






Feedback
Last date modified: 2026-Feb-05
Sentiment analysis results
After you have run sentiment analysis on a set of documents, the results are available as a set of fields attached to each document. These can be viewed either from the document list page or from the Sentiment Results tab.
Similarly, information about each sentiment analysis run is recorded on the Sentiment Analysis Jobs tab. You can view all jobs together as a list, or view details of each individual job.
See these related pages:
Other related articles:
Adding results to the document view
To view results from the main document list, add sentiment analysis columns to your document view.
The following general sentiment columns are available:
- Sentiment—the name of the sentiment analysis job that contained the document.
- Sentiment::Status—status of the analysis on this document. The possible values are:
- Completed—the document has been analyzed.
- Error—an error has occurred. For troubleshooting information, see Troubleshooting sentiment analysis errors.
- Partial Error—an error occurred when analyzing the document for one or more sentiments, but the rest succeeded.
- Skipped—the document is too large to analyze or has no extracted text.
- (Blank)—the document has not yet been analyzed.
- Sentiment::Overview—shows primary sentiments contained in the document.
- Sentiment::Distribution—scores the intensity of each sentiment in the document on a scale of 1 to 5, with 5 being the most intense.
- Sentiment::Richness—the number of sentences with any predicted sentiment, divided by the total number of sentences in the document.If a sentence is predicted to have two or more sentiments, it will be counted multiple times towards the overall richness calculation. This can cause the Sentiment::Richness score to be greater than 100.
These sentiment-specific columns are also available for each sentiment that has been analyzed:
- Sentiment::[Sentiment] Top Sentences—the top 25 sentences in the document that are predicted to have this sentiment, ranked by confidence score.
- Sentiment::[Sentiment] %—the number of sentences predicted to have this sentiment, divided by the total number of sentences in the document.
- Sentiment::[Sentiment] Top Score—the confidence score of the sentence most strongly predicted to have this sentiment. This is scored on a scale of 0 to 100, with 100 being the strongest.
For more information on adding columns to a view, see Editing view information.
Filtering and sorting results
You can use the sentiment fields to quickly sort through results and find documents with the strongest or weakest sentiment predictions:
- To filter for a specific sentiment, filter the Sentiment::Distribution field to select the sentiments and intensity levels you want to view. For example, to view only documents with strong anger predictions, check the boxes for Anger - 5 and Anger - 4.
- To sort documents in order of a sentiment's prediction strength, sort on the Sentiment::[Sentiment] % field for that sentiment.
Viewing the Sentiment Analysis Jobs tab
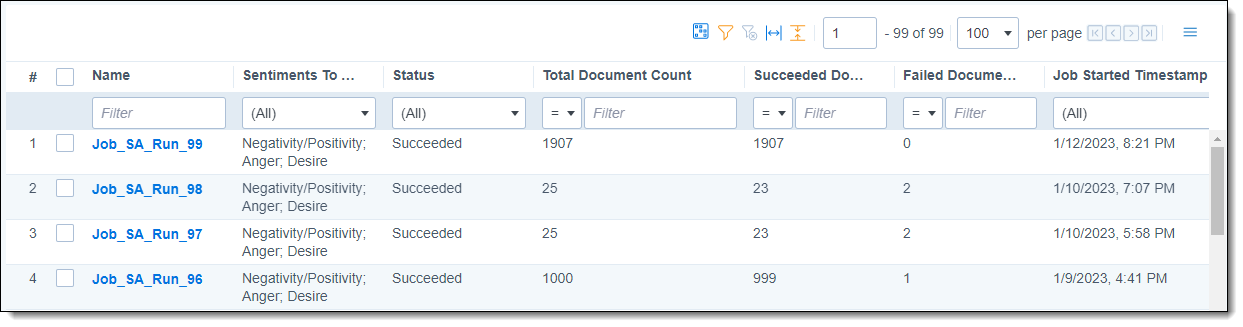
The Sentiment Analysis Jobs tab shows all jobs that have been run in the workspace.
Jobs can have the following statuses:
- New—the job has just been created.
- Running—the job is in process.
- Succeeded—the job finished successfully.
