






Feedback
Running name normalization on email headers
When running name normalization, email header formats in the extracted text can have a lot of variation and are generally less clean than the top-level headers. Because of this, you may want to initially run name normalization on only the top-level headers (To, From, Cc, Bcc) to produce cleaner results. These results can then be used to help seed additional runs of name normalization.
See these related pages:
Using email header settings for name normalization
When you create a structured analytics set, there are two settings that affect whether name normalization will run on the email headers, or on the extracted text. These settings are found in the Email Headers section.
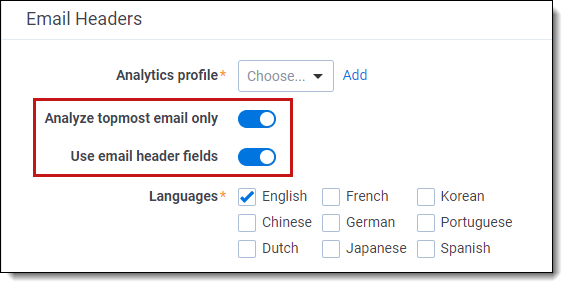
The settings are:
-
Analyze topmost email only—runs name normalization on the most recent email received in an email chain.
-
Use email header fields—includes the email metadata fields in the analysis.
-
Email metadata fields include From, To, CC, BCC, Subject, and Date Sent.
-
You can map the email metadata fields in the Analytics profile. For more information, see Analytics profiles.
-
In order to see these settings, select Name Normalization as one of the operations to run.
Email header setting combinations
Depending on how each setting is toggled, name normalization analyzes documents differently.
For most name normalization sets, we recommend leaving both settings On. However, different setups work better for different data sets.
| Setting Combination | Effect |
|---|---|
|
Setup 1:
|
Name normalization runs first on the email metadata fields associated with each document. If a document does not have a From field and at least one other email header field, name normalization analyzes the extracted text from the top segment of the email chain instead. |
|
Setup 2:
|
Name normalization ignores the email metadata fields associated with each document. Instead, it analyzes the extracted text from the top segment of the email chain. |
|
Setup 3:
|
Name normalization analyzes both the email metadata fields and the complete extracted text of each document. |
|
Setup 4:
|
Name normalization only analyzes the complete extracted text. It does not analyze the email metadata fields. |
Regardless of settings, if name normalization cannot find a From header and at least one other email header (such as To, CC, BCC, Subject, or Date Sent) in whatever it analyzes, it skips analyzing the document. These documents are assumed to be non-emails.
Effect on Participants
The content of the Participant field is affected by these settings as follows:
-
If name normalization analyzes only the email metadata fields, then the Participant field populates with the Entities found in the metadata fields.
-
If name normalization analyzes the complete extracted text, then the Participant field populates with the Entities found in the entire extracted text.
For more information on the Participant field, see Name normalization results.
Using regular expressions to force metadata use
Usually, if name normalization cannot find a From field and one other email header field (such as To, CC, BCC, Subject, or Date Sent), it analyzes the extracted text to find it. If you want to force name normalization to use only email metadata fields, you can use regular expressions (regex) to filter out all extracted text.
This workflow assumes you have the following:
- A structured analytics set to be used only for name normalization.
- High-quality, clean data for the Email From, Email To, Email CC, and Email BCC fields.
- An Analytics profile where the Email From, Email To, Email CC, and Email BCC fields are properly mapped.
To force name normalization to run on email metadata fields only:
- From the Repeated Content Filters tab, create a filter with the following settings:
- Name - For Name Normalization ONLY
- Type - Regular Expression
- Configuration - enter (?s).*+
You must set the configuration to the seven characters specified above, exactly as it appears, with no extra spaces.
The regular expression filter is the key to this solution. The filter works as follows:
- (?s) - denotes that the .* wildcard should include line breaks.
- .* - denotes "any character, any number of times." Combined with the (?s) above, this matches any character, any number of times, including line breaks.
- + - modifies the expression to match as many characters as possible without backtracking. This makes it more memory efficient.
In other words, this filters out every character of the extracted text, including line breaks, as it is being sent to the Analytics engine.
We highly discourage using this regular expression anywhere else. Only use this regular expression with name normalization. If you apply this regular expression to other operations, such as email threading, the results will be unusable.
- Set the following conditions on the structured analytics set running name normalization:
- Structured Analytics Set Information
- Operations to run - select only Name Normalization.
- Email Headers
- Analytics profile - select the Analytics profile with properly mapped email header fields.
- Use email header fields - set to Yes.
- Optional Settings
- Regular expression filter - select For Name Normalization ONLY.
- Structured Analytics Set Information
- Run the structured analytics set. Once the set completes, you should see that name normalization has found entities and aliases based solely on the headers. One way to confirm this is by examining the Entity Participant field. It should be set only to the entities listed in the Entity From and Entity Recipient fields, nothing more. Similarly, the Alias Participant should contain only the Alias From and Alias Recipient aliases.
After executing this process, you can work with the entities and aliases as-is, or you may later choose to bring the extracted text into consideration. To bring in the extracted text, remove the regular expression filter from the structured analytics set, and then re-run the set with the Repopulate Text setting enabled.
There are other regular expressions such as ^.*$ that can achieve the same result. However, they are more memory intensive. We recommend using the (?s).*+ expression for best performance, especially if your document set includes large documents.
Additional regular expression resources
For more information on using regular expressions (regex) in Relativity, see: