





Use the following guidelines to configure your Analytics server(s) for optimum performance with Relativity.
Memory requirements
Analytics indexing
Server memory is the most important component in building an Analytics index. The more memory your server has, the larger the data sets that can be indexed without significant memory paging. Insufficient memory will slow down index build performance.
The following factors affect RAM consumption during indexing:
- Number of documents in the data source
- Number of documents in the training data source
- Number of unique words across all the documents in the data set being indexed
- Total mean document size (as measured in unique words)
Use the following equation to estimate how much free RAM is needed to complete an index build:
(Number of Training Documents) * 6000 = Amount of RAM needed in bytes
An easy way to remember this equation is that every 1 million training documents in the index require 6 GB of free RAM. The equation is based upon the average document set in Relativity. If your data set has more unique terms than an average data set, more RAM will be required to build. We recommend accounting for slightly more RAM than the equation estimates.
Structured analytics
To run structured analytics, the Analytics server can require substantial server resources. The structured analytics features are run by the Java process, as well as PostgreSQL. One of the most important parts of making sure a structured analytics operation succeeds is ensuring that Java has access to enough RAM. This is referred to as Java heap size, or JVM.
Use the following equation to estimate how much JVM will be required for a given structured analytics set:
(Number of Documents) * 6000 = Amount of JVM needed in bytes
An easy way to remember this equation is that every 1 million documents in the set require about 6 GB of RAM for the Java process. If your data set is comprised of very long documents, it may require more JVM. If it is comprised of very small documents, then you may not need as much JVM. If Java does not have enough memory to complete a structured analytics operation, you will sometimes receive an out of memory (OOM) error. More often, though, Java will heap dump and garbage collect endlessly without ever successfully completing the operation. This equation is a good starting point so that these types of problems do not occur. For information on how to configure JVM, see Java heap size (JVM).
Enabled Analytics indexes
An Analytics index is stored on disk and is loaded into memory when the index has queries enabled (the Enable Queries button on the index). An index with queries enabled may be used for all Analytics functions such as clustering, categorization, and querying. When you enable queries on an Analytics index, Relativity loads the vectors associated with all searchable documents and words in the conceptual space into RAM in an LSIApp.exe process. For indexes with millions of documents and words, this RAM requirement may be thousands of MB.
The following ranges indicate the amount of RAM needed to enable queries on an index:
- Number of bytes required (Low end): (Number of searchable documents) * 400
- Number of bytes required (High end): (Number of searchable documents) * 5000
Click Disable Queries on any Analytics indexes that aren’t in use to free up RAM on the Analytics server. The MaxAnalyticsIndexIdleDays instance setting helps with this issue. This value is the number of days that an Analytics index can remain inactive before the Case Manager agent disables queries on it. Inactivity on the Analytics index is defined as not having any categorization, clustering, or any type of searches using the index. This feature ensures that indexes that are not being used are not using up RAM on the Analytics server. If the index needs to be used again, navigate to the index in Relativity and click Enable Queries. It will be available for searching again within seconds.
Java heap size (JVM)
Depending on the amount of RAM on your Analytics server, as well as its role, you will need to modify the Java Heap Size setting. This setting controls how much RAM the Java process may consume. Java is used for index populations, structured analytics operations, clustering, and categorization.
Here are some general guidelines:
- If the Analytics server is used for both indexing and structured analytics, set this value to about 50% of the server's total RAM. You need to leave RAM available for the LSIApp.exe process, which is used for building conceptual indexes.
- If the Analytics server is used solely for structured analytics, set this value to about 85% of the server's total RAM, but leave at least 10 GB of RAM available for the underlying database processes.
- If the Analytics server is used solely for indexing, set this value to about 50% of the server's total RAM. You need to leave RAM available for the LSIApp.exe process, which is used for building conceptual indexes.
- For all configurations, set the Java minimum setting (-Xms) to 12.5% of the total RAM on the server.
Due to a limitation in the Java application, do not configure JVM with a value between 32 GB and 47 GB (inclusive). When JVM is set between 32 GB and 47 GB, the application only has access to 20-22 GB heap space. For example, if the server has 64 GB RAM, set JVM to either 31 GB or 48 GB. This allows the Java application to access all of the allocated RAM.
To modify the Java Heap Size setting, perform the following steps:
-
Navigate to <CAAT install drive>\CAAT\bin.
-
Edit the env.cmd file.
-
Locate the line similar to the following: set HEAP_OPTS=-Xms4096m -Xmx16383m.
The configuration starting with –Xmx refers to the maximum amount of RAM available to Java, in megabytes. In the example, a maximum of 16383 megabytes (16.383 GB) is available.
The configuration starting with –Xms refers to the minimum amount. In the example, a minimum of 4096 megabytes (4.096 GB) is available. -
Modify these values as needed. Both megabyte and gigabyte values are supported for these settings.
-
-
Stop and start the Relativity Analytics Engine (Content Analyst CAAT) service. This allows the changes to take effect.
Note: Never set the Java maximum (-Xmx) to be less than the Java minimum (-Xms).
Page file size
We recommend the following settings regarding the page file size for the Analytics server:
- Set the size of the paging file to 4095 MB or higher. This is because the OS array generally only has enough room for what’s required and is not able to support a page file size of 1.5 times the amount of physical RAM.
- Set the initial minimum and maximum size of settings for the page to the same value to ensure no processing resources are lost to the dynamic resizing of the paging file.
- Ensure that the paging area on a disk is one single, contiguous area, which improves disk seek time.
- For servers with a large amount of RAM installed, set the page file to a size no greater than 50 GB. Microsoft has no specific recommendations about performance gains for page files larger than 50 GB.
Index directory requirements
The index directory stores both the Analytics indexes and the structured analytics sets. Using default settings, the average amount of disk space for the Analytics index or structured analytics set is equal to about 20% of the size of the MDF file of the workspace database. This metric indicates an average amount of disk space usage, but actual indexes may vary considerably in size. The amount of space required depends on the size of the extracted text being indexed, as well as the number of documents, unique words, and settings used to build the index. An Analytics server may not have multiple index locations; it may only reference one disk location for the server’s Analytics indexes and structured analytics sets.
Due to the size requirements, we recommend you don't store indexes on the local drive where the CAAT directory is installed. Upon installation or upgrade, the Analytics Server installer will prompt for the index directory location. If you would like to move the index directory location after upgrade,
CAAT® uses the database software PostgreSQL which requires guaranteed synchronous writes to the index directory. The connection from the analytics server to the index directory should be one that guarantees synchronous writes, such as Fibre Channel or iSCSI, rather than NFS or SMB/CIFS. We recommend storing the indexes and structured analytics sets on locally mounted storage rather than a remotely mounted file system.
CPU requirements
Analytics indexing
The Analytics index creation process also depends on CPU and I/O resources at various stages of the build. Ensuring that your server has multiple processors and fast I/O also increases efficiency during the population build process. Adding more CPU cores to an Analytics server ensures that index populations are as fast as possible—especially for large indexes. When you add additional CPU cores, you may also increase the number of Maximum Connectors used per index on the server.
Structured analytics
The structured analytics features are run by the Java process as well as PostgreSQL. In order for these processes to operate most efficiently, allocate sufficient CPU cores to the Analytics server. For optimal Textual Near Duplicate Identification performance, the Analytics server needs at least 8 CPU cores. Textual Near Duplicate Identification performance improves as additional cores are added.
