest priority. The higher you make the number in the Priority column, the higher priority that job becomes. When you change the priority of a job while another job is in progress, Analytics doesn't stop the in-progress job. Instead, the job will finish before starting on the new highest priority.
Canceling population
While the index is populating, the following console option becomes available:
- Cancel - cancels a full or incremental population. Canceling population requires you to perform a full population later. After you click this button, any document with a status of Populated is indexed. After the indexing of those documents is complete, population stops, leaving an unusable partial index. To repair the index, perform a Full Population to purge the existing data. You can also delete the index from Relativity entirely.
Incremental population
Once population is complete, you have the option to populate incrementally to account for new or removed documents from the data source and training data source on the ready-to-index list. To perform an incremental build, click Run on the console, then choose Incremental from the modal that appears. See Incremental population considerations for conceptual indexes for more information.
- If, after building your index, you want to add any documents that were previously excluded from training back into the training data source document pool, you must disable the Optimize training set field on the index and perform another full population. An incremental population does not re-introduce these previously excluded documents.
- Incremental population automatically triggers a rebuild of the classification index.
Building the index
Once population is complete, the index will build automatically. During this phase, training data source documents and Latent Semantic Indexing (LSI) are used to build the concept space based on the relationships between words and documents. Data source documents are mapped into the concept space, and stop/noise words (very common words) are filtered from the index to improve quality.
Please note that the index is unavailable for searching during this phase.
Monitoring population/build status
You can monitor the progress of any Analytics index process with the progress panel at the top of the layout.
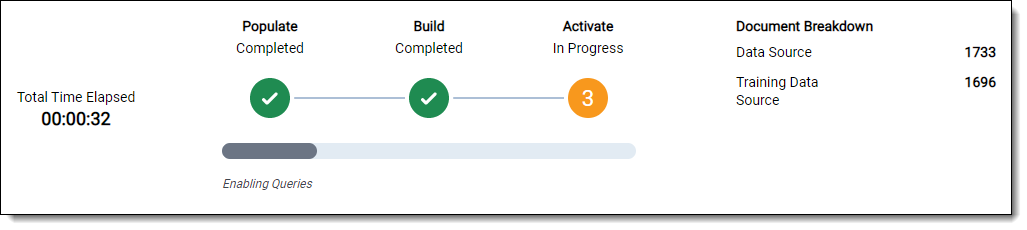
(Click to expand)
Population and index building occurs in the following stages, which will appear within the progress panel:
- Step 0 of 3 – Waiting – Indexing Job in Queue
- Step 1 of 3 – Populating
- Constructing Population Table
- Populating
- Step 2 of 3 – Building
- Preparing to build
Building
- Starting
- Copying item data
- Feature weighting
- Computing correlations
- Initializing vector spaces
- Updating searchable items
- Optimizing vector space queries
- Finalizing
- Step 3 of 3 – Activating
- Preparing to Enable Queries
- Enabling Queries
- Activating
Document breakdown fields
The following fields appear in the Document Breakdown section:
- Data Source - the number of indexed data source documents.
- Training Data Source - the number of indexed training data source documents.
If an Analytics index goes unused for 15 days, it is automatically disabled to conserve server resources. It then has a status of Inactive and is not available for use until it is activated again. This setting is determined by the
Activating the index
Building a conceptual index automatically activates it. This makes the index available for users by adding the index to the search drop-down menu on the Documents tab and to the right-click menu in the viewer. All active indexes are searchable.
Activating an index loads the index's data into RAM on the Analytics server. Enabling a large number of indexes at the same time can consume much of the memory on the Analytics server, so you should typically only leave indexes active that are actively querying or classifying documents.
Deactivating the index
Once a conceptual index is activated, you have the option of deactivating it.
You may need to deactivate an index for the following reasons:
- You need to shut the index down so it doesn't continue using RAM.
- The index is inactive but you don't want to completely remove it.
To deactivate an index, click Deactivate Index on the console. A yellow banner will appear at the top of the console.
To reactivate the index, click Reactivate Index on the banner.
If you deactivate an index, you can't run concept searches against the index and keyword expansion becomes unavailable on the index.
Retrying exceptions
If index-level exceptions occur while populating or building a classification index, you have the option of retrying them from the console. To do this, click Retry Exceptions.
If exceptions occur while populating or building a conceptual index, the system will retry them automatically.
Retrying exceptions attempts to populate the index again.
You can only populate one index at a time. If you submit more than one index for population, they'll be processed in order of submission by default.
Viewing conceptual index document exceptions
When errored documents are removed from population in a conceptual index, they appear on the index console in the Document Exceptions panel. This panel only appears when exceptions exist.

The panel includes the following fields:
- ArtifactID - the artifact ID of the document that received the error.
- Message - the system-generated message accompanying the error.
- Status - the current state of the errored document. The possible values are:
- Removed From Index - indicates that the errored document was removed from the index.
- Included in Index - indicates that the errored document was included in the index because you didn't select the option to remove it.
- Date Removed - the date and time at which the errored document was removed from the index.
Showing population statistics
To see a list of population statistics, click Show Population Statistics.
Population statistics are only available for conceptual indexes.
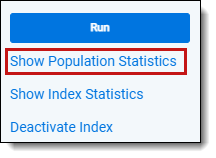
This option is available immediately after you save the index, but all rows in this window display a value of 0 until population is started.
This displays a list of population statistics that includes the following fields:
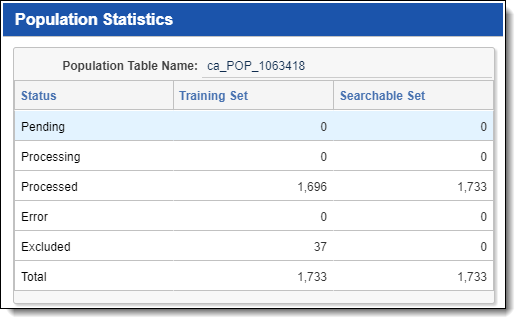
- Status - the state of the documents included in the index. This contains the following values:
- Pending - documents waiting to be included in either population or index build.
- Processing - documents currently in the process of being populated or indexed.
- Processed - documents that have finished being populated or indexed.
- Error - documents that encountered exceptions in either population or index build.
- Excluded - excluded documents that were removed from the index as per the Optimize training set field setting or by removing documents in error.
- Total - the total number of documents in the index, including errored documents.
- Training Set - documents designated for the training data source that are currently in one of the statuses listed in the Status field.
- Searchable Set - documents designated for the data source that are currently in one of the statuses listed in the Status field.
Showing index statistics
To see an in-depth set of index details, click Show Index Statistics. This information can be helpful when investigating issues with your index.
Index statistics are only available for conceptual indexes.
Clicking this displays a view with the following fields:
- Build Completed Date - the date and time at which the index was built.
- Item Last Added Date - the date and time at which the most recent item was added.
- Dimensions - the number of concept space dimensions specified by the Analytics profile used for this index.
- Integrated dtSearch Enabled - whether or not dtSearch was used to assist document validation.
- Index ID - the automatically generated ID created with a new index.
- Unique Words in the Index - the total number of words in all documents in the training data source, excluding duplicates. If a word occurs in multiple documents or multiple times in the same document, it's only counted once.
- Searchable Documents - the number of documents in the data source, determined by the saved search you selected in the Data Source field when creating the index.
- Training Documents - the number of documents in the training data source, determined by the saved search you selected for the Training Data Source field when creating the index. The normal range is two-thirds of the data source up to five million documents, after which it is half of the data source. If this value is outside that range, you receive a note next to the value.
- Unique Words per Document - the total number of words, excluding duplicates, per document in the training data source. The normal range is 0.80 - 10.00. If this field shows a value lower or higher than this range, a note appears next to the value. If your dataset has many long technical manuals, this number may be higher for your index. However, a high value might also indicate a problem with the data, such as poor quality OCR.
- Average Document Size in Words - the average number of words in each document in the training data source. The normal range is 120-200. If this field displays a value lower or higher than this range, you receive a note next to the value. If the data contains many very short emails, or errors in the extracted text field, the number might be smaller than usual. If the saved search did not return long text fields, you may also see a value below the normal range. If it contains long documents, the number could be higher than usual. If this number is extremely low (under 10), it's likely the data sources for the index were set up incorrectly.
