Feedback
Load file specifications
Using load files, Relativity can load the following types of files. The sections below detail the load file requirements for the respective file types.
- Metadata, extracted text, and native files
- Image and extracted text files
- Processed data
Supported file types
Relativity accepts only the following load file types:
- .dat
- .csv
- .txt
Metadata, extracted text, and native files
Relativity uses a flat, document-level load file to load metadata, document level extracted text, and natives files. Each line should represent one document.
Encoding
The Relativity Desktop Client (RDC) attempts to determine the encoding of a file, by default, when a load file is first selected. To do this, the RDC checks the byte order mark at the beginning of the file. If there is no byte order mark, it cannot determine the encoding type. The types of byte order marks include:
- Unicode (UTF16)
- Big-Endian Unicode
- UTF8
Everything else is considered undetectable by the RDC and uses the default encoding chosen for the load file or stand-alone extracted text file.
A variety of load file encoding options are supported, including:
- Western European (Windows)
- Unicode
- Unicode (Big-Endian)
- Unicode (UTF-7)
- Unicode (UTF-8)
- Other options, based on your SQL sever
Header row
Relativity doesn't require load file header rows. However, they are strongly recommended to ensure accuracy.
The field names in your header don't need to match the field names in your workspace.
Fields
Relativity doesn't require any specific load file field order. You can create any number of workspace fields to store metadata or coding. During the load process, you can match your load file fields to the fields in your workspace.
The identifier field is required for each load.
When loading new records, this is your workspace identifier.
When performing an overlay, you can use the workspace identifier or select another field as the identifier. This is useful when overlaying production data. For example, you could use the Bates number field rather than the document identifier in the workspace.
All fields except Identifier are optional; however, you may find some of the following system fields beneficial.
- Identifier—the unique identifier of the record
- Group Identifier—the identifier of a document’s family group
- The group identifier repeats for all records in the group.
- Usually, this is the document identifier of the group’s parent document. For example:
- If an email with the document identifier of AS00001 has several attachments, the email and its attachments have a group identifier of AS00001.
- If a group identifier for a record is not set, the document identifier populates the group identifier field in the case. This effectively creates a “group” of one document.
- MD5 Hash—the duplicate hash value of the record
- You can enter any type of hash value (and rename the field in your case).
- If documents share the same hash value, Relativity identifies the documents as a duplicate group.
- If a hash field for a record is not set, the document identifier populates the hash field in the case. This effectively creates a “group” of one document.
- Extracted Text—The text of the document. Either the OCR or Full Text.
- The extracted text appears in the viewer and is added to search indexes. This field can contain either:
- The actual OCR or Full Text
- The path to a document level text file containing the OCR or Full Text. The path to a document level text file containing the OCR or Full Text. Both relative and absolute paths are supported (use Windows-style formatting containing backslashes "\").
- The extracted text appears in the viewer and is added to search indexes. This field can contain either:
- Native File Path—the path to any native files you’d like to load.
- Both relative and absolute paths are supported.
- Folder Info—builds the folder browser structure for the documents.
- This field is backslash “\” delimited.
- If not set, the documents load to the root of the case.
- Each entry between backslashes is a folder in the Relativity folder browser.
- Each backslash indicates a new subfolder in the browser.
For example, if the load file contained the following entry in the folder info field: “Slinger, Ryan\Email\deleted_items”
Relativity would build the following folder structure: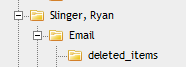
Each document with the above entry would be stored in the “deleted_items” folder.
- Relativity Native Time Zone Offset—Relativity’s native viewer technology displays all email header dates and times in GMT. This numeric field offsets how email header dates and times appear in the viewer.
- If the value in this field is blank, or 0, for a document, then the email header date and time appears in GMT.
- You can enter a whole number in this field – positive or negative – to offset the time from GMT to the local time zone of the document.
- For example, if the document was collected from US CDT time, enter “-5” in the field, because the CDT offset from GMT is -5.