- Failed—the job failed. For troubleshooting information, see Troubleshooting sentiment analysis errors.
The columns shown in the Sentiment Analysis Jobs grid are:
- Name—the name of the job. These are formatted as Job_SA_Run_[number].
- Sentiments To Analyze—the sentiments chosen when the user set up the mass operation.
- Status—current state of the sentiment analysis job.
- Total Document Count—the total number of documents selected for analysis.
- Succeeded Document Count—the number of documents successfully analyzed.
- Failed Document Count—the number of documents where analysis failed. For troubleshooting information, see Troubleshooting sentiment analysis errors.
- Job Started Timestamp—when the job started.
- Job Finished Timestamp—when the job finished.
Viewing job details
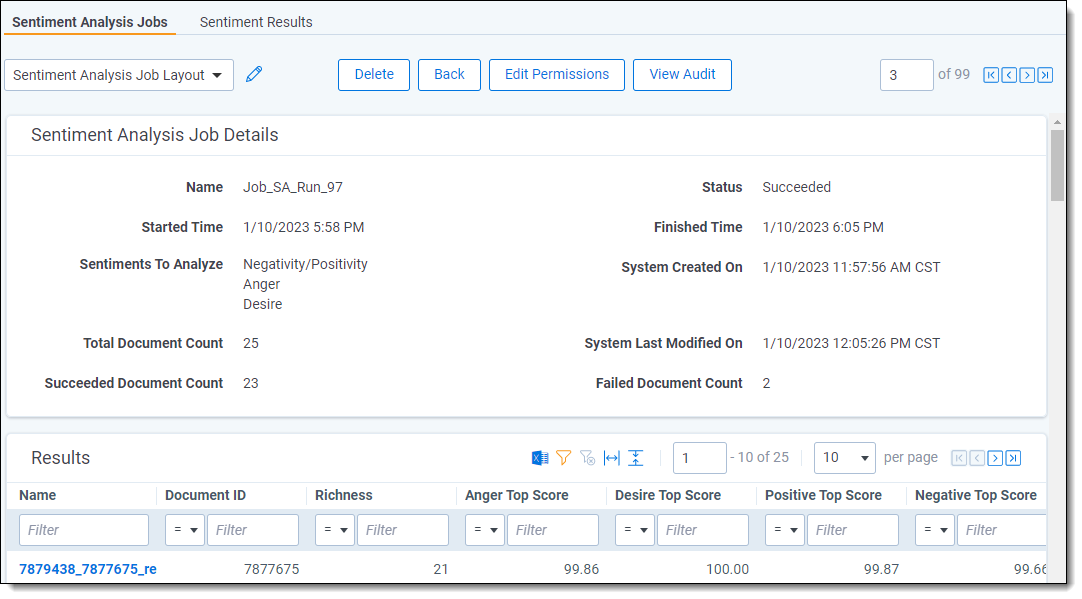
From the Sentiment Analysis Jobs tab, clicking on the name of a job brings you to a Job Details view. At the top, the page shows overall details about the run. Below that, the Results grid shows individual sentiment results per document in the run.
The buttons that are available include:
- Delete—deletes the record of this sentiment analysis job. This does not delete the sentiment scores attached to each document. If the job was in progress, deleting it cancels the job.
- Edit Permissions—opens a pop-up showing item-level security controls for this specific job run. For more information, see Security and permissions.
- View Audit—opens a pop-up showing the different stages of the analysis, their timestamps, and the user that initiated the run.
Sentiment Analysis Job Details section
The fields shown under the Sentiment Analysis Job Details section are:
- Name—the name of the job. These are formatted as Job_SA_Run_[number].
- Status—current state of the sentiment analysis job.
- Started Time—when the job started. This is the same as the Job Started Timestamp field on the Sentiment Analysis Jobs tab.
- Finished Time—when the job finished. This is the same as the Job Finished Timestamp field on the Sentiment Analysis Jobs tab.
- Sentiments To Analyze—the sentiments chosen when the user set up the mass operation.
- System Created On—the time the system created the job and queued it for processing.
- Total Document Count—the total number of documents selected for analysis.
- System Last Modified On—the most recent time that the system modified the job. Even if a job fails to finish, this can be used to see how long the job was in process.
- Succeeded Document Count—the number of documents successfully analyzed.
- Failed Document Count—the number of documents where analysis failed. For troubleshooting information, see Troubleshooting sentiment analysis errors.
Job details Results grid
The general columns shown in the Results grid are:
- Name—the name of the result set for one specific document. These are formatted as [Job ID]_[Document ID]_result.
- Document ID—the Artifact ID of the document that was analyzed.
- Richness—the number of sentences with any predicted sentiment, divided by the total number of sentences in the document.If a sentence is predicted to have two or more sentiments, it will be counted multiple times towards the overall richness calculation. This can cause the Richness score to be greater than 100.
These sentiment-specific columns are also available for each sentiment that has been analyzed:
- [Sentiment] Top Score—the confidence score of the sentence most strongly predicted to have this sentiment. This is scored on a scale of 0 to 100, with 100 being the strongest.
- [Sentiment] %—the number of sentences predicted to have this sentiment, divided by the total number of sentences in the document.
- [Sentiment] Sentence Count—the number of sentences in the document that are predicted to have this sentiment.
- [Sentiment] Top Sentences—the top 25 sentences in the document that are predicted to have this sentiment, ranked by confidence score.
The documents listed under Job Details show their most recent sentiment analysis scores. They do not show previous scores that have been overwritten. For more information, see Re-running sentiment analysis.
Viewing the Sentiment Results tab
The Sentiment Results tab shows the analysis results listed by document.
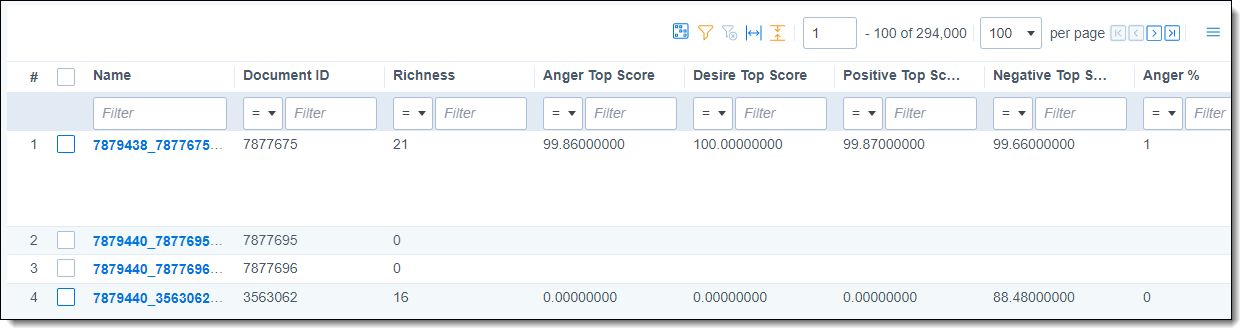
The general columns shown in the Results grid are:
- Name—the name of the result set for one specific document. These are formatted as [Job ID]_[Document ID]_result.
- Document ID—the Artifact ID of the document that was analyzed.
- Richness—the number of sentences with any predicted sentiment, divided by the total number of sentences in the document.If a sentence is predicted to have two or more sentiments, it will be counted multiple times towards the overall richness calculation. This can cause the Richness score to be greater than 100.
These sentiment-specific columns are also available for each sentiment that has been analyzed:
- [Sentiment] Top Score—the confidence score of the sentence most strongly predicted to have this sentiment. This is scored on a scale of 0 to 100, with 100 being the strongest.
- [Sentiment] %—the number of sentences predicted to have this sentiment, divided by the total number of sentences in the document.
- [Sentiment] Sentence Count—the number of sentences in the document that are predicted to have this sentiment.
- [Sentiment] Top Sentences—the top 25 sentences in the document that are predicted to have this sentiment, ranked by confidence score.
Viewing results details
From the Sentiment Results tab, clicking on the Name field brings you to a Sentiment Analysis Results Details view that shows the scores for only the selected document.
