






Feedback
Processing Statistics
This Relativity system-level script provides you with the option of displaying:
- A report of processed data sizes per processing set and user in all workspaces in the environment.
- A summary of all processed data in all workspaces in the environment.
Category
This is a Relativity script that runs at the environment level. You must run this script while in Home mode, as it won't work from the workspace.
Special considerations
Note the following considerations regarding this script:
- This script only reports on workspaces in which the processing application was successfully installed.
- A processing set with no Data Source will not be displayed in the report.
Input and preparation
Enter the following information in the input fields on the script:
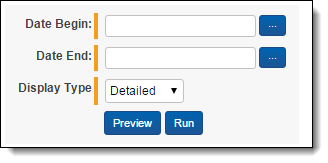
- Date Begin - select a beginning date to report on. This will filter the results to display processing sets where the System Created On field falls within the selected date range.
- Date End - select an end date to report on. This will filter the results to display processing sets where the System Created On field falls within the selected date range.
- Display Type - select one of the following options:
- Detailed - the report will display the results grouped by workspace and processing set.
- Summary - the report will display the results grouped by workspace
Script results
The results of running the Processing Statistics script are displayed in the typical Relativity Script format.
When you execute the script, Relativity displays a report of all processing sets whose last system created on date falls within the selected date range. The report displays data for processing sets where the published status is any value.
Returned output - detailed display type
When you select Detailed for the Display Type field, the results window includes the following columns:
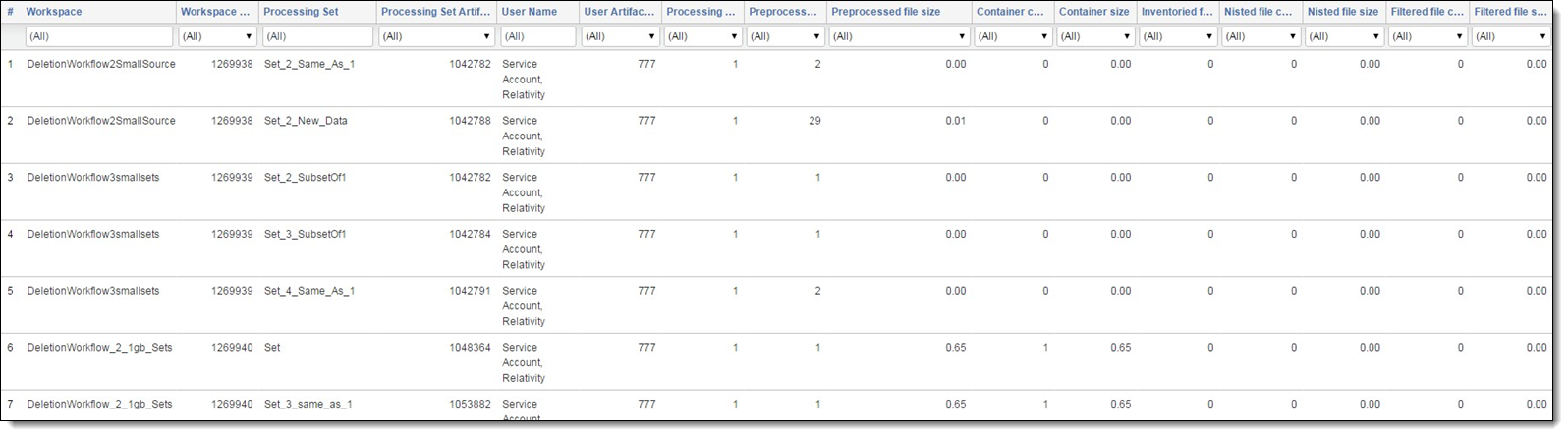
| Column heading | Description |
|---|---|
| Workspace | The name of the workspace. |
| Workspace Artifact ID | The artifact ID of the workspace. |
| Processing Set Creation | The date the processing set was created. |
| Processing Set Artifact ID | The artifact ID of the processing set. |
| Last Modified Dates | The last date the processing set was modified. |
| Processing Data Source Count | The count of Data Sources for the Processing set where the status is either Completed or Completed with Errors. |
| Discover Status | The current status of the discovery phase of the set. |
| Inventory Status | The current status of the inventory phase of the set. |
| Publish Status | The current status of the publish phase of the set. |
| Preprocessed file count | The count of all native files before extraction/decompression, as they exist in storage. |
| Preprocessed file size | The sum of all the native file sizes, in GB, before extraction/decompression, as they exist in storage. |
| Container count | The count of all native files classified as containers before extraction/decompression, as they exist in storage. This also includes nested containers that haven’t been extracted yet. |
| Container size | The sum of all native file sizes, in GB, classified as containers before extraction/decompression, as they exist in storage. This value may be larger than the preprocessed file size because it also includes nested containers. |
| Inventoried files | The count of all files found during an inventory run. |
| Nisted file count | The count of all files denisted out during discovery. |
| Nisted file size | The sum of all the file sizes, in GB, denisted out during discovery. |
| Filtered file count | The count of all files excluded from discovery by way of an exclusion filter after inventory. |
| Filtered file size | The sum of all the file sizes, in GB, excluded from discovery by way of an exclusion filter after inventory. |
| Discovered document | The count of all the native files discovered that aren’t classified as containers as they exist in storage. |
| Discovered document size | The sum of all native file sizes discovered, in GB, that aren’t classified as containers as they exist in storage. |
| Duplicate file count | The count of duplicate native files associated to the user, processing set and workspace. |
| Duplicate file size | The sum of duplicate native file sizes, in GB, associated to the user, processing set and workspace. |
| Published documents | The count of published native files associated to the processing set or workspace. |
| Published document size | The sum of published native file sizes, in GB, associated to the processing set or workspace. |
| Total file count after discovery | The count of all native files (including duplicates and containers) as they exist after decompression and extraction. |
| Total file size after discovery | The sum of all native file sizes (including duplicates and containers), in GB, as they exist after decompression and extraction. |
| Storage file size after publishing | The sum of all file sizes, in GB, as they exist in storage after publishing. This is the total file size minus any files that were ingested twice. This value only counts the file once, ignoring duplicates. |
File size changes in script report
The following table provides a breakdown of how the values contained in the Processing Statistics script report can be expected to change as processing progresses. In the following example, a 5 GB PST file becomes 10 GB worth of emails and attachments.
| Processing phase | Column name | Expected value |
|---|---|---|
| None (not processed) | Preprocessed file size | 5 GB |
| None (not processed) | Container size | 5 GB (PST file + any containers) |
| Discovery | Discovered document size | 10 GB |
| Publishing | Published document size | 10 GB |
| After discovery & publishing | Total file size after discovery | 15 GB (10 GB in emails and attachments, 5 for the PST, without de-duping or filtering) |
| After discovery & publishing | Storage file size after discovery/publishing | 10 GB |
Returned output - summary display type
When you select Summary for the Display Type field, the results window includes the following columns:
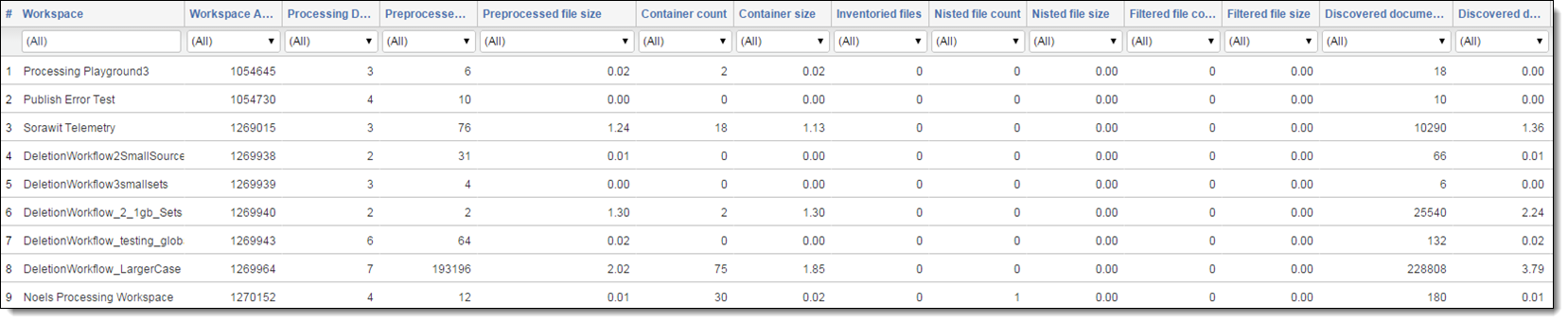
| Column heading | Description |
|---|---|
| Workspace | The name of the workspace. |
| Workspace Artifact ID | The artifact ID of the workspace. |
| Processing Data Source Count | The count of Data Sources for the Processing set where the status is either Completed or Completed with Errors. |
| Preprocessed file count | The count of all native files before extraction/decompression, as they exist in storage. |
| Preprocessed file size | The sum of all the native file sizes, in GB, before extraction/decompression, as they exist in storage. |
| Container count | The count of all native files classified as containers before extraction/decompression, as they exist in storage. This also includes nested containers that haven’t been extracted yet. |
| Container size | The sum of all native file sizes, in GB, classified as containers before extraction/decompression, as they exist in storage. This value may be larger than the preprocessed file size because it also includes nested containers. |
| Inventoried files | The count of all files found during an inventory run. |
| Nisted file count | The count of all files denisted out during discovery. |
| Nisted file size | The sum of all the file sizes, in GB, denisted out during discovery. |
| Filtered file count | The count of all files excluded from discovery by way of an exclusion filter after inventory. |
| Filtered file size | The sum of all the file sizes, in GB, excluded from discovery by way of an exclusion filter after inventory. |
| Discovered document count | The count of all the native files discovered that aren’t classified as containers as they exist in storage. |
| Discovered document size | The sum of all native file sizes discovered, in GB, that aren’t classified as containers as they exist in storage. |
| Duplicate file count | The count of duplicate native files associated to the user, processing set and workspace. |
| Duplicate file size | The sum of duplicate native file sizes, in GB, associated to the user, processing set and workspace. |
| Published documents | The count of published native files associated to the user, processing set and workspace. |
| Published document size | The sum of published native file sizes, in GB, associated to the user, processing set and workspace. |
| Total file count after discovery | The count of all native files (including duplicates and containers) as they exist after decompression and extraction. |
| Total file size after discovery | The sum of all native file sizes (including duplicates and containers), in GB, as they exist after decompression and extraction. |
| Storage file size after publishing | The sum of all file sizes, in GB, as they exist in storage after publishing. This is the total file size minus any files that were ingested twice. This value only counts the file once, ignoring duplicates. |