- This ONLY applies when viewing email header dates and times in the Relativity Native File Viewer. Your metadata fields display as imported.
Accepted date formats
Relativity accepts date and time as one field. For example, Date Sent and Time Sent should be one field. If date sent and time sent ship separately, you must create a new field for time. You can format date fields to accept the date without the time, but not the time without the date. Dates can't have a zero value. Format dates in a standard date format such as “6/30/2017 1:23 PM” or “6/30/2017 13:23”.
When you import data using a load file with a date format that differs from the format used on your local machine, Relativity follows the locale setting of your local machine to determine how it interprets what is in the load file.
The table below lists the date formats recognized by the Relativity Desktop Client and the Import API. It contains both valid and invalid date formats:
| Entry in Load File | Object Type | Definition |
|---|---|---|
| 12/31/9999 | 12/31/9999 0:00 | |
| Monday January 4 2018 | 1/4/2018 0:00 | |
| 05/28/2016 7:11 AM | 05/28/2016 7:11 AM | |
| 5.08:40 PM | 6/30/2019 17:08 | The current date will be entered if the date is missing. For this example, assume the import was done on 6/30/2019. |
| 17:08:33 | 6/30/2019 17:08 | The current date will be entered if the date is missing. For this example, assume the import was done on 6/30/2019. |
| 17:08 | 6/30/2019 17:08 | The current date will be entered if the date is missing. For this example, assume the import was done on 6/30/2019. |
| 5:08 PM | 6/30/2019 17:08 | The current date will be entered if the date is missing. For this example, assume the import was done on 6/30/2019. |
| 14-Apr | 4/14/2019 0:00 | The current year will be entered if the year is missing. |
| 9-Apr | 4/9/2019 0:00 | The current year will be entered if the year is missing. |
| 14-Mar | 3/14/2019 0:00 | The current year will be entered if the year is missing. |
| 1-Mar | 3/1/2019 0:00 | The current year will be entered if the year is missing. |
| 22-Feb | 2/22/2019 0:00 | The current year will be entered if the year is missing. |
| 20180420 | 4/20/2018 0:00 | |
| 20180420 2:22:00 AM | 4/20/2018 0:00 | |
| 4/9/2018 16:13 | 4/9/2018 16:13 | |
| 4/9/2018 8:49 | 4/9/2018 8:49 | |
| 9-Apr-18 | 4/9/2018 0:00 | |
| Apr. 9, 18 | 4/9/2018 0:00 | |
| 4.9.2018 | 4/9/2018 0:00 | |
| 4.9.18 | 4/9/2018 0:00 | |
| 4/9/2018 | 4/9/2018 0:00 | |
| 4;9;2018 | 4/9/2018 0:00 | |
| Wednesday, 09 April 2018 | 4/9/2018 0:00 | |
| 12-31-1753 | 12/31/1753 12:00 AM | |
| 2014-11-28T17:45:39.744-08:00 | 11/28/2014 0:00 | |
| 4/9/18 13:30 PM | Results in an error | |
| 2018-044-09 | Results in an error | |
| 4/9/2018 10:22:00 a.m. | Results in an error | |
| 00/00/0000 | Results in an error unless the CreateErrorForInvalidDate value is set to false in the |
In addition, Relativity takes into account the regional settings of the SQL Server where the database resides. For example, you may have an SQL Server residing in the UK that uses the date format DD/MM/YYYY, such as 4/9/2011. When you access a workspace on a PC with UK regional settings, the date appears as 4/9/2011. When you access the same workspace on a PC with US regional settings, the date appears as 9/4/2011.
Delimiters
During import, you can designate which delimiters are used in your load file. You can select each delimiter from the ASCII characters, 001 – 255.
The delimiter characters have the following functions:
- Column—separates load file columns
- Quote—marks the beginning and end of each load file field (also known as a text qualifier)
- Newline—marks the end of a line in any extracted or long text field
- Multi-value—separates distinct values in a column. This delimiter is only used when importing into a Relativity multi-choice field.