Best practices for updating a conceptual index
There may be times when you need to update your index. Depending on the update you’re making, you can save time by running an incremental population or only running a build. The following table outlines various workflows for different index updates.
| Workflow | Index update |
|---|---|
|
Adding new documents that:
|
|
|
Adding new documents that:
|
|
| Removing documents from the data source or training data source |
|
| Updating stop/noise words |
|
| Updating extracted text (ex. Updating poor quality OCR text) |
|
| Updating filters (email header, repeated content) |
|
Incremental population considerations for conceptual indexes
Incremental populations don't necessarily force Analytics to go through every stage of an index build.
When managing or updating indexes with new documents, consider the following guidelines:
- Quantity - If your index has 1 million records and you're adding 100,000 more, those documents could potentially teach a substantial amount of new information to your index. In this instance, you would update both the data source and training data source. However, if you were only adding 5,000 documents, there aren’t likely a lot of new concepts in relation to the rest your index. You would most likely only need to add these new documents to your data source.
- Subject matter - If the newly imported data is drastically different from the existing data, you need to train on it. If the new data is similar in nature and subject matter, then it would likely be safe to only add it to the data source.
You can run an incremental population to add or remove documents from your data source and training data source. This results in an index taking substantially less time to build, and therefore less downtime.
To perform an incremental population, click Run on the console, then choose Incremental from the modal that appears. This checks for changes in both the data source and training data source and updates the index to match.
If extracted text has changed, you have updated the stop/noise words, or you have applied different filters, you must run a full population.
Linking repeated content filters to a conceptual index
Repeated content filters can be linked to an Analytics index either automatically, using the top filters chosen by the system, or by manually selecting individual filters. These linked filters will only apply to the currently open Analytics conceptual index; they will not be applied to structured analytics sets. These can only be linked to conceptual indexes, not classification indexes.
The maximum number of linked repeated content filters per index is 1,000. This includes both manually and automatically linked filters.
Automatically linking repeated content filters
By default, when a conceptual index runs, it will automatically link the top 200 repeated content filters to the index. These are chosen by multiplying the number of occurrences times word count, then selecting the top 200 in descending order.
The following settings apply when automatically linking repeated content filters:
-
The default number of linked filters is 200, and this number is controlled by the Repeated content filters to link field on the index creation screen. You can change this to any number from 0 to 1000 (inclusive) when you create the index. For more information, see Index creation fields.
-
If a repeated content filter has the Ready to index field set to No, it will be excluded from linking to the index, even if it would otherwise be counted as a top filter.
-
If a repeated content filter has the Ready to index field set to Yes, it will be included as an automatically linked filter, even if it is not a top filter according to the calculation. It will count towards the number of filters set in the Repeated content filters to link field. For example, if the Repeated content filters to link field is set to 200, and there are 5 low-ranked filters which have Ready to index set to Yes, the index will link those 5 plus the top 195 filters for a total of 200.
-
The linking process takes place every time the conceptual index runs. This means that if some repeated content filters are deleted, or if the Ready to index field values change, these changes will be reflected after the next index re-run.
If a conceptual index has both manually and automatically linked filters attached, the manually linked ones will not be changed by the index re-runs and will remain linked. Manually linked filters do not count towards the number in the Repeated content filters to link field, but they do count towards the 1,000 filter maximum.
Manually linking repeated content filters
Use the Repeated Content Filters section on an Analytics index layout to manually link repeated content filters when the Analytics index is not open in Edit mode.
To manually link one or more existing repeated content filters to an Analytics index, perform the following steps:
- Click on the Repeated Content Filters tab in the bottom panel of the console.
- Click Link.
- Find and select the repeated content filter(s) to link to the profile. If you tagged the Ready to index field with Yes on filters you want to apply, filter for Ready to index = Yes to easily find your predetermined filters.
- Click Apply.
For more information on repeated content and regular expression filters, see Repeated content filters.