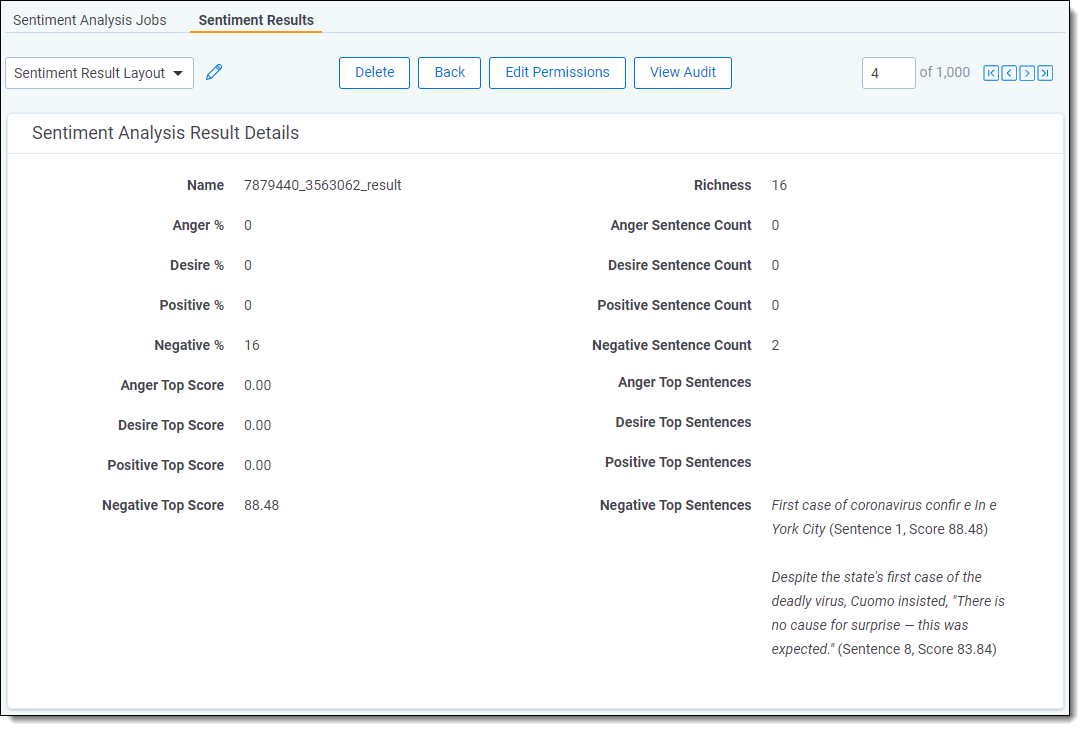
The buttons that are available include:
- Delete—deletes all sentiment analysis results attached to this document. This does not affect other documents or delete the records of any sentiment analysis jobs.
- Edit Permissions—opens a pop-up showing item-level security controls for this specific result set. For more information, see Security and permissions.
- View Audit—opens a pop-up showing the field updates, their timestamps, and the user that initiated the run.
Highlighting sentiments in the Viewer
After you run sentiment analysis on a document, this enables a Sentiment Analysis panel in the document viewer. This panel contains options for highlighting sentences in the document according to their predicted sentiments.
For detailed information on sentiment analysis highlighting, see Sentiment analysis highlights.
Troubleshooting sentiment analysis errors
When running sentiment analysis, a few types of errors are possible. These can affect either the entire job or individual documents.
Job-level errors
If the job status is marked as Error, this may be caused by:
- Technical issues—connection issues or other technical difficulties prevented the job from finishing. Check your connection and try again.
- All documents skipped—all documents in the job were skipped due to their contents. Check that the document set contains English text in the Extracted Text field and try again. For more information, see Document-level errors.
Document-level errors
Document-level errors fall into a few categories:
- Error—an error has occurred that prevented processing the whole document.
- Partial Error—an error occurred when analyzing the document for one or more sentiments, but the rest succeeded.
- Skipped—the document was skipped for one of these reasons:
- Too large to analyze—the extracted text field is over 5MB.
- No extracted text—the extracted text field has no contents.
For Skipped documents, consider removing the document from the saved search or transferring other text, such as OCR text, to the Extracted Text field. For all other errors, check your connection and try again.