- Nested-values—denotes the hierarchy of a choice. This delimiter is only used when importing into a Relativity multi-choice field.
For example, say a load file contained the following entry, and was being imported into a multi-choice field: “Hot\Really Hot\Super Hot; Look at Later”
With the multi-value delimiter set as “;” and the nested value delimiter set as “\"”, the choices would appear in Relativity as: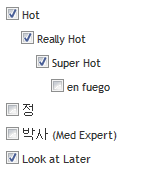
Default delimiters
If you generate your own load files, you may choose to use Relativity’s defaults:
- Column—Unicode 020 (ASCII 020 in the application)
- Quote—Unicode 254 (ASCII 254 in the application)
- Newline—Unicode 174 (ASCII 174 in the application)
- Multi-Value—Unicode 059 (ASCII 059 in the application)
- Nested Values—Unicode 092 (ASCII 092 in the application)
Image and extracted text files
For image imports, Relativity requires Opticon load files with ANSI/Western European encoding. This .opt text file references the Control ID on a page level. The first page should match up to any data you intend to load. You can use this same process for importing page-level extracted text.
Relativity does not support Unicode .opt files for image imports. When you have a Unicode .opt file, you must resave this file in ANSI/Western European encoding.
You must convert images in unsupported formats using a third-party conversion tool before Relativity can successfully upload them.
Image file formats
Relativity accepts only the following file types for image loads:
- Single page, Group IV TIFs (1 bit, B&W)
- Single page JPGs
Multi page TIFs and PDFs can be imported into the system, but you must load them as native files.
Load file format
The Opticon load file is a page level load file, with each line representing one image.
Below is a sample:
REL00001,REL01,D:\IMAGES\001\REL00001.TIF,Y,,,3
REL00002,REL01,D:\IMAGES\001\REL00002.TIF,,,,
REL00003,REL01,D:\IMAGES\001\REL00003.TIF,,,,
REL00004,REL01,D:\IMAGES\001\REL00004.TIF,Y,,,2
REL00005,REL01,D:\IMAGES\001\REL00005.TIF,,,,
The fields are, from left to right:
- Field One – (REL00001) – the page identifier
- Field Two – (REL01) – the volume identifier is not required.
- Field Three – (D:\IMAGES\001\REL00001.TIF) – a path to the image to be loaded
- Field Four – (Y) – Document marker – a “Y” indicates the start of a unique document.
- Field Five – (blank) – can be used to indicate folder
- Field Six – (blank) – can be used to indicate box
- Field Seven – (3) – often used to store page count, but unused in Relativity
Importing extracted text during an image load
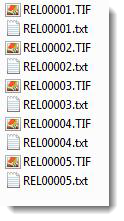
You can also import extracted text during the image import process by setting an option in the Relativity Desktop Client.
No changes are needed in the Opticon load file. If the aforementioned setting is active, Relativity looks for page level txt files named identical to their corresponding TIFs. For example:
Processed data
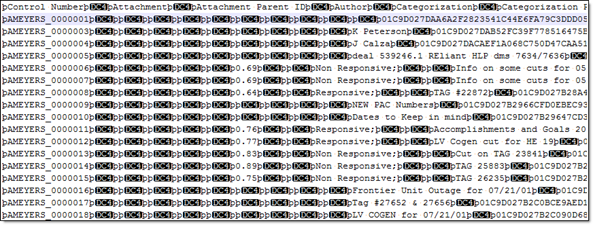
Some data originates from client files and needs processing to extract the metadata. The following table shows the delimiters that your internal processing software must use to present data as fields.
| Value | Character | ASCII Number |
|---|---|---|
| Column | ¶ | 020 |
| Quote | þ | 254 |
| Newline | ® | 174 |
| Multi-Value | ; | 059 |
| Nested Value | \ | 092 |
You can provide this list to your vendor to help communicate the required delivery format for load files. The fielded data should be delivered as delimited files with column or field names located in the first line.