






Feedback
Creating an Active Learning project
An Active Learning project consists of a few core components:
- Saved search - the set of documents to be used in the Active Learning project. This search is used to build the classification index.
- Classification index - the Analytics index which is the basis of the machine learning that takes place in Active Learning.
- Reviewer group - the group of reviewers coding documents in Active Learning.
- Review field - the field for reviewers to code documents in Active Learning. This field must be a single choice field with two or more choices.
You must create each of these components before you can create an Active Learning project. Even if these items already exist in the workspace, you may want to create a new instance of each specifically for your new project.
Creating the saved search
The first component you must create for your Active Learning project is a saved search of all documents to be used in the Active Learning project. This set of documents is used as the data source when you create an Analytics classification index.
A few considerations for the search:
- The saved search must be public.
- The documents in the search must contain extracted text.
- For best results, we recommend no more than 9 million documents in the search.
- If you want to use family-based review (Prioritized Review only), entire families must be added to the saved search. This includes documents that you might otherwise exclude from an Active Learning project.
If relevant documents are very rare, then targeted searches for relevant documents outside of the queue can help make Active Learning more effective.
Optimizing your Active Learning project
There are a few steps you can take when creating your saved search to optimize your Active Learning project.
Reduce document clutter
To streamline the start of your project, we recommend taking steps to reduce document clutter in your data source. This can include any combination of the following:
- Removing documents with poor or no text
- Removing out-of-scope documents
- Focusing on inclusive emails
- Running deduplication
Pre-code documents in the saved search
The Active Learning model only builds once you have at least five documents coded with the positive choice and five coded with the negative choice. We recommend having reviewers code a sample of documents prior to starting your Active Learning project to help start the model's learning and begin the project with a model build and a ranking of all documents. This can take place before or after you create the project.
In Prioritized Review, if there are fewer than five coded documents for either choice, the system serves random documents until the threshold number of documents are coded. These documents appear under the Index Health column in Review Statistics.
There are a few ways to identify documents to pre-code, and you will usually combine more than one strategy:
- Draw a sample of documents with specific keywords, from key custodians, within a certain date range, etc. to help focus the sample on documents more likely to be important in the case. Repeat for different aspects of responsiveness to best train the model.
- Cluster your documents, then use the choice field stratified sampling script to draw an equal number of documents from each cluster. This ensures your sample will include a broad variety of documents. For more information, see Choice field stratified sampling.
- Use pre-existing documents determined to be relevant/not relevant. You must ensure the coding decision for these documents is set on the review field used to create your Active Learning project.
Aim for an even distribution of documents pre-coded on the positive/responsive designation as on the negative/not responsive designation when possible. For example, If your richness is low and you expect to find not responsive documents easily, then focus your effort on finding more responsive documents to pre-code.
Estimating richness
We recommend taking a richness sample to pre-code documents. Richness refers to the percentage of documents in a project that are responsive. We recommend calculating a richness estimate at the start of the project to give you a metric to gauge the progress of your project against.
To calculate richness, you can run an early Project Validation round which has Elusion with Recall selected. See Project Validation and Elusion Testing for more information.
Alternately, you can use the following method:
First, use the Sampling tool to take a sample of documents from your data source and have reviewers code all of those documents on the project review field:
- Navigate to the saved search used to create the Active Learning project.
- Click the Sampling icon
 to display the sampling drop-down menu.
to display the sampling drop-down menu. - Select a Sampling Type, then determine a size or percentage appropriate for the size of your project. This does not need to be a large sample. Many people choose a Statistical sample using 95% Confidence Level and 5% Margin of Error, which is 385 documents or fewer.
- Click Sample.
- Have reviewers code the documents in the sample on the project review field. Do not skip documents or mark them as neutral. These pre-coded documents will help jump start your Active Learning project later.
To calculate the richness estimate, divide the number of documents the reviewers found to be relevant by the total number of documents in the sample.
- Sample Richness = # of documents coded on the positive choice / Total # of documents in sample
For example, imagine you ran a sample of 500 documents and your reviewers found 80 to be relevant. The richness for this sample would be 80 / 500 = .16, or 16%.
To estimate the number of responsive documents in the entire project, multiply the richness from the sample by the total number of documents in the saved search.
- Estimated # of responsive documents = Sample richness x Total # of documents in saved search
For example, if the total number of documents in the saved search used to create your Active Learning is 100,000, the estimate of the number of relevant documents for the entire project would be .16 x 100,000 = 16,000. This mean there will likely be around 16,000 relevant documents in your project. This prediction could be a little high or a little low, depending on the margin of error.
You can use this estimate to monitor the progress of your Active Learning project. For example, after you start your Active Learning project you see that your reviewers have coded 8,000 documents as relevant. Using the estimate, you can assume that you have found about half of all relevant documents in your case.
Creating the classification index
Active Learning uses an Analytics classification index as the basis of its machine learning. The classification index uses Support Vector Machine learning (SVM) to predict the relevance of uncoded documents in Active Learning based on their closeness to coded examples. To learn more about Support Vector Machine learning (SVM), see Analytics indexes.