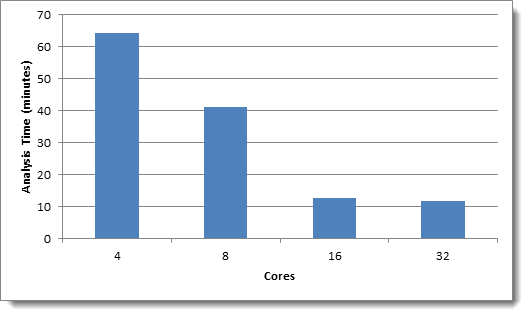
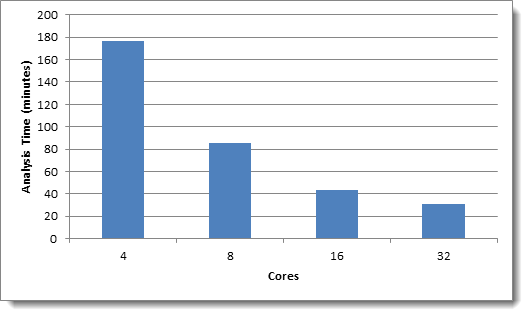
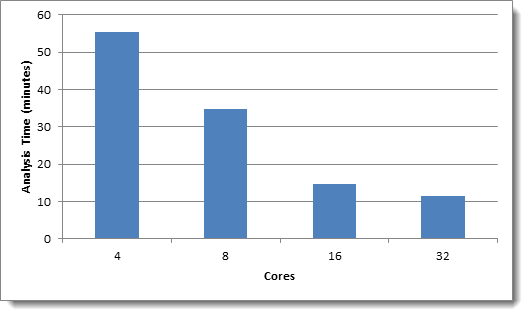
The following charts illustrate the “Running Analytics Operations” step of a Textual Near Duplicate Identification structured analytics set with the default Minimum Similarity Percentage of 90 in CAAT® 3.17:
Data set 1: Enron data – 1M documents, 6.2 GB total text
Data set 2: Wikipedia data - 1M records, 2.4 GB total text
Data set 3: Emails - 768K documents, 11.7 GB total text
The performance of a given data set varies based on certain factors outside of the number of documents or the total text size. The following types of data sets require more time to analyze:
- Data sets with a very high number of similarly-sized documents
- Data sets with a very low number of textually similar documents
Additionally, if you lower the Minimum Similarity Percentage from the default of 90, more time is required to analyze the data set.
Scaling
It is often beneficial to add multiple Analytics servers to the Relativity environment. Jobs can run concurrently without adversely affecting each other. It also allows servers to be dedicated to a feature set (structured or indexing) which makes RAM management easier. The following table shows some example environment configurations as well as the typical upper limitation that will be encountered. The upper limitation assumes no other concurrent activity on the server. The upper limit is intended to serve as an estimate and is not a guarantee. Data sets vary widely, and some may require more server resources than usual.
Tier 1 example
For an entry level environment with 100 to 300 users, usually one Analytics server is enough.
Here is an example environment configuration:
|
Server Name |
Role |
RAM |
JVM |
CPU Cores |
Upper limit - Structured |
Upper limit - Indexing |
|---|---|---|---|---|---|---|
|
ANA-01 |
Both Structured and Indexing |
32 GB |
16 GB |
8 |
3 million documents |
3 million documents |
Tier 2 example
For a mid-level environment with over 300 users, you may need to add an additional server to allow for concurrent jobs. Splitting the server roles also allows the servers to work on more data due to the allocation of Java heap.
Here is an example environment configuration:
|
Server Name |
Role |
RAM |
JVM |
CPU Cores |
Upper limit - Structured |
Upper limit - Conceptual Indexing |
|---|---|---|---|---|---|---|
|
ANA-01 |
Structured |
32 GB |
22 GB |
8 |
4 million documents |
N/A |
|
ANA-02 |
Indexing |
32 GB |
16 GB |
4 |
N/A |
4 million documents |
Tier 3 examples
For a large scale environment, you will likely need to scale up the server and add additional servers. Splitting the server roles allows the servers to work on more data due to the allocation of Java heap. Add more Analytics servers to run more jobs concurrently. However, adding a large amount of RAM to one server will allow a very large job to complete successfully. The balance needs to be determined based on the client needs.
The following are example Tier 3 environment configurations:
Example 1
|
Server Name |
Role |
RAM |
JVM |
CPU Cores |
Upper limit - Structured |
Upper limit - Conceptual Indexing |
|---|---|---|---|---|---|---|
|
ANA-01 |
Structured |
64 GB |
54 GB |
16 |
8 million documents |
N/A |
|
ANA-02 |
Indexing |
64 GB |
31 GB |
12 |
N/A |
7 million documents |
Example 2
|
Server Name |
Role |
RAM |
JVM |
CPU Cores |
Upper limit - Structured |
Upper limit - Conceptual Indexing |
|---|---|---|---|---|---|---|
|
ANA-01 |
Structured |
128 GB |
108 GB |
32 |
16 million documents |
N/A |
|
ANA-02 |
Indexing |
128 GB |
64 GB |
24 |
N/A |
14 million documents |