Once you have the set of documents you want to use for Active Learning in a saved search, you can create the classification index. To create the classification index:
- Classification indexes are used only by Active Learning projects.
- You can add and remove documents from your Active Learning project (via the index) at any time.
- Navigate to Analytic Indexes.
- Click New Analytics Index.
- Complete the following fields on the Analytics Index Information form:
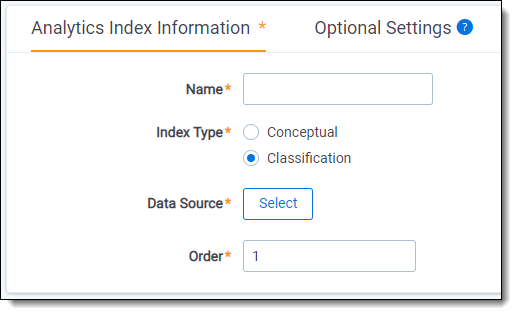
- Name - enter a name for the index. This value appears in the search drop-down menu after you activate the index.
- Index type - select Classification.
- Data source - select the saved search created above.
- Email notification recipients (under Optional Settings) - send email notifications when your index successfully completes, fails, or when the index is disabled because it is not being used. Enter the email address(es) of the recipient(s). Use a semicolon to separate multiple email addresses. A message is sent for both automated and manual index building.
- (Advanced Settings fields) Relativity Analytics server - select the Analytics server that should be associated with the Analytics index.
- Click Save. Once you click Save, the Analytics Index console becomes available.
- From the Analytics Index console, click Run. If this is your first time running the index, it will automatically run a full population. Otherwise, choose Run, then Full.
You can continue creating the other required components for Active Learning while you wait for the index to activate. However, the index must be active in order to create the Active Learning project.
Creating the reviewer group
When you create an Active Learning project, you designate a reviewer group which is the set of users you want to code documents in the Active Learning project. You can create a new group specifically for your Active Learning project, or you can use an existing group. Ensure the group is added to the workspace where you're running Active Learning.
- The users in this group are not automatically added to the Active Learning project. You must grant each individual access to the Review queue.
- You can add or remove users from the group at any time.
The reviewer group accessing the Active Learning project must have the following permissions:
| Object Security | Tab Visibility | Other Settings |
|---|---|---|
|
|
|
The users in this group are not automatically added to the Active Learning project. You must grant each individual access to the Review queue.
Other considerations for setting group permissions:
- If the Browsers permission is set only to Advanced & Saved Searches, reviewers can't access the view for the review queues.
- The review group must have access to all documents in the Active Learning project. If documents are not accessible (for example, documents stored in a secured folder) they are not served to reviewers in the queue.
- You can add or remove users from the group at any time.
- If you add a new reviewer to a group that is already tied to an Active Learning project, it may take some time for the change to synchronize with the project. If you still cannot grant the reviewer access after 24 hours, contact Product Support.
Creating the review field
Active Learning requires a single choice field with at least two choices for reviewers to code on. One choice must represent the positive/responsive designation, and another must represent the negative/not responsive designation. Any additional choices will be considered neutral, and they will not be used to train the Active Learning model.
Reviewers may also code documents on other fields that you include in your review layout; however, only this review field is used by the Active Learning model.
- In your workspace, navigate to the Fields tab.
- Click New Field.
- Complete the fields in the Field Information section as follows:
- Name - enter a name for your review field.
- Object Type - select Document.
- Field Type - select Single Choice.
- Under List and Dashboard Settings, select Enable Group By and Enable Pivot.
- Leave all other fields as default, or edit to your workspace specifications.
We recommend turning off family propagation with Active Learning.
- Click Save.
- In the Choices section, click Add Choice.
- Enter a name for the positive/responsive designation, and then click Enter.
- Click Add Choice again.
- Enter a name for the negative/not responsive designation, and then click Enter.
You can edit these choices after you create the project.
Creating the review layout
Active Learning does not create a layout automatically; you must create or modify an existing layout for reviewers to make coding decisions using the review field created above. This layout is not a prerequisite for creating your Active Learning project, but the layout should exist before the reviewer group begins coding in Active Learning. You can also include other fields on this layout. Active Learning only learns from the review field.
Creating a new Active Learning project
Once you've configured the required workspace components, you can create your Active Learning project
To create an Active Learning project, complete the following:
- From your workspace, navigate to Assisted Review > Active Learning Projects.
- Click New Active Learning Project.
- Complete the fields on the layout. See Fields.
- Click Save.
You are then redirected to the project home dashboard.
Analytics classification indexes are copied over when a workspace is used as a template, as are conceptual indexes. However, you can't copy an Active Learning project in a template.
Fields
The Active Learning Project layout contains the following fields:
- Project Name - enter a name for your Active Learning project.
- Analytics Index (Classification) - select the Analytics classification index. The index must have completed a build and cannot be associated with any other Active Learning project.
- Review Field - select the single choice field you created for review. This field must have at least two choices.
- Positive Choice - select the choice that represents the positive/responsive designation.
- Negative Choice - select the choice that represents the negative/non-responsive designation. Any remaining choices will be considered neutral.
- Suppress Duplicate Documents - selecting this option stops Active Learning from serving documents that are textually similar to other coded documents to be coded (this does not consider word order). This option reduces the total number of documents needed to be reviewed. Since these are not exact duplicates, you will most likely need to review suppressed documents after the project is complete. For more information, see Suppressed duplicate documents.
We recommend setting the Suppress Duplicate Documents setting to No for Prioritized Review and Yes for Coverage Review. Note that you cannot change this setting once you create your project.
- Reviewer Group - select the group you want to access the Active Learning queues.
Once a project is created, you cannot edit the fields. Any additional choices created for the review field will be considered neutral.
Active Learning objects
Upon saving a new project, Relativity creates a few different objects specific to Active Learning.
Project document list view
This view is automatically secured to the reviewer group. Initially the view will be empty, but as reviewers code documents in Active Learning queues, the view returns documents previously reviewed by the currently logged in reviewers. This is the document list view that's tied to the Active Learning project. It has the same name as the Active Learning project and is customizable by admins. This is the only place a reviewer can enter a project queue.
Project fields
Relativity also creates new fields that can be used for custom document list reporting. These fields are updated per document as reviewers code on the project review field.
- <Project Name> Reviewers::User - the name of the reviewer who coded the document in the queue.
- You can use this field to identify manually-selected documents. Search for documents where the review field is set, but this field is not set. Because manually selected documents are documents which are not coded via an Active Learning queue, the Reviewers field would not be set for those documents.
- <Project Name> Reviewers - the name of the project plus the name of the reviewer who coded the document in the queue.
- <Project Name> Reviewed On - a timestamp indicating when a document was reviewed.
- <Project Name>:: Coverage Review - the 200-document interval in which the document was reviewed in the Coverage Review.
- <Project Name>:: Project Validation - the Project Validation in which the document was reviewed.
- <Project Name>:: Prioritized Review - the 200-document interval in which the document was reviewed in the Prioritized Review.
For more information on using these fields in reports and dashboards, see Monitoring an Active Learning project.
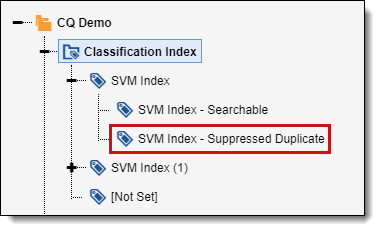
Suppressed duplicate documents
If you chose to suppress duplicate documents, you can view those documents from the Field Tree. You can find the tag for suppressed duplicate documents under the Classification index associated with the Active Learning project. Documents are tagged with the <Index Name> - Suppressed Duplicate tag as they're identified during review.
There is currently no way to add these documents back into the review queue or to identify which coded document caused a document to be suppressed. However, you can code these documents manually and they are indicated as manually-selected documents in the project.
Viewing project settings and errors
Once you've created an Active Learning project, you're redirected to the Project Home tab. In the top-right corner of the Project Home tab are three icons.
- Update Ranks
 - use to manually update the document ranks and ensure the rank categorization field is up to date. For more information, see Update ranks.
- use to manually update the document ranks and ensure the rank categorization field is up to date. For more information, see Update ranks. - Notifications
 - informs you of any notifications you may have in the project such as project errors . A red circle appears in the bottom corner of the Notifications icon if a notification exists. Follow the instructions in the error message to resolve the project error. Once you've resolved the error, the error message automatically disappears.
- informs you of any notifications you may have in the project such as project errors . A red circle appears in the bottom corner of the Notifications icon if a notification exists. Follow the instructions in the error message to resolve the project error. Once you've resolved the error, the error message automatically disappears. - Project Settings
 - gives an overview of the settings that were either selected during the initial project setup, or that can be modified mid-project. It includes the following:
- gives an overview of the settings that were either selected during the initial project setup, or that can be modified mid-project. It includes the following:- Project Details:
- Project Name
- Analytics Index
- Review Field
- Positive Choice
- Negative Choice
- Suppress Exact Duplicates
- <Positive Choice> Cutoff
Click the
 icon to edit the <Positive Choice> Cutoff value. This rank divides positive and negative predictions, such as "relevant" and "not relevant." When you update the cutoff value, the value is updated in all three places where it’s used in the application: Project Validation, Update Ranks, and Project Settings.
icon to edit the <Positive Choice> Cutoff value. This rank divides positive and negative predictions, such as "relevant" and "not relevant." When you update the cutoff value, the value is updated in all three places where it’s used in the application: Project Validation, Update Ranks, and Project Settings. Include Index Health in Prioritized Review
Click the
icon to change whether index health documents are served up for review. This setting only affects Prioritized Review queues. For more information, see Turning off index health documents.
- Reviewer Setup:
- Reviewer Permission Group
- Project Details: